1-Web基础信息搜集
1、 关于一些与搜索引擎的文件
url / robots.txt{
robots.txt文件内指明哪些路径 允许/不允许 被搜索引擎爬虫抓取
}
url / sitemap.xml{
sitemap.xml文件包含了网站每个路径,是管理员所希望被搜索引擎所爬取的路径
包括一些旧网页和一些不再使用但仍然存在的网页
}
2、 关于一些三方框架信息
favicon{
网站图标(即浏览器页签所展示的图标),一些框架会自带其特有的图标,如果未被更换,即可发现框架线索。
通过icon的MD5散列值
可以在https://wiki.owasp.org/index.php/OWASP_favicon_database上找到对应图标所指代框架
以下两张图为linux与windows获取icon散列值的方式。
}
linux:

windows(win系统需要使用powershell才可):

request与response{
网站通信时的请求与响应中也是常常带有有用信息,如一些服务器版本、三方框架等
这些信息是作为渗透人员必须查看的内容
通常使用浏览器F12打开开发者工具直接进行查看,或者使用burpsuit、fiddler、wireshark等等抓包工具查看。
以下介绍使用curl在命令行进行查看
}
curl url -v:查看详细信息
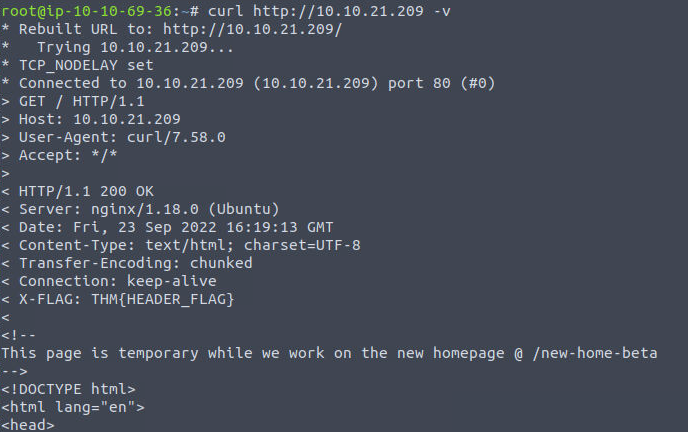
由上图可以看到server:nginx后台服务器版本,并且-v还将html页面源码返回在控制台。
框架默认账号密码:许多第三方框架、第三方建站cms都会设置一个默认的管理员账号密码。
就如kali系统也会内置一个默认的root账户提供使用,在识别到对应框架或者cms的时候,应当去寻找对应的默认账号密码与管理后台尝试登录。
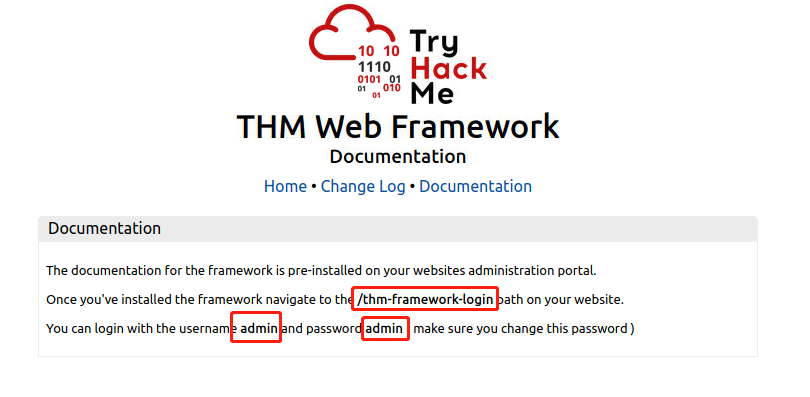
下图为靶场提供的一个虚假框架文档,文档指明了管理员登录路径与账号密码。
3、 搜索引擎的使用
google:
site:abc.com 查找指定域名相关信息
inurl:admin 查找包含admin的url
filetype:pdf 查找包含pdf文件的信息
intitle:admin 查找网页title包含admin的信息
像这样在互联网上搜集信息的引擎还有许多,如fofa等一系列专门用来搜集互联网资产信息的引擎,包括百度也是,其余引擎可自行百度了解。基本都有自己特定的语法。
4、浏览器插件
Wappalyzer:
此插件为识别web站点所使用框架等信息,不做过多解释,可自行百度了解。
5、web站点历史记录
此站点是tryhackme推荐的国外站点,据介绍可以追溯到90年代的历史记录。
国内也有其它站点,这里不做太多介绍,比如我们国家工信网就可以查询一些资产信息,还有企查查等都可以
具体其它查询方法可以直接百度web站点历史记录查询,有大牛们都整理好了。
6、Github信息
有许多程序员、许多公司都是将代码托管到github上做版本管理,可以在github上查询对应信息进行搜集,类似的还有gitlab等网站,遇到有管理不严格未做权限设置的,则在上面是处于公开状态。
7、OSS桶、S3桶
OSS桶是阿里提供的一项云存储服务,国内基本都是使用OSS将web应用的内容存储在oss里面,S3则是国外亚马逊提供的桶服务,在访问桶里面资源的时候,有很多web应用是未设置权限认证的,可以随意访问,这就造成了信息泄露等一系列的漏洞
8、第三方工具
gobuster\ffuf\dirb:
以上三种工具只是靶场内介绍的工具,类似工具在网上有大量免费的
大部分的作用集中在:目录扫描、弱口令爆破、子域名搜集、背后建站信息搜集等等等,基本是无所不能,但是工具之间会有差距,这些需要自己长期积累分辨哪些工具的长处,再对应使用达到最好效果。
以上则是tryhackme中web基本资产搜集的内容,大部分其实都是需要自己去百度了解的,这边做个大概介绍。
咱们下一节课见

 浙公网安备 33010602011771号
浙公网安备 33010602011771号