27.4 Java集合之Map学习
文章目录
1.Map接口
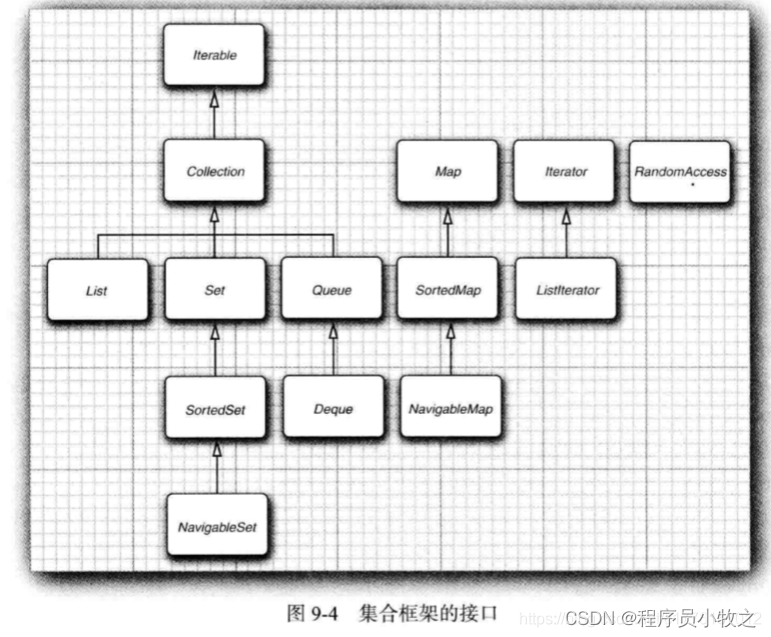
从上图中我们知道Map是个独立的接口,它和Collection是一个层次的,他们之间不存在继承关系,但可能存在组合关系。
Map是用来存储键值对的数据结构。
1.1 Map接口定义

从上面我们可以看到,如果我们想得到包含键值对的集合对Map进行遍历,我们可以对Map.Entry来进行操作。
下面我们就来学习一下Map中对于Entry的定义
1.2 Entry接口
2. Map具体实现

从图中可以看到实现的Map的类有:
HashMap, TreeMap, EnumMap, LinkedHashMap, WeakHashMap, IdentityHashMap 6个, 如果算上AbstractMap,就是7个了。
2.1 AbstractMap
在Jdk中,和Collection体系一样,也提供了抽象类AbstractMap,其中包含了一些可复用的代码,方便在编写具体实现类时不做重复的工作。
我们可以参考它的实现来学习如何去实现一个Map
我们可以看一下其中的一些实现方法
2.1.1 put方法实现
/**
* 向Map中添加一个键值对
**/
public V put(K key, V value) {
throw new UnsupportedOperationException();
}
从这里我们可以看到,AbstractMap中是不提供put方法的实现的,因为它是随着存储原理的不同而不同的。
2.1.2 get方法实现
/**
* 根据key在Map中获取它的value, 提供了基础实现,
* 实现类逻辑很简单,就是先获得Entry的集合的迭代器,然后进行遍历比较key
**/
public V get(Object key) {
Iterator<Entry<K,V>> i = entrySet().iterator();
if (key==null) {
while (i.hasNext()) {
Entry<K,V> e = i.next();
if (e.getKey()==null)
return e.getValue();
}
} else {
while (i.hasNext()) {
Entry<K,V> e = i.next();
if (key.equals(e.getKey()))
return e.getValue();
}
}
return null;
}
从这里我们可以看到,在Map中是允许key为null的数据存储。
2.1.3 size()方法实现
/**
* 这里取得就是Entry的集合的大小
**/
public int size() {
return entrySet().size();
}
public abstract Set<Entry<K,V>> entrySet();
2.1.4 isEmpty方法实现
/**
* 通过判断size()得到的值是否为0
**/
public boolean isEmpty() {
return size() == 0;
}
2.1.5 containsKey方法实现
/**
* 实现类逻辑很简单,就是先获得Entry的集合的迭代器,然后进行遍历比较key
**/
public boolean containsKey(Object key) {
Iterator<Map.Entry<K,V>> i = entrySet().iterator();
if (key==null) {
while (i.hasNext()) {
Entry<K,V> e = i.next();
if (e.getKey()==null)
return true;
}
} else {
while (i.hasNext()) {
Entry<K,V> e = i.next();
if (key.equals(e.getKey()))
return true;
}
}
return false;
}
2.1.6 containsValue方法实现
/**
* 实现类逻辑很简单,就是先获得Entry的集合的迭代器,然后进行遍历比较value
**/
public boolean containsValue(Object value) {
Iterator<Entry<K,V>> i = entrySet().iterator();
if (value==null) {
while (i.hasNext()) {
Entry<K,V> e = i.next();
if (e.getValue()==null)
return true;
}
} else {
while (i.hasNext()) {
Entry<K,V> e = i.next();
if (value.equals(e.getValue()))
return true;
}
}
return false;
}
更多实现大家可以自行查阅源码进行学习。
2.2 HashMap
学习HashMap,首先我们要学习的是数据的存储结构:
通过阅读源码我们知道了,HashMap的存储结构是数组存储,将数据存放到Node类型的数组中
transient Node<K,V>[] table;
//可以知道Node实现了Entry接口
static class Node<K,V> implements Map.Entry<K,V> {
final int hash;
final K key;
V value;
Node<K,V> next;
}
2.2.1 扩容机制
既然是数组存储结构,那么它的扩容机制是我们一定要了解的!!
HashMap的扩容逻辑放在方法resize()中,其逻辑如下:
如果是oldCap=0且oldThr=0,初始化容量为:16,负载因子为:0.75 初始扩容阈值为:16*0.75=12
如果oldCap>0:
如果oldCap>=(1<<30), 将阈值调为2^31-1.,不进行扩容.
如果oldCap<(1<<30), 则newCap = oldCap*2, newThr = oldThr *2
如果oldCap<=0&&oldThr>0
newCap = oldThr
如果oldThr = 0, 计算之: newThr = newCap*loadFactor || MAX_VALUE
然后进行新数组创建,旧数组的数据迁移到新数组中,在这个迁移过程中可能会出现树转链表的操作。
2.2.2 存储原理
对于HashMap的存储原理,我们可以分为两类:
-
不存在hash冲突的存储原理:如果不存在hash冲突,其存储原理是通过Key的(hash值 & 数组长度-1)计算出该Node在Node数组中存储的位置,然后通过newNode方法新建一个Node并存储到指定位置。
-
存在hash冲突的存储原理:首先我们要知道为啥存在冲突了呢? 通过前面的存储原理我们知道元素存储的位置是通过(n - 1) & hash计算出来的,那么 在n-1不变的情况下,不同的Key的hash值和n-1通过与运算可能得到相同的结果,相同的Key的hash值就更不用说了,所以hash冲突发生从情况有两种:
- 使用相同的Key进行put: 对原有位置的value进行覆盖为最新的。
- 使用不同的Key进行put:
如果冲突的个数小于8个,采用链接法进行解决,就是将原有位置上最外层的元素的next指向它,如图:
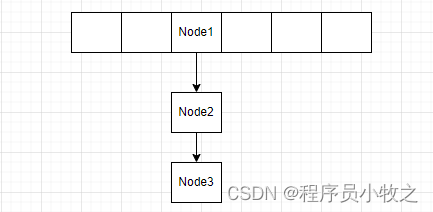
如果冲突的个数大于了8个,如果数组的长度大于或等于了最小树化容量(默认64),则进行树化(链表转为红黑树),否则进行扩容操作。
何时转会链表?
当树的大小小于7的时候,会将树转回链表结构。
为何要转成树结构?
因为长度过长的化链表的检索速度是比较慢的O(n),而树结构则检索比较快O(logn)。
为何树结构用的是红黑树,而不是平衡二叉查找树?
AVL 和RBT 都是二叉查找树的优化。其性能要远远好于二叉查找树。他们之间都有自己的优势,其应用上也有不同。
结构对比: AVL的结构高度平衡,RBT的结构基本平衡。平衡度AVL > RBT.
查找对比: AVL 查找时间复杂度最好,最坏情况都是O(logN)。RBT 查找时间复杂度最好为O(logN),最坏情况下比AVL略差。
插入删除对比:
AVL的插入和删除结点很容易造成树结构的不平衡,而RBT的平衡度要求较低。因此在大量数据插入的情况下,RBT需要通过旋转变色操作来重新达到平衡的频度要小于AVL。
如果需要平衡处理时,RBT比AVL多一种变色操作,而且变色的时间复杂度在O(logN)数量级上。但是由于操作简单,所以在实践中这种变色仍然是非常快速的。
当插入一个结点都引起了树的不平衡,AVL和RBT都最多需要2次旋转操作。但删除一个结点引起不平衡后,AVL最多需要logN 次旋转操作,而RBT最多只需要3次。因此两者插入一个结点的代价差不多,但删除一个结点的代价RBT要低一些。
AVL和RBT的插入删除代价主要还是消耗在查找待操作的结点上。因此时间复杂度基本上都是与O(logN) 成正比的。
总体评价:大量数据实践证明,RBT的总体统计性能要好于平衡二叉树。
2.2.3 性能测试实例
HashMap的存取效率都很高。
//
public static void main(String[] args) {
HashMap<Integer,Integer> map = new HashMap<>();
//测试存储效率
long start = System.currentTimeMillis();
for(int i=0;i<10000000;i++){
map.put(i+ (int) (Math.random() * 100),i);
}
long end1 = System.currentTimeMillis();
System.out.println("存储耗时: "+ (end1-start)+"ms");
for(int i=0;i<10000000;i++){
map.get(i);
}
System.out.println("查询耗时:"+(System.currentTimeMillis()-end1)+"ms");
}
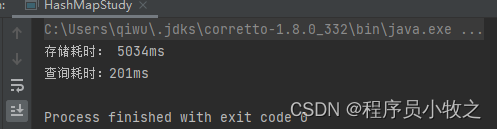
使用HashMap存取1000万的数据耗时在10秒以内,可见其存取效率了。
2.3 TreeMap
2.3.1 存储原理
TreeMap是Map的有序实现,它会根据键的顺序将元素组织为一个搜索树,使用的存储结构是红黑树。
private transient Entry<K,V> root;
static final class Entry<K,V> implements Map.Entry<K,V> {
K key;
V value;
Entry<K,V> left;
Entry<K,V> right;
Entry<K,V> parent;
boolean color = BLACK;
}
关于红黑树,感兴趣的同学可以仔细阅读源码,看看它是如何实现增删改查操作的。
TreeMap默认的存储是根据Key的大小顺序存储的,也就是说遍历的时候是Key有序的遍历。默认是按 key 的升序排序
2.3.2 性能测试实例
//
public static void main(String[] args) {
TreeMap<Integer,Integer> map = new TreeMap<>();
//测试存储效率
long start = System.currentTimeMillis();
for(int i=0;i<10000000;i++){
map.put(i+ (int) (Math.random() * 100),i);
}
long end1 = System.currentTimeMillis();
System.out.println("存储耗时: "+ (end1-start)+"ms");
for(int i=0;i<10000000;i++){
map.get(i);
}
System.out.println("查询耗时:"+(System.currentTimeMillis()-end1)+"ms");
}
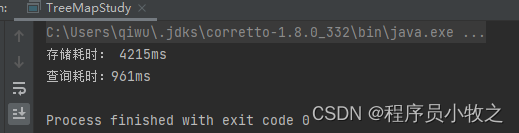
TreeMap在相同条件下的存储性能还要略好于HashMap, 但其查询性能略低于HashMap, 但是它有着HashMap难以实现的特性:它可以实现有序存储。
2.4 EnumMap
2.4.1 存储原理
基于数组实现,但是其中不存在扩容机制。
这个Map实现比较特殊,它的Key只能是枚举类型的, 因为枚举类型的对象自带唯一属性,所以使用它无需考虑冲突问题。
/**
* 从这里可以看出,EnumMap在构造时已经将长度定义好了:
* 就是枚举类中枚举值的数量
**/
public EnumMap(Class<K> keyType) {
this.keyType = keyType;
keyUniverse = getKeyUniverse(keyType);
vals = new Object[keyUniverse.length];
}
public V put(K key, V value) {
typeCheck(key);
int index = key.ordinal();
Object oldValue = vals[index];
vals[index] = maskNull(value);
if (oldValue == null)
size++;
return unmaskNull(oldValue);
}
EnumMap的特性是存取效率极高,但是使用范围有限。
2.4.2 使用实例
public class EnumMapStudy {
public static void main(String[] args) {
EnumMap<TestEnum, String> enumMap = new EnumMap<>(TestEnum.class);
enumMap.put(TestEnum.ONE, "333");
enumMap.put(TestEnum.ONE,"999");
for (Map.Entry<TestEnum, String> entry : enumMap.entrySet()) {
System.out.println(entry.getKey()+":"+entry.getValue());
}
}
}
enum TestEnum{
ONE,TWO, THREE,FOUR,FIVE,SIX,SEVEN,EIGHT,NINE,TEN;
}
2.5 LinkedHashMap
2.5.1 存储原理
LinkedHashMap继承了HashMap实现,是对HashMap的一种增强:
它会记住插入元素的顺序,这样在使用迭代器进行遍历的时候,遍历元素则是有序的。
LinkedHashMap通过重写newNode方法,让其在新创建Node的时候将其插入顺序通过双向链表结构记录下来。
transient LinkedHashMap.Entry<K,V> head;
transient LinkedHashMap.Entry<K,V> tail;
注意:它和TreeMap的差别。
2.5.2 性能测试实例
public static void main(String[] args) {
LinkedHashMap<Integer,Integer> map = new LinkedHashMap<>();
//测试存储效率
long start = System.currentTimeMillis();
for(int i=0;i<10000000;i++){
map.put(i+ (int) (Math.random() * 100),i);
}
long end1 = System.currentTimeMillis();
System.out.println("存储耗时: "+ (end1-start)+"ms");
for(int i=0;i<10000000;i++){
map.get(i);
}
System.out.println("查询耗时:"+(System.currentTimeMillis()-end1)+"ms");
}
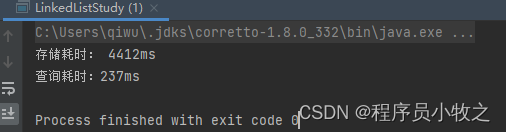
由于它继承了HashMap,所以它在性能上和HashMap差不多,但是在能力上,它具有记忆键值对插入顺序的能力。
2.6 WeakHashMap
简单来说这个Map实现能有效的节省空间,当使用它存储键值对的时候,当值没有地方用它的时候可以被垃圾回收器回收从而提高空间利用率。
2.6.1 存储原理
通过阅读源码我们可以知道:
Entry<K,V>[] table;
WeakHashMap的存储方式是通过数组实现的,存储计算逻辑和HashMap类似,通过计算Key的hash,然后和数组最大索引值进行按位与运算,获得存储位置。
2.6.2 WeakHashMap特性
在WeakHashMap中,Key键是一个弱引用的键,如果Key键被回收,则在get该map中值后,会自动remove掉value
如果Key键始终被强引用,则是无法被回收的;
注意Value是被强引用的,所以不要让Value间接的引用了Key键,这将导致key时钟被强引用
适合于受Key的生命周期控制的缓存
2.6.3 使用实例
public static void main(String[] args) throws InterruptedException {
WeakHashMap<Integer,Integer> map = new WeakHashMap<>();
for(int i=0;i<1000;i++){
map.put(i,i);
}
System.out.println(map.size());
}
2.7 IdentityHashMap
此Map实现“允许” 相同的Key存入, 原因是进行重复性检查用的是== 而不是equals, 这就使得如果Key是复杂引用类型,那么会出现存储相同的键值对的情况。
2.7.1 存储原理
transient Object[] table;
通过查阅源码,发现的存储结构也是数组。
不过它的数据结构不用Entry了哦,而是直接时Object了哦,这和其他的Map实现不同了。
所以就去看了put方法的实现,果然,看出了不一样的地方:
tab[i] = k;
tab[i + 1] = value;
从这里可以看到,IdentityHashMap虽然用的数组存储,但是它的key和value时挨在一起存储的。
具体的实现还需查阅源码。
2.7.2 使用实例
public static void main(String[] args) {
IdentityHashMap<Integer,Integer> map = new IdentityHashMap<>();
for(int i=0;i<10;i++){
map.put(new Integer(i),i);
}
for(int i=0;i<10;i++){
map.put(i,i);
}
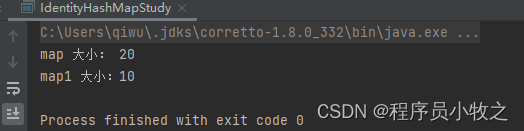
System.out.println("map 大小: "+map.size());
IdentityHashMap<Integer,Integer> map1 = new IdentityHashMap<>();
for(int i=0;i<10;i++){
map1.put(i,i);
}
for(int i=0;i<10;i++){
map1.put(i,i);
}
System.out.println("map1 大小:"+map1.size());
}
代码地址:
Java基础学习/src/main/java/Progress/exa27_4 · 严家豆/Study - 码云 - 开源中国 (gitee.com)
作者:small-water
出处:https://www.cnblogs.com/small-water/p/17870005.html
版权:本作品采用「署名-非商业性使用-相同方式共享 4.0 国际」许可协议进行许可。



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 单元测试从入门到精通
· winform 绘制太阳,地球,月球 运作规律
· 上周热点回顾(3.3-3.9)