

基于Redis做内存管理
1 Redis存储机制:
redis存储的数据类型包括,String,Hash,List,Set,Sorted Set,它内部使用一个redisObject对象来表示所有的key和value,这个对象基本结构见下:
typedef struct redisObject {
unsigned type, // 4字节,数据类型
unsigned encoding, // 4字节,编码方式
unsigned lru, // 24字节,置换算法
int refcount, // 对象引用计数
void *ptr // 数据具体存储的指向
} robj;
type代表一个value对象具体是何种数据类型,encoding是不同数据类型在redis内部的存储方式,这么表示主要是为了给Redis不同数据类型提供一个统一的管理接口。
String是最常用的一种类型,是最普通的key/value的hash存储,读写的时间复杂度都是O(1)。
Hash存储会在基本kv的hash里再创建一层hash,两层hash结构,取值时可以直接通过ID+key的方式取到value,读写的时间复杂度都是O(1)。
List存储的是一个双向链表,即可以支持反向查找和遍历,查询插入一个数据的时间复杂度为O(n),如果是在最后添加或弹出则为O(1)。
Set存储的是一个自动去重的List,内部实现Set存储的是一个值为null的map,所以Set支持直接判定值的存在性,Set读写的时间复杂度都是O(1)。
Sorted Set存储的是按用户的指定的分数排序的Set,Sorted Set存储采用了一个跳表,和一个hash,跳表存储了所有数据,hash存储数据和分数的关系。Sorted Set读写主要是从跳表中查询数据或位置的复杂度,为O(log(n))。
8.2 Redis内存管理机制:
内存控制:
Redis通过控制内存上限和回收策略实现内存管理,使用maxmemory参数限制最大可用内存,比如我们的nfvo就是设置的512mb,代表我们最大不能存储超过512mb的数据。
对于过期的数据,redis有两种方式释放内存,一个是惰性删除,在下次查询某key的时候先检查超时时间,如果已超时则删除数据并返回空;另一个是定时任务,默认每10秒一次(可以同hz参数配置,我们使用的默认配置10),检查超时时间,超时则删除。
对于溢出的数据,有几种处理方式,可通过maxmemory-policy配置。
1、noeviction,不删除,拒绝新插入的消息。
2、volatile-lru,根据LRU(最近最少使用)置换算法,对于配置了超时时间的数据进行清理,这个也是我们目前配置的清理策略,巴展时期经常出现数据丢失的情况就是由于这个策略的存在,所以在使用时因小心。
3、allkeys-lru,根据LRU(最近最少使用)置换算法,对于所有数据进行清理,直到内存满足需要。
4、allkeys-random,随机删除所有key,直到满足内存需要。
5、volatile-random,随机删除配置了超时时间的key,直到满足内存需要。
6、volatile-ttl,根据键对象的生存时间属性,删除最近将要过期的数据。
当客户端执行一条新命令,导致数据库需要增加数据(比如set key value),Redis会检查内存使用,如果内存使用超过maxmemory,就会按照置换策略删除一些key来给新数据准备存储区。
Redis还会通过对大小数据的不同处理来节约内存,比如上面提到的redis的几个类型,list,set,map,在数据量小的时候Redis会采用线性紧凑存储来节省空间,数据量多大这个是可配置的:
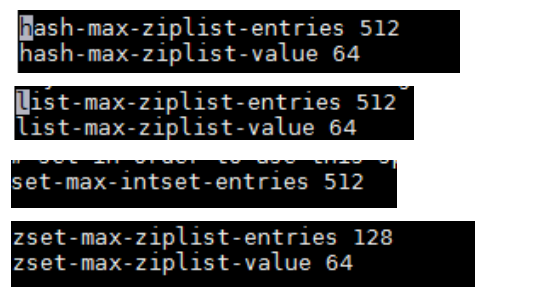
entries含义是当value这个Map内部不超过多少个成员时会采用线性紧凑格式存储,默认是64,value含义是当value这个Map内部的每个成员值长度不超过多少字节就会采用线性紧凑存储来节省空间,这个值不能无限扩大,因为线性存储意味着线性查找,数据少是效率没问题,数据量大的时候如果采用这种方式会降低查询效率。
8.3 Redis持久化机制:
Redis一共支持四种持久化方式,分别是:定时快照方式(snapshot),基于语句追加文件的方式(aof),虚拟内存(vm),Diskstore方式。主要使用的是前两种,vm方式甚至已经被废弃掉了,而Diskstore也只是在实验阶段,也就是说,Redis目前还是作为内存数据库使用,数据量不允许很大。
定时快照方式实际是在 Redis 内部一个定时器事件,每隔固定时间去检查当前数据发生的改变次数与时间是否满足配置的持久化触发的条件,如果满足则通过操作系统 fork 调用来创建出一个子进程,这个子进程默认会与父进程共享相同的地址空间,这时就可以通过子进程来遍历整个内存来进行存储操作,而主进程则仍然可以提供服务,当有写入时由操作系统按照内存页(page)为单位来进行copy-on-write保证父子进程之间不会互相影响。该持久化的主要缺点是定时快照只是代表一段时间内的内存映像,所以系统重启会丢失上次快照与重启之间所有的数据。定时快照方式根据redis.conf中配置的save的时间间隔去检查当前数据改变次数和时间是否满足配置,如果满足则从父进程fork(copy-on-write机制)出一个子进程,通过该子进程遍历内存来转换成rdb文件,在redis.conf里见下:
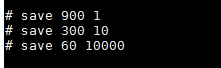
分别代表900秒内1个key变化,300秒内10个key,60秒内10000个key触发,由于我们的nfvo和vnfm由于每次都会清理Redis,并未用到其持久化机制,所以配置被注掉了。
aof方式每条会使Redis内存数据发生改变的命令都会追加到一个log文件中,也就是说这个log文件就是Redis的持久化数据,aof的方式的主要缺点是追加log文件可能导致体积过大,当系统重启恢复数据时如果是aof的方式则加载数据会非常慢,因为读取的所有命令都要在内存中执行一遍。另外由于每条命令都要写log,所以使用aof的方式,Redis的读写性能也会有所下降。aof有三种模式调用fsync写入磁盘,fsync函数可以同步内存中所有已修改的文件数据到储存设备,1、总是写入,即每次有变更都调用fsync写入;2、每秒调用fsync写入一次;3、不主动调用fsync同步数据到磁盘,而是依赖os的定时fsync写入,一般为30秒,不推荐。aof方式在redis.conf内配置见下:

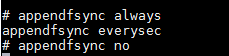
appendonly代表是否开启AOF,我们并未开启,appendfilename是文件名,appendfsync是写入模式。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号