

服务发现
1、服务发现
在服务很多的情况,尤其现在docker出现,业界都发起服务化的热潮,几十几百个服务再正常不过,如果使用预定义端口,则很容易发生冲突,而自动分配端口则会避免这一问题,但是自动分配端口如何让别人知道,这就是服务发现需要做的事。
通常,一个服务发现系统主要由三部分组成:
注册器(registrator):根据服务运行状态,注册/注销服务。主要要解决的问题是,何时发起注册/注销动作。
注册表(registry):存储服务信息。常见的解决方案有zookeeper、etcd、cousul等。
发现机制(discovery):从注册表读取服务信息,给用户封装访问接口。
当我们部署了服务,就需要通知服务发现组件更新注册表中存储其信息,大多数的服务发现组件都需要配置服务发现框架的地址。接着,当消费者试图访问服务提供者时,它首先查询服务注册表,使用获取到的IP地址和端口来调用该服务。为了与注册表中的服务提供方的具体实现解耦,我们常常采用某种代理服务。这样消费者总是向固定IP地址的代理请求信息,代理再依次使用服务发现来查找服务提供方信息并重定向请求。ZooKeeper和etcd有watcher机制,一旦监听者监听某路径,则注册信息会在更新时通知监听者,这样监听者就能实时获取服务信息。
服务发现还需要保证整个系统的健壮性,保证其中一个节点的宕机不会危及数据,同时,每个节点应该有完全相同的数据副本,进一步地,我们希望能够以任何顺序启动服务、杀死服务或者替换服务的新版本,我们还应该能够重新配置服务并且查看到数据相应的变化。比如ZooKeeper有心跳保活机制,etcd依靠Registrator组件监控服务状态,而consul则有自己的健康状态检查。
下面是一个etcd服务发现的实现架构简图:
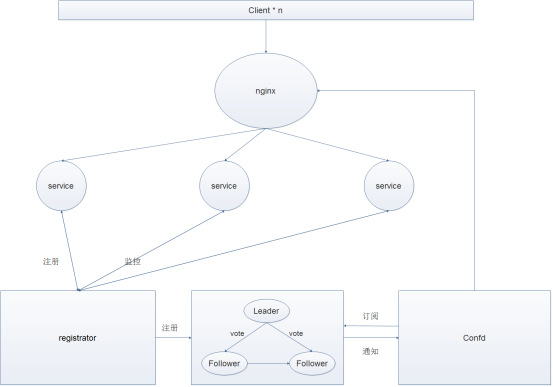
2、服务发现框架
目前业界最普遍的几个服务发现框架是ZooKeeper,etcd和consul,他们能力非常类似,但是又有很大不同,每个组件的侧重点不同,实际使用时需要根据其特点和自身需要进行选型。
三者的存储方式基本一致,都是采用树形的key/value存储;他们都有多个服务节点,通过选举完成主从分配;他们都是强一致性的。但是他们也有自己不同的特点:
ZooKeeper:
ZooKeeper相比于etcd和consul更加庞大,功能也更多,也正是因为如此,ZooKeeper也更重更臃肿,服务发现只是它一部分功能;
ZooKeeper采用的是paxos算法,相比与raft算法,paxos更复杂;
ZooKeeper提供RPC接口;
客户端需要与ZooKeeper建立保活机制;
ZooKeeper没有健康检查机制;
etcd:
etcd单独存在一般是作为kv存储系统,想要完成服务发现,一般会配类似Registrator、confd等组件;
etcd采用raft算法,更加容易理解;
etcd提供rest接口(v3也改为支持rpc);
etcd没有健康检查机制;
Consul:
Consul应该说是专注于服务发现,它内嵌实现了服务发现系统而且内置了服务发现的框架,它只要加入集群中任意一个现存的成员,当加入一个现存的成员后,会通过成员间的通讯很快发现集群中的其它成员;
Consul也采用raft算法;
Consul支持rest和DNS服务;
Consul有健康检查机制;
Consul支持多数据中心;
从上面的对比可以看出来,针对服务发现,Consul更简单,也更合理,因为它专注于完成服务发现,还支持健康检查,还有前两者不支持多数据中心,明显是搭建服务发现的更优选择,但是Consul没有ZooKeeper和etcd的watcher机制,每次都从consul agent获取其他服务的存活状态,所以在实时性上稍差。
3、etcd
Etcd是一个分布式的,强一致的key-value存储,主要用途是共享配置和服务发现。它支持支持服务注册与发现,支持WATCH接口,支持HTTP协议,它主要包含以下几部分。
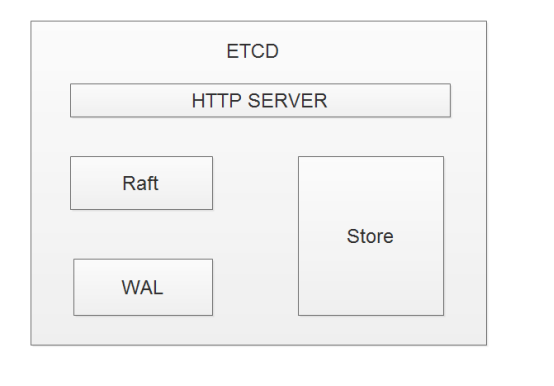
HTTP Server用于处理用户发送的API请求以及其它etcd节点的同步与心跳信息请求。
Store用于处理etcd支持的各类功能的事务,包括数据索引、节点状态变更、监控与反馈、事件处理与执行等等,是etcd对用户提供的大多数API功能的具体实现。
Raft是强一致性算法的具体实现,是etcd的核心。
WAL(Write Ahead Log预写式日志),是etcd的数据存储方式。除了在内存中存有所有数据的状态以及节点的索引以外,etcd就通过WAL进行持久化存储。
etcd的一致性是如何实现的呢?主要依靠的是raft算法,raft包含三种角色:Leader, Follower, Candidate。
选主与一致性:
初始状态下,大家都是平等的follower,每个follower内部都维护了一个随机的timer,在timer时间到了的时候未收到投票或leader的心跳,它的角色转换为candidate,同时广播参与竞选,在candidate期间如果收到其他candidate的投票请求,则投票给它,只能投票给第一个,后面的不会再投票,如果某个candidate获得超过半数的投票,则成为leader,其他的成员自动成为follower,成为leader的成员向各follower建立心跳,之后一段时间,这个小组就由其带领了,如果未超半数,则重新发起竞选。所以一般etcd集群至少需要三个成员,扩大成员数量时最好保证奇数个成员。
选出leader后,就可以开始提供服务了。leader是通信入口,数据同步的发起者;follower被动的接受来自leader的数据请求;candidate:只存在于leader的选举阶段,某个节点想要变成leader,那么就发起投票请求,同时自己变成candidate。如果选举成功,则变为leader,否则退回为follower。如果超过半数的follower都成功写了log,leader正式写入数据,然后在下一次心跳广播给follower,follower收到消息再持久化数据。
为了避免在一个节点宕机一段时间后再被选为主节点,而导致数据错误,raft要求选为主的节点必须包含所有的最新的提交,数据不全的无法被选为leader,因为已经提交的日志必然被集群中超过半数节点持久化,显然前一个主节点提交的最后一条日志也被集群中大部分节点持久化,所以不存在选不到主的情况,这样选出来的主节点再将数据同步给follower,但是如果由于网络而导致的集群分裂,网络恢复后只能以一个集群的主为依据,不可避免的会有部分数据丢失。
如下这个网址有更详细的说明,是以动图的方式展示的,十分容易理解:
raft算法动图网址:http://thesecretlivesofdata.com/raft/
watcher机制:
Etcd v2和v3本质上是共享同一套raft协议代码的两个独立的应用,接口不一样,存储不一样,数据互相隔离,watcher机制也有区别。
v2版本时,etcd的store中有一个全局的currentIndex,每次变更,index会加1。然后每个event都会关联到currentIndex。当客户端调用watch接口时,如果请求参数中有waitIndex,并且waitIndex小于 currentIndex,则从EventHistroy表中查询index小于等于waitIndex,并且和watch key匹配的event,如果有数据,则直接返回。如果历史表中没有或者请求没有带waitIndex,则放入WatchHub中,每个key会关联一个watcher列表。当有变更操作时,变更生成的event会放入EventHistroy表中,同时通知和该key相关的watcher。EventHistroy是有长度限制的,最长1000。也就是说,如果你的客户端停了许久,然后重新watch的时候,可能和该waitIndex相关的event已经被淘汰了,这种情况下会丢失变更。如果通知watch的时候,出现了阻塞(每个watch的channel有100个缓冲空间),Etcd会直接把watcher删除,也就是会导致wait请求的连接中断,客户端需要重新连接。很难通过watch机制来实现完整的数据同步(有丢失变更的风险),所以当前的大多数使用方式是通过watch得知变更,然后通过get重新获取数据,并不完全依赖于watch的变更event。
v3 store分为两部分,一部分是内存中的索引,kvindex,另外一部分是后端存储。backend可以对接多种存储,当前使用的boltdb。boltdb是一个单机的支持事务的kv存储,Etcd的事务是基于boltdb的事务实现的。Etcd在boltdb中存储的key是reversion,value是Etcd自己的key-value组合,也就是说Etcd会在boltdb中把每个版本都保存下,从而实现了多版本机制。当用etcdctl通过批量接口写入两条记录:
put key1 "v1"
put key2 "v2"
再通过批量接口更新这两条记录:
put key1 "v12"
put key2 "v22" '
boltdb中其实有了4条数据:
rev={1 0}, key=key1, value="v1"
rev={1 1}, key=key2, value="v2"
rev={2 0}, key=key1, value="v12"
rev={2 1}, key=key2, value="v22"
reversion主要由两部分组成,第一部分main rev,每次事务进行加一,第二部分sub rev,同一个事务中的每次操作加一, Etcd 的内存kvindex保存的就是key和reversion之前的映射关系。
Etcd v3的watch机制支持watch某个固定的key,也支持watch一个范围,同时每个 WatchableStore包含两种watcherGroup,一种是synced,一种是unsynced,当 Etcd 收到客户端的watch请求,如果请求携带了revision参数,则比较请求的revision和store当前的revision,如果大于当前revision,则放入synced组中,否则放入unsynced组。同时 Etcd 会启动一个后台的任务持续同步unsynced的watcher,然后将其迁移到synced组。所以Etcd v3 支持从任意版本开始watch。另外Etcd v3专门维护了一个推送时阻塞的watcher队列,以便后续重试。可以看到Etcd v3的watch机制更稳定,基本上可以通过watch机制实现数据的完全同步。
4、ZooKeeper
ZooKeeper是一个高可用的分布式数据管理与协调框架,基于paxos算法实现的,分布式应用程序可以基于 ZooKeeper 实现诸如数据发布/订阅、负载均衡、命名服务、分布式协调/通知、集群管理、Master 选举、配置维护,名字服务、分布式同步、分布式锁和分布式队列等功能。
可以看到ZooKeeper功能比etcd更丰富,更庞大。
ZooKeeper同样有竞选流程,但是算法和etcd不一致。
ZooKeeper支持心跳机制,客户端启动时,首先会与服务器建立一个TCP连接,从第一次连接建立开始,客户端会话的生命周期也开始了,通过这个连接,客户端能够 通过心跳检测和服务器保持有效的会话,也能够向 ZooKeeper 服务器发送请求并接受响应,同时还能通过该连接接收来自服务器的 Watch 事件通知。
ZooKeeper也是树形存储,它包含持久化节点和临时节点,主要区别在链路中断后是否删除。
关于ZooKeeper我们使用的主要的功能和etcd类似,这里以etcd为主进行了简单说明,ZooKeeper就不写了。
5、Consul
下图是Consul的典型架构:
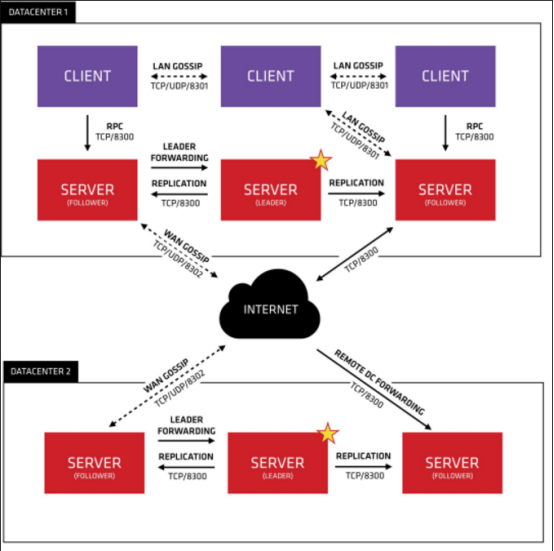
从上面的架构图可以看出,多个运行了Consul Agent的节点组成了一个Consul Cluster,这些agent有的运行server,有的运行client,client与server通过rpc通信,节点之间通过raft算法实现选举与一致性,一个Consul Cluster存在于一个数据中心,多个数据中心组成完整架构,多个数据中心间通过internet基于gossip protocol协议来通讯,在一个有界网络中,每个节点都随机地与其他节点通信,经过一番杂乱无章的通信,最终所有节点的状态都会达成一致,即使有的节点因宕机而重启,有新节点加入,但经过一段时间后,这些节点的状态也会与其他节点达成一致,也就是说,gossip天然具有分布式容错的优点,更进一步,gossip是一个最终一致性算法,因为gossip不要求节点知道所有其他节点,因此又具有去中心化的特点,节点之间完全对等,不需要任何的中心节点。
消费者总是向固定IP地址的代理请求信息,代理再依次使用服务发现来查找服务提供方信息并重定向请求。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号