
openstack基础架构
申明:本文主要观点引用自cloudman:http://blog.51cto.com/cloudman,感谢cloudman的分享。
OpenStack主要是通过Nova,Neutron,Glance,Cinder,Keystone,Horizon等模块对计算、网络和存储资源进行管理的.
Nova:管理VM的生命周期,是OpenStack中最核心的服务。
Neutron:为OpenStack提供网络连接服务,为VM提供虚拟网络和物理网络连接。
Glance:管理VM的启动镜像,Nova创建VM时将使用Glance提供的镜像。
Cinder:为VM提供块存储服务。
Glance可以将镜像存放在Swift中;Cinder也可以将Volume备份到Swift中。
Keystone:为OpenStack的各种服务提供认证和权限管理服务。
Horizon:为OpenStack用户提供一个Web的自服务Portal。
OpenStack本身是一个分布式系统,不但各个服务可以分布部署,服务中的组件也可以分布部署。这种分布式特性让OpenStack具备极大的灵活性、伸缩性和高可用性。控制节点(Controller Node)管理OpenStack,其上运行的服务有Keystone、Glance、Horizon以及Nova和Neutron中管理相关的组件。控制节点也运行支持OpenStack的服务,例如SQL数据库(通常是MySQL)、消息队列(通常是RabbitMQ)和网络时间服务NTP。网络节点(Network Node)其上运行的服务为Neutron。为OpenStack提供L2和L3网络。包括虚拟机网络、DHCP、路由、NAT等。 存储节点(Storage Node)提供块存储(Cinder)或对象存储(Swift)服务。计算节点(Compute Node)其上运行Hypervisor(默认使用KVM)。同时运行Neutron服务的agent,为虚拟机提供网络支持。
Keystone
Keystone主要负责:1)管理用户及其权限;2)维护 OpenStack Services 的 Endpoint;3)Authentication(认证)和 Authorization(鉴权)。
Keystone中有如下基本概念:
User指代任何使用OpenStack的实体,可以是真正的用户,其他系统或者服务;
Credentials是User用来证明自己身份的信息,可以是:1.用户名/密码;2.Token;3.API Key;4.其他高级方式;
Authentication是Keystone验证User身份的过程,User访问OpenStack时向Keystone提交用户名和密码形式的Credentials,Keystone验证通过后会给User签发一个Token作为后续访问的Credential;
Token是由数字和字母组成的字符串,User成功Authentication后由Keystone分配给User。Token用做访问Service的Credential,Service会通过Keystone验证Token的有效性,Token的有效期默认是24小时;
Project用于将OpenStack的资源(计算、存储和网络)进行分组和隔离,资源的所有权是属于Project的,每个User(包括admin)必须挂在Project里才能访问该Project的资源,一个User可以属于多个Project;
Endpoint是一个网络上可访问的地址,通常是一个URL。Service通过Endpoint暴露自己的API。Keystone负责管理和维护每个Service的Endpoint。
安全包含两部分:Authentication(认证)和Authorization(鉴权)Authentication解决的是“你是谁?”的问题Authorization解决的是“你能干什么?”的问题,Keystone是借助Role来实现Authorization的。
客户想查询某种数据,首先需要向Keystone认证,认证通过后,再获取该用户的权限,然后获取对应服务的Endpoint,通过该Endpoint访问服务,发向服务的请求,服务会先向Keystone进行身份验证,然后查看用户是否有使用这项服务的权限,校验完成,返回结果。
下面是创建一个虚机的流程:
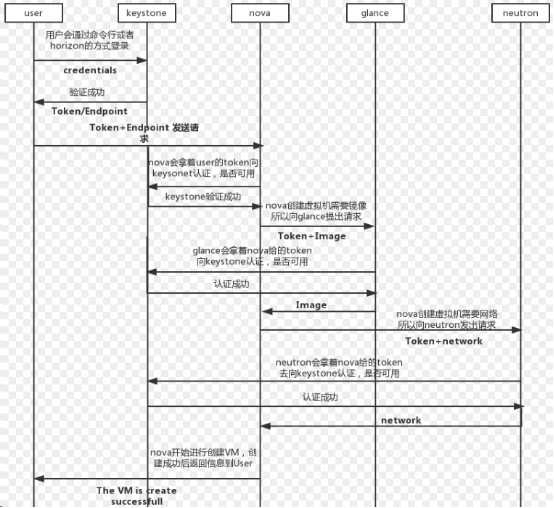
可以看出来keystone在各个组件间扮演着一个中间人的作用,每个服务于服务间使用或者某个用户与服务间的使用,都要先到keystone这里来认证。
Glance
Glance是一种提供发现,注册,和下载的镜像服务,也是一个提供虚拟机镜像的集中式仓库。通过Glance的Restful API,可以查询镜像元数据下载镜像,虚拟机的镜像可以很方便的存储在各种地方。它通过提供一个虚拟磁盘映像目录和存储库,为Nova的虚拟机提供镜像服务。
Glance有以下几个组件:
glance-api:glance-api是系统后台运行的服务进程。对外提供RESTAPI,响应image查询、获取和存储的调用。glance-api不会真正处理请求。如果是与imagemetadata(元数据)相关的操作,glance-api会把请求转发给glance-registry;如果是与image自身存取相关的操作,glance-api会把请求转发给该image的store backend。
glance-registry:glance-registry是系统后台运行的服务进程。负责处理和存取image的metadata,例如image的大小和类型。
Database:存储镜像元数据,Image的metadata会保持到database中,默认是MySQL。
Store backend:Glance自己并不存储image。真正的image是存放在backend中的。
Nova
Compute Service Nova 是OpenStack最核心的服务,负责维护和管理云环境的计算资源。OpenStack作为IaaS的云操作系统,虚拟机生命周期管理也就是通过Nova来实现的。Nova处于Openstak架构的中心,其他组件都为Nova提供支持:Glance为VM提供image;Cinder和Swift分别为VM提供块存储和对象存储;Neutron为VM提供网络连接。
1、组件
Nova的架构比较复杂,包含很多组件:
nova-api:接收和响应客户的API调用;
nova-scheduler:虚机调度服务,负责决定在哪个计算节点上运行虚机;
nova-compute:管理虚机的核心服务,通过调用Hypervisor API实现虚机生命周期管理;
nova-conductor:nova-compute经常需要更新数据库,比如更新虚机的状态,出于安全性和伸缩性的考虑,nova-compute并不会直接访问数据库,而是将这个任务委托给nova-conductor;
nova-console:用户可以通过多种方式访问虚机的控制台:nova-novncproxy,基于Web浏览器的VNC访问、nova-spicehtml5proxy,基于HTML5浏览器的SPICE访问、nova-xvpnvncproxy,基于Java客户端的VNC访问;
nova-consoleauth:负责对访问虚机控制台请求提供Token认证;
nova-cert:提供x509证书支持;
Database:Nova有一些数据要存放到数据库中,一般使用MySQL,数据库安装在控制节点上。
Message Queue:Nova包含众多的子服务,这些子服务之间需要相互协调和通信,为解耦各个子服务,Nova通过Message Queue作为子服务的信息中转站,OpenStack默认是用RabbitMQ作为Message Queue。
OpenStack是一个分布式系统,可以部署到若干节点上,对于Nova,这些服务会部署在两类节点上:计算节点和控制节点,计算节点上安装了Hypervisor,上面运行虚拟机,所以nova-compute需要放在计算节点上,其他子服务放在控制节点上的,控制节点上也可以运行了nova-compute,也就意味着控制节点也可以作为一个计算节点。
1、nova-scheduler
Filter scheduler是nova-scheduler默认的调度器,先通过过滤器(filter)选择满足条件的计算节点(运行nova-compute),然后通过权重计算(weighting)选择在最优(权重值最大)的计算节点上创建Instance,同时openstack允许使用第三方scheduler。
Filter:
Scheduler可以使用多个filter依次进行过滤,过滤之后的节点再通过计算权重选出最适合的节点,常用的filter有:
RetryFilter:刷掉之前已经调度过的节点;
AvailabilityZoneFilter:可用域过滤,过滤掉不属于指定AvailabilityZone的计算节点;
RamFilter:将不能满足 flavor 内存需求的计算节点过滤掉;
DiskFilter:将不能满足 flavor 磁盘需求的计算节点过滤掉;
CoreFilter:将不能满足 flavor vCPU 需求的计算节点过滤掉;
ComputeFilter:保证只有 nova-compute 服务正常工作的计算节点才能够被 nova-scheduler调度;
ServerGroupAntiAffinityFilter:尽量将 Instance 分散部署到不同的节点上;
ServerGroupAffinityFilter:尽量将 instance 部署到同一个计算节点上;
Filter可以在Nova.conf配置文件中配置。
Weight:
经过前面一堆filter的过滤,nova-scheduler选出了能够部署instance的计算节点,Scheduler会对每个计算节点打分,得分最高的获胜,目前nova-scheduler的默认实现是根据计算节点空闲的内存量计算权重值:空闲内存越多,权重越大。
2、nova-compute
nova-compute在计算节点上运行,负责管理节点上的instance;OpenStack对instance的操作,最后都是交给nova-compute来完成的;nova-compute与Hypervisor一起实现OpenStack对instance生命周期的管理。
nova-compute通过Driver架构支持多种Hypervisor,nova-compute为这些Hypervisor定义了统一的接口,Hypervisor只需要实现这些接口,就可以Driver的形式即插即用到OpenStack系统中,单个计算节点上只会运行一种 Hypervisor。
nova-compute的功能可以分为两类:定时向OpenStack报告计算节点的状态;实现instance生命周期的管理。每隔一段时间,nova-compute就会报告当前计算节点的资源使用情况和nova-compute服务状态,nova-compute可以通过Hypervisor的driver拿到计算节点的资源信息。
生命周期的管理包括instance的launch、shutdown、reboot、suspend、resume、terminate、resize、migration、snapshot等,以launch为例,nova-compute首先会根据指定的flavor依次为instance分配内存、磁盘空间、vCPU和网络资源,资源准备好之后,nova-compute会为instance创建镜像文件,首先将image从glance下载到计算节点,通过qemu-img转换成raw格式,然后将其作为backing file通过qemu-img命令创建instance的镜像文件,镜像文件指的是instance启动盘所对应的文件,image不会变,而镜像文件会发生变化,然后创建instance的XML定义文件,虚拟网络设备,最后启动实例。
从组件协作方面,用户向API(nova-api)发送请求:“帮我创建一个Instance”;API对请求做一些必要处理后,向Messaging(RabbitMQ)发送了一条消息:“让Scheduler创建一个Instance”;Scheduler(nova-scheduler)从Messaging获取到API发给它的消息,然后执行调度算法,从若干计算节点中选出节点A;Scheduler向Messaging发送了一条消息:“在计算节点A上创建这个Instance”;计算节点A的Compute(nova-compute)从Messaging中获取到Scheduler发给它的消息,然后通过本节点的Hypervisor Driver创建Instance;在Instance创建的过程中,Compute如果需要查询或更新数据库信息,会通过Messaging向Conductor(nova-conductor)发送消息,Conductor负责数据库访问。
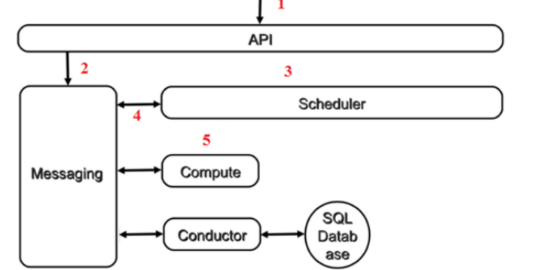
其他几种生命周期操作需要申请资源的就会走scheduler,否则不需要经过scheduler,直接交由nova-compute处理。
其他几种生命周期操作:soft reboot只是重启操作系统,不需要调度;hard reboot是重启instance,相当于关机之后再开机,不需要调度;终止实例是删除指定的实例,镜像文件,网络资源等,不需要调度;Pause是将实例状态保存到内存,短时间停止实例,不需要调度;Resume是从内存中读回instance的状态,然后继续运行instance,不需要调度;Suspend操作将instance的状态保存到宿主机的磁盘上,不需要调度;Snapshot,是对instance的镜像文件(系统盘)进行全量备份,生成一个类型为snapshot的image,然后将其保存到Glance上,不需要调度;Rebuild会用snapshot替换instance当前的镜像文件,同时保持instance的其他诸如网络,资源分配属性不变,不需要调度;Shelve会将instance作为image保存到Glance中,然后在宿主机上删除该instance,不需要调度;unshelve的过程其实就是通过该image launch一个新的instance,nova-scheduler也会选择合适的计算节点来创建该instance,需要调度;migrate会将原节点的实例停止,镜像文件上传到目的节点,然后在新节点启动instance,需要调度;Resize和migrate类似,只是在启动新instance时采用不同的flavor,需要调度;Live Migrate先将instance的数据迁移过来,主要包括镜像文件、虚拟网络等资源,源节点暂定instance,目标节点Resume instance,再将原节instance删除,Instance在Live Migrate的整个过程中不会停机,需要调度。
Cinder
操作系统获得存储空间的两种方式,一为通过某种协议(SAC,SCCI,SAN,ISCSI等)挂接裸硬盘,然后分区、格式化,创建文件系统,这叫做块存储;二是通过NFS、CIFS等协议mount远程文件系统。
Openstack的Cinder提供Block Storage Service来管理volume的生命周期,主要包括:1)提供RESTAPI来管理volume。2)提供scheduler调用volume。3)通过driver架构支持多种backend,如LVM,NFS,Ceph等。
Cinder包含几个组件:1)cinder-api,接受用户的api请求,调用cinder volume。2)cinder-volume,管理volume的生命周期。3)cinder-scheduler,通过调度算法选择最合适的存储节点创建volume。4)volume provider,存储设备,为volume提供物理存储空间。5)RabbitMQ,Cinder各个子服务通过消息队列实现进程间通信和相互协作。
下面通过一次创建volume操作来说明cinder工作流程:
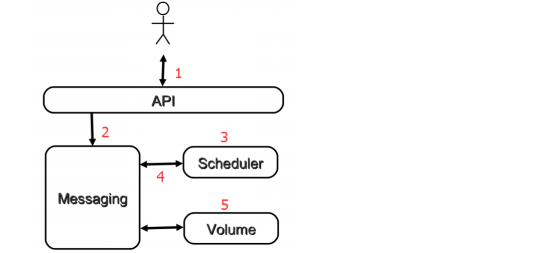
1、向cinder-api发送创建volume请求。
2、cinder-api向RabbitMQ发送了一条消息。
3、cinder-scheduler从RabbitMQ获取到消息,然后执行调度算法,从若干计存储点中选出节点。
4、cinder-scheduler向RabbitMQ发送让存储节点创建volume消息。
5、存储节点的cinder-volume从RabbitMQ中获取到消息,通过driver在volume provider上创建volume。
Neutron
Neutron管理的网络资源包括Network,subnet和port;network包含local, flat, VLAN, VxLAN和GRE;subnet是属于某个network的ip段;port可以看做虚拟交换机上的一个端口。
Neutron 构成:
Neutron Server:对外提供网络API,接收请求,并调用Plugin处理请求。
Plugin:处理Neutron Server发来的请求,维护OpenStack逻辑网络的状态,并调用Agent处理请求。
Agent:处理Plugin的请求,负责在network provider上真正实现各种网络功能。
network provider:提供网络服务的虚拟或物理网络设备,例如Linux Bridge,Open vSwitch或者其他支持Neutron的物理交换机。
Queue:Neutron Server,Plugin和agent之间通过Messaging Queue通信和调用。
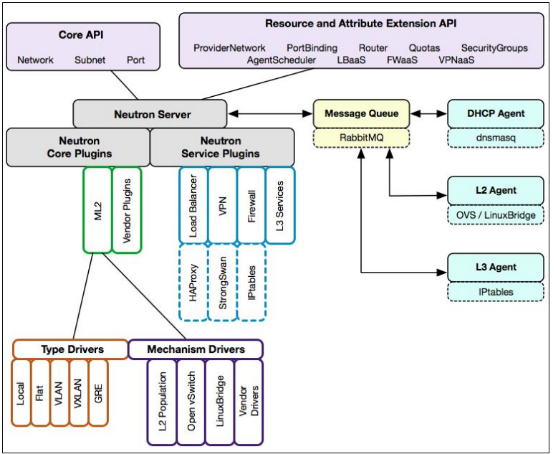
Neutron Server:
Neutron Server主要做两件事:提供 API 服务和运行 Plugin(Core Plugin,Service Plugin)下面是其基本分层结构:
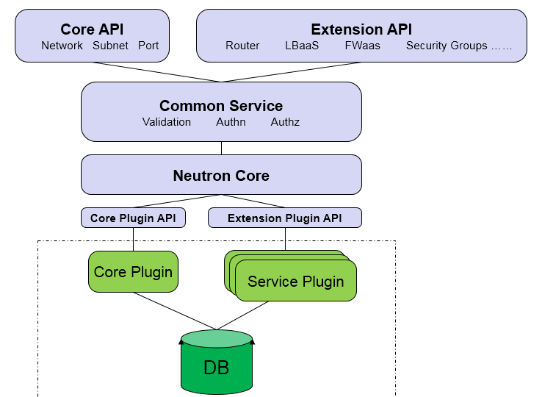
ML2 Core Plugin:
ML2作为新一代的core plugin,提供了一个框架,允许在OpenStack网络中同时使用多种Layer 2网络技术,不同的节点可以使用不同的网络实现机制,解决了传统的core plugin与core plugin agent一一对应的问题以及编写传统的core plugin需要编写大量重复和类似的数据库访问的代码的问题。
ML2对二层网络进行抽象和建模,引入了type driver和mechansim driver。每一种网络类型都有一个对应的ML2 type driver,type driver负责维护网络类型的状态,执行验证,创建网络等;每一种网络机制也都有一个对应的ML2 mechansim driver。 mechanism driver负责获取由type driver维护的网络状态,并确保在相应的网络设备(物理或虚拟)上正确实现。
Service Plugin:
Service Plugin 及其 Agent 提供更丰富的扩展功能,包括路由,load balance,firewall等
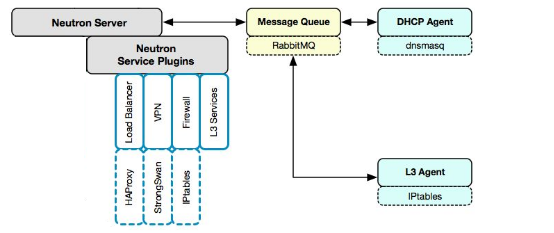
openstack网络类型:
local network:
不会与宿主机的任何物理网卡相连,也不关联任何的VLAN ID,用于内部测试,local网络的流量只能局限在本节点之内。
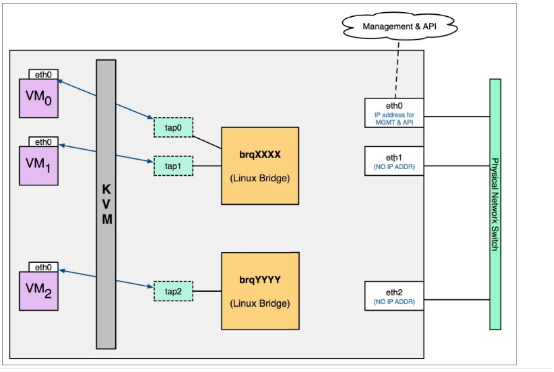
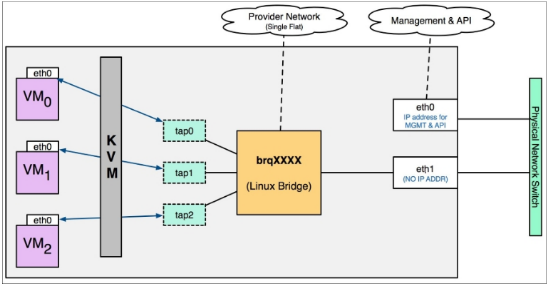
flat network:
是不带tag的网络,要求宿主机的物理网卡直接与linux bridge连接,所以每个flat network都会独占一个物理网卡。
vlan network:
带tag的网络,在物理网卡上创建了带vlanid的vlan interface,连接到lingux bridge,instance通过该vlan interface发送到的数据包就会打上该接口的tag,每个vlan network有自己的bridge,从而也就实现了基于vlan的隔离。
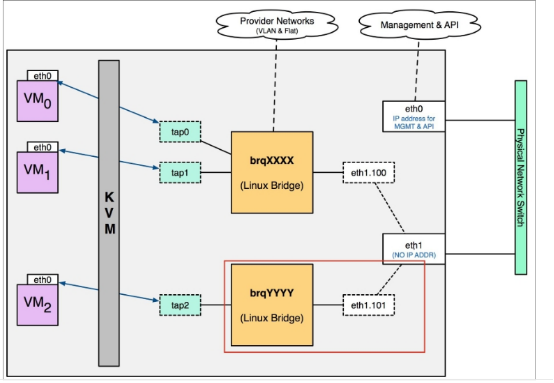
Vxlan network:
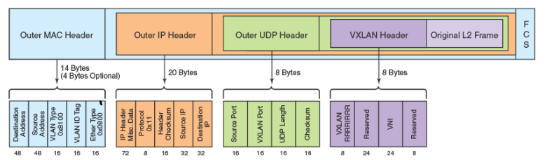
VXLAN全称Virtual eXtensible Local Area Network,由于VXLAN的数据包在整个转发过程中保持了内部数据的完整,因此VXLAN的数据平面是一个基于隧道的数据平面。它是一种将二层建立在三层上的网络,通过将二层数据封装到 UDP 的方式来扩展数据中心的二层网段数量。VXLAN的ID(VNI或者VNID)用24-bit标记,支持16777216个二层网段。
VXLAN 定义了一个MAC-in-UDP的封装格式。 在原始的Layer 2网络包前加上VXLAN header,然后放到UDP和IP包中。 通过MAC-in-UDP封装,VXLAN 能够在Layer 3网络上建立起了一条Layer 2的隧道。
VXLAN使用VXLAN tunnel endpoint(VTEP)设备处理VXLAN的封装和解封。 每个VTEP有一个IP interface,配置了一个IP地址。VTEP使用该IP封装Layer 2 frame,并通过该IP interface传输和接收封装后的VXLAN数据包。
VXLAN在VTEP间建立隧道,通过Layer 3网络传输封装后的Layer 2数据。
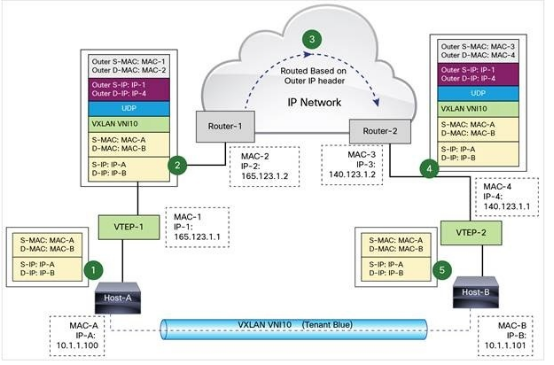
这里发现数据时以UDP的形式发送的,那么TCP怎么办?这里其实是UDP封装的TCP连接,UDP和TCP将做为两个独立的协议栈各自工作,相互之间没有交互。虚机始终认为自己是在用TCP交互。
为了实现VLAN和VXLAN之间互通,VXLAN定义了VXLAN网关。VXLAN网关上同时存在两种类型的端口:VXLAN端口和普通端口。当收到从VXLAN网络到普通网络的数据时,VXLAN网关去掉外层包头,根据内层的原始帧头转发到普通端口上;当有数据从普通网络进入到VXLAN网络时,VXLAN网关负责打上外层包头,并根据原始VLAN ID对应到一个VNI,同时去掉内层包头的VLAN ID信息。
在openstack上基本结构与vlan类似:
router:
物理router或者虚拟router为我们提供跨subnet互联互通功能,在router上分别配子网的网关,就可以完成数据的路由。opestack的l3 agent为每个router创建了一个namespace,通过veth pair与TAP相连,然后将Gateway IP配置在位于namespace里面的veth interface上,每个namespace拥有自己的路由表,这样既可以隔离不同租户的网络,从而支持网络重叠,又可以完成路由。
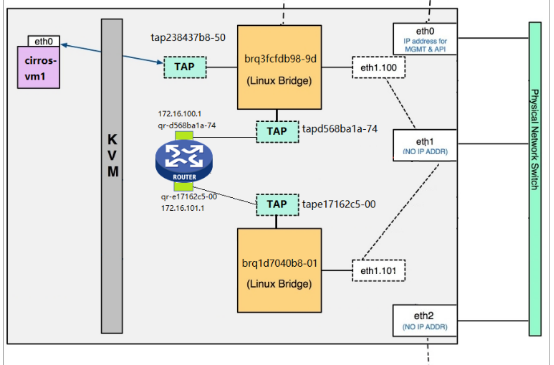
当租户网络连接到router,通常将router作为默认网关。
当router接收到instance的数据包,并将其转发到外网时:
1. router会修改包的源地址为自己的外网地址,这样确保数据包转发到外网,并能够从外网返回。
2. router修改返回的数据包,并转发给真正的instance。
这个行为被称作Source NAT。
如果需要从外网直接访问instance,则可以利用floating IP。
1. floating IP提供静态NAT功能,建立外网IP与instance租户网络IP的一对一映射。
2. floating IP是配置在router提供网关的外网interface上的,而非instance中。
3. router会根据通信的方向修改数据包的源或者目的地址。
Open vSwitch:
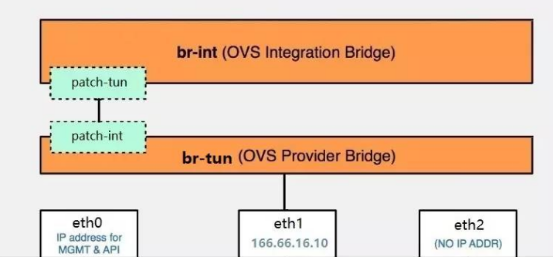
Open vSwitch的网络设备有:br-ex,连接外部(external)网络的网桥;br-int,集成(integration)网桥,所有instance的虚拟网卡和其他虚拟网络设备都将连接到该网桥;br-tun,隧道(tunnel)网桥,基于隧道技术的VxLAN和GRE网络将使用该网桥进行通信。
当我们创建一个子网,Neutron会为该子网启用一个dhcp接口,而每创建一个实例,都会创建一个linux bridge,一端连接实例的tap设备,另一端通过一个veth pair连接到br-int,而每一个子网都有一个tag,因为所有网络都是连接到br-int的,所以该tag是隔离不同网络的标识,local的网络,在ovs里表现如下:
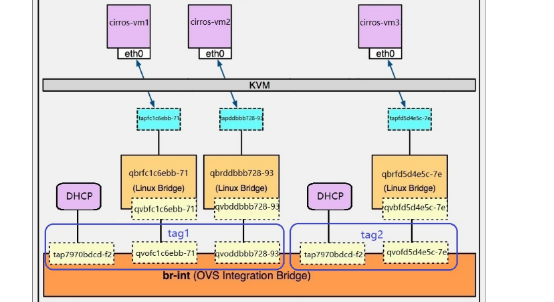
br-int是一个ovs网桥,但是我们可以连接网卡a,b,c。。。,上面讲的所有instance的虚拟网卡和其他虚拟网络设备都将连接到br-int,那该如何区分呢,这就需要我们创建另一个ovs网桥,该网桥通过patch port连接在一起,flat的网络在ovs里表现如下:
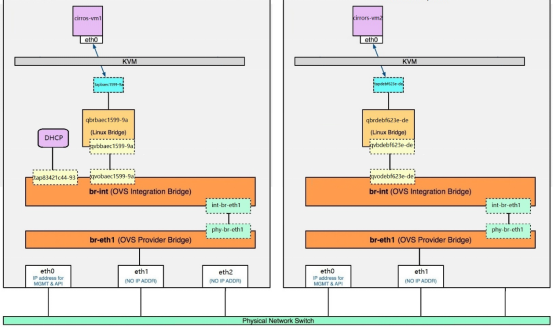
那ovs如何设置vlan的网络呢,上面提到一个tag,这个tag就是linux的vlan id,但是在ovs这里,这个只是内部id,vlan的网络不采用这种方式隔离。OVS通过flow rule(流规则)来指定如何对进出br-int的数据进行转发,进而实现vlan之间的隔离。当数据进出br-int时,flow rule可以修改、添加或者剥掉数据包的VLAN tag,Neutron负责创建这些flow rule并将它们配置到 br-int,br-eth1等ovs网桥上。比如:
priority=4,in_port=2,dl_vlan=1 actions=mod_vlan_vid:100,NORMAL
priority=4,in_port=2,dl_vlan=5 actions=mod_vlan_vid:101,NORMAL
一般设置在创建的网桥上,就是把内部tag 1转换为vlan 100,内部tag 5转换为vlan 101,而:
priority=3,inport=1,dl_vlan=100 actions=mod_vlan_vid:1,NORMAL
priority=3,inport=1,dl_vlan=101 actions=mod_vlan_vid:5,NORMAL
一般设置在br-int上,就是将vlan 100转为内部tag 1,将vlan 101转为内部tag 5。
如果需要访问外网,则需要将br-ex通过patch port连接到br-int,如果为虚机分配外网ip,则配置方式和之前一样,指定或dhcp一个ip地址,然后通过br-ex发出去;如果不为虚机分配外网ip,则需要通过router转发到br-ex:
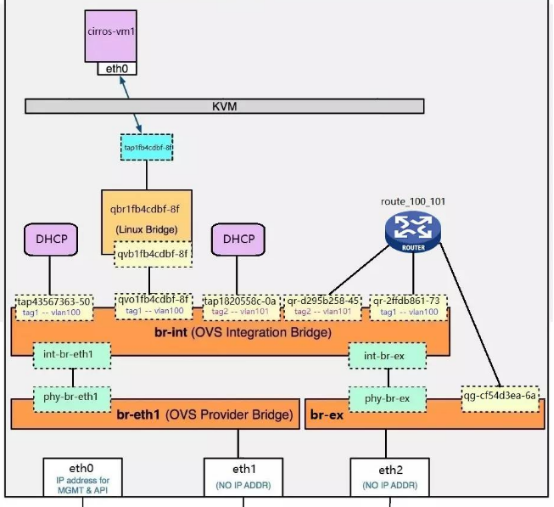
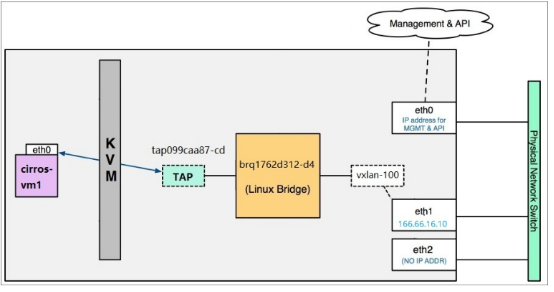
上面提到vxlan通过br-tun进行通信,需要把br-tun连接到br-int上,创建一个vxlan的网络,会在br-tun上创建一个特殊的port用来通信,指定了vxlan隧道本端VTEP和远端VTEP的地址,所以每两个VTEP就会生成一个port,vxlan的数据通信都是从这两个port发出。
ovs的vxlan通信也是采用流规则实现的,br-tun上定义的规则的大致转发如下:
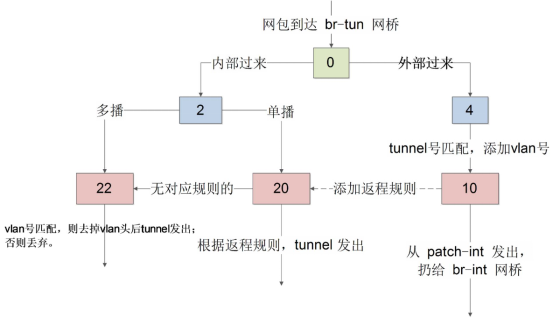
table 0将br-int进来的包转发给table 2处理,将其他VTEP发来的数据转发给table 4处理。
table 2将br-int进来的单播包转发给table 20处理,多播包转发给table 22处理。
table 4定义多条vxlan id和内部tag的映射关系,将其他VTEP发来的数据里的vxlan id转换为内部的tag,然后转发给table 10。
table 10将包转发给br-int,并往table 20添加一些返程信息。
table 20依赖table 10的学习,学习内容包括vxlan id和内部tag的映射关系,目标的mac地址等,收到发往该mac的消息;或对应tag的消息,则会根据这个学习结果完成id转换和转发,不再发往table 22。如果没有对应规则,则转发到table 22。
table 22将内部tag转换为vxlanid并发出。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号