
KVM 虚拟化技术
1、CPU虚拟化
KVM的虚拟化需要CPU硬件支持,当前,CPU厂商Intel和AMD都支持虚拟化了,执行命令egrep -o '(vmx|svm)' /proc/cpuinfo,如果有vmx或者svm的返回,则证明CPU支持虚拟化。
虚拟机CPU,内存以及一系列虚拟硬件由Hypervisor提供,虚拟机在KVM中其实是一个qemu-kvm进程,与其他Linux进程一样被调度,虚机中的每一个虚拟vCPU对应qemu-kvm进程中的一个线程,Hypervisor负责管理虚拟机的资源,并拥有所有虚拟机资源的控制权。
虚拟机在运行时需要CPU,CPU支持ring0~ring3四个等级,CPU运行在linux用到的有ring0和ring3,ring0时CPU正在运行的是内核的代码,ring3时CPU运行的是用户级代码,当发生系统调用或者进程切换的时候,CPU会从ring3级别转到ring0级别。为了支持虚拟化,Intel在ring0~ring3的基础上,引入了VMX模式,VMX分为root和non-root。Hypervisor运行在VMX root模式;虚拟机运行在VMX non-root模式。虚拟机并不知道自己运行在non-root模式,所以它也有ring0和ring3,但是non-root的ring0不能执行核心指令,仍然需要切换到root模式才行。当虚机执行特殊操作时,会触发VM exit事件,通过VM exit将cpu控制权返回给Hypervisor,Hypervisor处理完后再通过VM entry事件把结果和控制权返回给虚机。VM exit原因的列表记录在内核中。
内存中存在一个物理内存区域记录虚机exit,entry上下文,这个区域叫做VMCS(虚拟机控制结构),VM Exit的时候,CPU会将exit reason保存到MSRs(VMX模式的特殊寄存器组),并且将当前VM的上下文保存到VMCS中,Hypervisor再根据exit_reason做相应的处理,VM entry的时候把VMCS上下文恢复给VM。
2、内存虚拟化
KVM内存虚拟化,引入一层新的地址空间,即客户机物理地址空间 (Guest Physical Address, GPA),可以表面上让GuestOS使用一个隔离的、从零开始且连续的内存空间,这个地址空间并不是真正的物理地址空间,它只是宿主机虚拟地址空间在客户机地址空间的一个映射。对客户机来说,客户机物理地址空间都是从零开始的连续地址空间,但对于宿主机来说,客户机的物理地址空间并不一定是连续的,客户机物理地址空间有可能映射在若干个不连续的宿主机虚拟地址。
由于客户机物理地址不能直接用于宿主机物理MMU进行寻址,所以需要把客户机物理地址转换成宿主机虚拟地址(Host Virtual Address ,HVA),首先根据客户机物理地址找到对应的映射区间,然后根据此客户机物理地址在此映射区间的偏移量就可以得到其对应的宿主机虚拟地址。进而再通过宿主机的页表找到宿主机物理地址,完成GPA到HPA的转换。
实现内存虚拟化,最主要的是实现客户机虚拟地址(Guest Virtual Address,GVA)到宿主机物理地址之间的转换。根据上述客户机物理地址到宿主机物理地址之间的转换以及客户机页表,即可实现客户机虚拟地址空间到客户机物理地址空间之间的映射,也即GVA到HPA的转换。显然通过这种映射方式,客户机的每次内存访问都需要KVM介入,并由软件进行多次地址转换,其效率是非常低的。因此,为了提高GVA到HPA转换的效率,KVM提供了两种实现方式来进行客户机虚拟地址到宿主机物理地址之间的直接转换。其一是基于纯软件的实现方式,也即通过影子页表(Shadow Page Table)来实现客户虚拟地址到宿主机物理地址之间的直接转换。其二是基于硬件对虚拟化的支持,来实现两者之间的转换。
首先介绍影子页表,影子页表可以实现客户机虚拟地址到宿主机物理地址的直接转换,由于客户机中每个进程都有自己的虚拟地址空间,所以KVM需要为客户机中的每个进程页表都要维护一套相应的影子页表,在客户机访问内存时,真正被装入宿主机MMU的是客户机当前页表所对应的影子页表,从而实现了从客户机虚拟地址到宿主机物理地址的直接转换。为了快速检索客户机页表所对应的的影子页表,KVM为每个客户机都维护了一个哈希表,影子页表和客户机页表通过此哈希表进行映射。对于每一个客户机来说,客户机的页目录和页表都有唯一的客户机物理地址,通过页目录/页表的客户机物理地址就可以在哈希链表中快速地找到对应的影子页目录/页表。
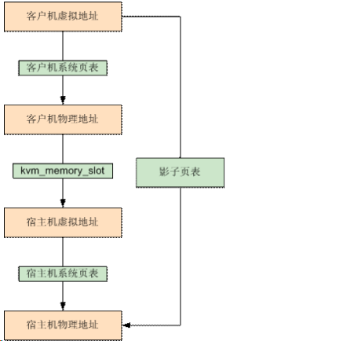
由于影子页表可被载入物理MMU为客户机直接寻址使用,所以客户机的大多数内存访问都可以在没有KVM介入的情况下正常执行,没有额外的地址转换开销,也就大大提高了客户机运行的效率。但是影子页表的引入也意味着KVM需要为每个客户机的每个进程的页表都要维护一套相应的影子页表,这会带来较大内存上的额外开销,此外,客户机页表和影子页表的同步也比较复杂。因此,Intel的EPT(Extent Page Table)技术和AMD的NPT(Nest Page Table)技术都对内存虚拟化提供了硬件支持。这两种技术原理类似,都是在硬件层面上实现客户机虚拟地址到宿主机物理地址之间的转换。
EPT页表,EPT技术在原有客户机页表对客户机虚拟地址到客户机物理地址映射的基础上,又引入了EPT页表来实现客户机物理地址到宿主机物理地址的另一次映射,这两次地址映射都是由硬件自动完成。EPT页表相对于前述的影子页表,实现方式大大简化,而且KVM只需为每个客户机维护一套EPT页表,也大大减少了内存的额外开销。
3、存储虚拟化
KVM的存储有基于文件的存储和基于设备的存储。
创建一个KVM的虚拟机的时候,默认使用虚拟磁盘文件作为后端存储,此时虚拟机可见到的是一块实际的硬盘,但实际上使用的是一个虚拟磁盘文件所表示的一个硬盘。这里包含了一层额外的文件系统层,这一层文件系统层会导致系统变慢。
部署KVM主机的时候,你可以选择文件系统目录(dir)或者格式化的块设备(fs)作为KVM的存储。默认是使用dir,KVM会在选择的本地文件系统目录中创建磁盘映像文件。如果使用fs选项,需要提供存储磁盘映像文件的格式化文件系统的名字。此选项和目录类型的存储最大的区别在于,格式化磁盘映像没有挂载在一个指定的路径下,磁盘镜像的格式,通常的选择有两种,一种是raw镜像格式,一种是qcow2格式,镜像文件不一定都放置到宿主机本地文件系统中,也可以存储在通过网络连接的远程文件系统。
使用文件做存储有很多优点:存储方便、移植性好、可复制、可远程访问。但由于KVM的虚拟机对于硬盘的操作都不是直接写入到KVM的存储介质,而是在宿主主机上的文件系统。这就意味这访问文件系统的时候都需要经过一个不必要经过的中间访问层,这通常会降低性能。
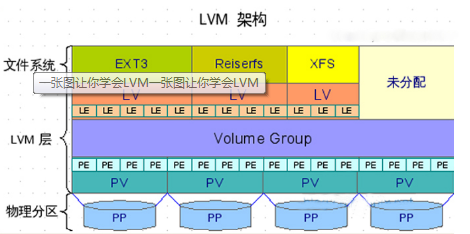
使用基于设备的存储,有四种方式可以提供此类型的物理存储设备访问:disk、iSCSI、SCSI以及logical。disk允许你直接对磁盘进行读写。iSCSI(互联网小型计算机系统接口)和SCSI以接口方式提供了另一种方式对磁盘进行访问。这种类型的KVM存储方式的好处在于:你可以使用持久化的命名而不依赖于宿主主机发现设备的顺序。这几种访问磁盘的方式也存在缺点:不灵活,比较僵化。如果使用此种类型的存储,那么基本上没有办法修改虚拟磁盘的大小,或者针对虚拟机进行快照功能。LVM(Logical Volume Manager)是KVM存储方式中,提升灵活性的最佳方式,LVM允许将存储放置到一个存储卷组中,基于存储卷组,可以很容易的创建一个逻辑的卷。卷组是抽象的物理磁盘设备,所以当你的可用磁盘空间不足的时候,你可以新添加一个设备到卷组中,这个操作实际上增加了可用的直接存储空间到逻辑卷。使用LVM使得设备空间分配更灵活,同时也使得更容易的添加和删除存储,下面是lvm的基本架构。
4、网络虚拟化
Linux用户想要使用网络功能,不能通过直接操作硬件完成,而需要直接或间接的操作一个Linux为我们抽象出来的设备,既通用的Linux网络设备来完成。一个常见的情况是,系统里装有一个硬件网卡,Linux会在系统里为其生成一个网络设备实例,如eth0,用户需要对eth0发出命令以配置或使用它了。
Linux Bridge是Linux上用来做TCP/IP二层协议交换的设备,与现实世界中的交换机功能相似。Bridge设备实例可以和Linux上其他网络设备实例连接,既attach一个从设备,类似于在现实世界中的交换机和一个用户终端之间连接一根网线。当有数据到达时,Bridge会根据报文中的MAC信息进行广播、转发、丢弃处理。
假设宿主机有1块与外网连接的物理网卡eth0,上面跑了1个虚机VM1,给VM1分配一个虚拟网卡vnet0,通过Linux Bridge br0将eth0和vnet0连接起来,如下图所示:
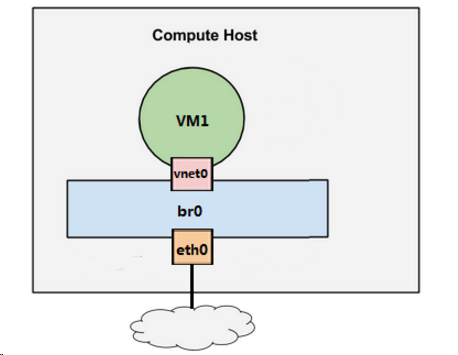
Linux Bridge是Linux上用来做TCP/IP二层协议交换的设备,当有数据到达eth0时,br0会将数据转发给vnet0,这样VM1就能接收到来自外网的数据;反过来,VM1发送数据给vnet0,br0也会将数据转发到eth0,从而实现了VM1与外网的通信。
LAN表示Local Area Network,本地局域网,通常使用Hub和Switch来连接LAN中的计算机。一般来说,两台计算机连入同一个Hub或者Switch时,它们就在同一个LAN中。
一个LAN表示一个广播域,即LAN中的所有成员都会收到任意一个成员发出的广播包。VLAN表示Virtual LAN。一个带有VLAN功能的switch能够将自己的端口划分出多个LAN。计算机发出的广播包可以被同一个LAN中其他计算机收到,但位于其他LAN的计算机则无法收到。简单地说,VLAN将一个交换机分成了多个交换机,限制了广播的范围,在二层将计算机隔离到不同的VLAN中。LAN的隔离是二层上的隔离,A和B无法相互访问指的是二层广播包无法跨越VLAN的边界。但在三层上(比如IP)是可以通过路由器让A和B互通的。
现在的交换机几乎都是支持VLAN的,通常交换机的端口有两种配置模式:Access和Trunk。Access口,这些端口被打上了VLAN的标签,表明该端口属于哪个VLAN。不同VLAN用VLAN ID来区分,VLAN ID的范围是1-4096。Access口都是直接与计算机网卡相连的,这样从该网卡出来的数据包流入Access口后就被打上了所在VLAN的标签。Access口只能属于一个VLAN。假设有两个交换机A和B。A上有VLAN1(红)、VLAN2(黄)、VLAN3(蓝);B上也有VLAN1、2、3那如何让AB上相同VLAN之间能够通信呢?办法是将A和B连起来,而且连接A和B的端口要允许VLAN1、2、3三个VLAN的数据都能够通过。这样的端口就是Trunk口了。VLAN1、2、3的数据包在通过Trunk口到达对方交换机的过程中始终带着自己的VLAN标签。
KVM虚拟化环境下,创建一个vlan,会生成一个带vlanid的子设备,例如eth0是宿主机上的物理网卡,有一个命名为eth0.10的子设备与之相连。eth0.10就是VLAN设备了,其VLANID就是VLAN10。eth0.10挂在命名为brvlan10的Linux Bridge上,创建一个虚机VM1,其虚拟网卡vent0也挂在brvlan10上,如下图:
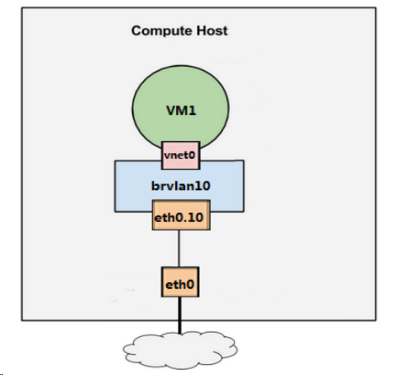
VM1通过vnet0发出来的数据包会被打上VLAN10的标签。而brvlan10 Bridge上的其他网络设备都会自动加入到VLAN10中,综上所述,Linux Bridge + VLAN = 虚拟交换机。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号