
机器学习之特征工程
一、特征抽象
特征抽象是指将数据源抽象算法可以理解的数据,我们期望的数据是一组可以表达数据某种特性的数字。
下面对几种数据类型抽象举例:
(1)时间戳
以某一天为基准值,采用算法算出某数值,其他的采用和该基准值的差距。
(2)二值类问题
文本或其他描述的二值问题,可以量化为0和1表示。
(3)多值有序问题
类似二值,可以将几个表示连续的几个参数量化为几个连续的数值。
(4)多值无序问题
一种是采用某种方式进行信息阉割,牺牲非量化字段的信息,转化为主观测特征,非主观测特征的二值方式。
另一种是采用one-hot编码通过唯一数值标识每个字符数据在其特征特征列中的位置来实现特征编码。
(5)文本类型
一般是先分词,然后按文本位置或者词性来提取特征。
(6)图像或语音数据
大体思路是将图像或语音转换为矩阵结构,例如图像可以以像素点切割。
二、特征重要性评估
1、回归模型系数法
一些线性模型的训练结果是一个数学公式,类似y=a1x1 + a2x2 + a3x3 + ...,a1,a2,a3就是系数,如果想用逻辑回归的模型各特征参数评估特征重要性,需要对数据进行归一化处理。
通常,系数越大的特征,对结果影响越大,表达结果与特征相关性一般采用如下公式:
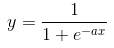
2、信息熵判断法
信息熵:在信源中考虑的不是单一符号的发生的不确定性,而是要考虑这个信源所以可能发生情况的平均不确定性,若信源有n种可能U1,U2,U3,...,对应概率为P1,P2,P3...,且各自出现独立,则平均不确定性为:
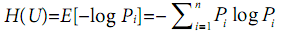
信息熵越大,信息量就越大,不确定性也越大,从信息增益角度讲,特征带来的信息越多,特征越重要,目标队列和特征队列信息熵之差表示特征影响度,即目标列 - 特征列信息增益 = 特性影响度。
三、特征衍生
特征衍生是指利用现有特征进行某种组合,生成新的具有含义的特征。
举例说明:统计用户的购物行为:
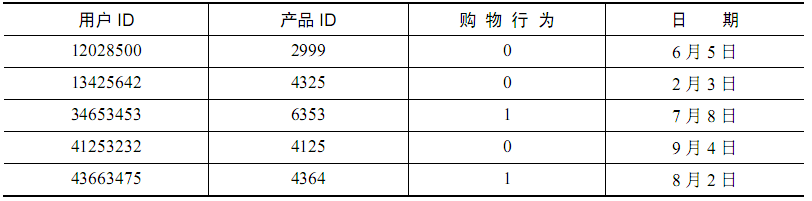
原本如下是一个二值问题,即购买或未购买,然而通过统计用户历史购买数量,可以衍生出购买总数;
通过购买总数与购买时间差可以衍生出购买频率;
通过产品在时间段的购买分别可以衍生出产品旺季淡季;
通过产品重复购买时间可以衍生出产品更换频率等等。
最终根据需求的不同得到很多数据,完善算法入参。
四、特征降维
1、概念
特征降维就是挖掘其中的关键字段,减少输入矩阵的维度。
目的是:
1)、确保变量间的相互独立。
2)、减少计算量。
3)、去除噪声。
常用的降维方法:
1)、主成分分析(Principal Component Analysis,PCA),通过线性映射投影的方式把高维数据映射到低维空间中。
2)、线性判别式分析(Linear Discriminant Analysis, LDA),将高维的模式样本投影到最佳鉴别矢量空间,以达到抽取分类信息和压缩特征空间维数的效果,投影后保证模式样本在新的子空间有最大类间间距和最小类内间距,即模式在该空间有最佳的可分离性。
3)、局部线性嵌入((Locally linear embedding, LLE),非线性降维算法,降维后可以继续保持数据的流行结构。
2、主成分分析
PCA基本思路是旋转坐标轴到方差最大的方向,设X是一个变量,E(X)表示数据平均值,![]() 表示方差,方差表示数据变化可能性最大的方向。
表示方差,方差表示数据变化可能性最大的方向。
保留原始数据最大方差方向的数据主要是通过转换坐标系的方法,把源数据最大方差方向变为新坐标系的一个坐标轴,另一个轴选择与新坐标轴垂直的直线,一直重复这样的操作就可以减小数据的维度。
通过PCA数学公式进行降维:
1)求协方差矩阵
在概率论和统计学中,协方差用于衡量两个变量的总体误差。而方差是协方差的一种特殊情况,即当两个变量是相同的情况。协方差的值如果为正值,则说明两者是正相关的(从协方差可以引出“相关系数”的定义),结果为负值就说明负相关的,如果为0,也是就是统计上说的“相互独立”。
协方差公式:

协方差矩阵表示为:
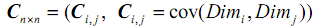
如果是三维矩阵,则表示如下:
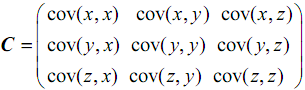
2)提取特征值和特征向量
设A是n阶方阵,如果存在常数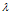 及非零n向量x,使得
及非零n向量x,使得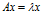 ,则称
,则称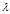 是矩阵A的特征值,x是A属于特征值
是矩阵A的特征值,x是A属于特征值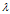 的特征向量。
的特征向量。
特征值越大,说明矩阵在对应特征向量上的方差越大,所以将特征值都求出来,将特征值从大到小排序,保留前n维特征向量就是将矩阵降到n维。
3)代码实现
def pca(data_mat, dimen): # numpy.mean 求均值: # axis 不设置值,对 m*n 个数求均值,返回一个实数 # axis = 0:压缩行,对各列求均值,返回 1* n 矩阵 # axis =1 :压缩列,对各行求均值,返回 m *1 矩阵 mean_value = numpy.mean(data_mat, axis=0) mean_removed = data_mat - mean_value # 求每个元素与均值之差 # numpy.cov: 求矩阵协方差 # 如果rowvar为True(默认值),则每行代表一个变量,并在列中显示(即每一列为一个样本)。 # 否则,关系被转置:每列代表变量,而行包含观察值。 cov_mat = numpy.cov(mean_removed, rowvar=False) vals, vects = numpy.linalg.eig(numpy.mat(cov_mat)) # 计算矩阵的特征值和特征向量 val_ind = numpy.argsort(vals) # 对特征值排序,返回的是数组值从小到大的索引值 val_ind = val_ind[: -(dimen + 1): -1] # 从后往前取目标尺寸 red_eig_vector = vects[:, val_ind] # 取对应的特征向量 low_data_mat = mean_removed * red_eig_vector # 将数据映射到特征向量空间上 return low_data_mat

 浙公网安备 33010602011771号
浙公网安备 33010602011771号