大数据简介
大数据简介
-从BI到大数据
BI
什么是BI
BI(Business Intelligence)即商务智能,它是一套完整的解决方案,用来将企业中现有的数据进行有效的整合,快速准确地提供报表并提出决策依据,帮助企业做出明智的业务经营决策。
应用范围:
商业智能系统可辅助建立信息中心,如产生各种工作报表和分析报表。
为什么传统BI没前途?
计算性能:浙江移动用GBASE+HADOOP花了半年时间把2台P780替换掉了,综合性能可以说是原来的1.5倍,但投资只有几分之一,虽然前期涉及一些调优,对于代码也有更高的要求,但性价比非常高
数据采集:目前采集方式的百花齐放,即消息、数据流、爬虫、文件、日志增量都能支持
数据采集需要分布式,可以并行动态扩展。这些对于传统BI挑战很大。
多维分析:打cube, 千万级数据量、10个维度估计也是它的性能极限
挖掘平台:SAS、SPSS都是传统数据挖掘的利器,但他们大部分时候只能在PC上进行抽样分析。从样本到全量,需要全面升级装备。
……
大数据
随着软硬件技术的进度,传统BI存在的问题,被大数据时代解决了。

大数据的定义,随着技术的发展不断演进

不同认知角度的大数据定义

大数据的典型特征(4V)

规模:传统数据库,从未处理过PB级的数据。大数据动不动就是上百PB。
速度:海量数据实时处理。
传统的处理方式比较慢。关于公共卫生的例子。09年甲流流行时,传统做法
医生在发现新型流感病例时告知疾病控制与预防中心。 但由于人们可能患病多日实在受不了了才会去医院,
同时这个信息传达回疾控中心也需要时间, 因此, 通告新流感病例时往往会有一两周的延迟。 而且, 疾控中心每周只进行一次数据汇总。 然而, 对于一种飞速传播的疾病,
信息滞后两周的后果将是致命的。 这种滞后导致公共卫生机构在疫情爆发的关键时期反而无所适从。
Google根据大家的搜索数据,提供更有效、 更及时的指示标。
不仅是全美范围的传播, 而且可以具体到特定的地区和州。 谷歌通过观察人们在网上的搜索记录来完成这个预测, 而这种方法以前一直是被忽略的。
价值:数据被称为 新时代的石油。石油的价值?控制石油价格,控制全世界。
大数据思维区别于传统思维,其精髓在于数据分析方法的3个转变

大数据应用

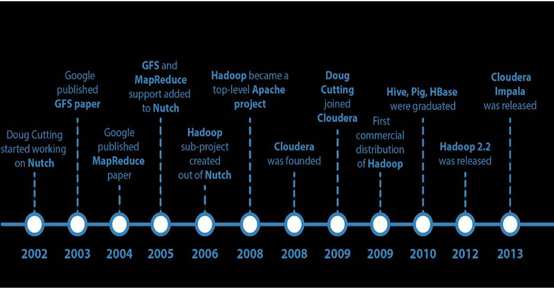
大数据发展史
大数据技术主要是Google发了3篇论文Google File System(GFS), MapReduce,BigTable。
但是大数据时代跟他没半毛钱关系,为什么?他撒了谎,虽然告诉我们一些知识了,但是有所隐瞒。所以也就拿不出相应的开源产品。
当人工智能这个新泡泡起来的时候,Google迅速采用了一个完全不同的策略,不仅仅用AlphaGo这个程序告诉大家,所谓围棋,不管东亚人怎么吹是信仰是人生是哲理,其实无非就是个计算的问题。Google接下来很快的开放了Google内部的人工智能平台TensorFlow。
Google的大数据三驾马车
三驾马车之永垂不朽的GFS
这篇论文值得每个做系统的人反复的读。
三驾马车之坑人的MapReduce
MapReduce计算模型极其的粗糙。从做数据库的人的角度来看这无非是一个select一个groupby,这些花样197x的时候在SystemR里都被玩过了。
完全基于MapReduce的很多project都不太成功。这个计算模型最重要的是做inverted index build。另外随着F1的披露,大家知道Google的Ads系统实际上长期运行在MySQL上,这也从侧面反应了Google内部的一些情况和当初论文的高调宣扬之间的矛盾。
很重要的资源管理系统Borg又在当初的论文里被彻底隐藏起来。HadoopV2必须引入Yarn的很重要的原因。
微软内部支撑大数据分析的平台Cosmos是狠狠的抄袭了Google的File system却很大程度上摒弃了MapReduce这个框架。
当然MapReduce不是一无是处,它告诉大家如何用一堆廉价PC去稳定的实现超大规模的并行数据处理。
李逵麻子,李鬼坑人--BigTable的数据模型
A BigTable is a sparse, distributed, persistent multidimensional sorted map.
复合key<key1, key2, key3>.其中这几个key的名字分别如下:
key1: row
key2: column
key3:timestamp
BigTable是一个map,也就注定它不是数据库,没有数据库的特性,不能支持按列查询。这也是基于HBase的查询引擎百花齐发的原因。
Google File System(GFS), MapReduce,BigTable。如果我们拉长时间轴到20年为一个周期来看呢,这三驾马车到今天的影响力其实已然不同。MapReduce作为一个有很多优点又有很多缺点的东西来说,很大程度上影响力已经释微了。BigTable以及以此为代表的各种KeyValue Store还有着它的市场,但是在Google内部Spanner作为下一代的产品,也在很大程度上开始取代各种各样的的BigTable的应用。而作为这一切的基础的Google File System,不但没有任何倒台的迹象,还在不断的演化,事实上支撑着Google这个庞大的互联网公司的一切计算。
Presto之坑和萝卜傻子和骗子的故事
Presto的来源有个八卦,大致上是Facebook的人觉得HIVE太慢于是让HIVE团队开发一个更快的。HIVE团队在犹豫是在HIVE上继续开发还是搞个新的。
做出来的决定是让5个人继续开发HIVE,让一个人去做新的。结果这一个人的手脚比五个人更快,做出来Presto。所以有的时候人多也未必力量大啊。
于是Presto就取代了在开发中的interactive HIVE上线了。再后来Facebook老的HIVE团队,创业的去创业,去startup的去startup,也就散了。
这事典型的Facebook开源项目,管杀不管埋。所以有人经常抱怨你们开源了怎么不好好维护呢?Facebook干这类事情不是第一次了,这之前有Cassandra。后来被开源社区接管了Cassandra过的不错。
国内Presto最忠实的用户可能是美团了。
个人感觉用主流的技术,踩坑的人够多,这样可以少踩一点坑。另外不迷信大公司与专家。
参考文献
大数据那些事(30):Presto之坑和萝卜傻子和骗子的故事

 浙公网安备 33010602011771号
浙公网安备 33010602011771号