
1、Get方法
爬取豆瓣……
# Authors:xiaobei
## AJAX 适用于 1.滑动刷新的页面 2.分页刷新的页面
import urllib.request
import urllib.parse
url = 'https://movie.douban.com/j/search_subjects?'
tag = input('请输入要查询的电影类型:')
pagenum = eval(input('请输入要查询电影的页数:'))
# 构建请求头
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/77.0.3865.42 Safari/537.36',
}
data = {
'type':'movie',
'tag':tag,
'sort':'recommend',
'page_limit': 20,
'page_start': (pagenum-1)*20,
} # 请求数据类型通过抓包获取
query_data = urllib.parse.urlencode(data)
# 构建Get请求形式
url += query_data
# 构建请求对象
request = urllib.request.Request(url = url,headers = headers)
# 发送请求
response = urllib.request.urlopen(request)
# 接收并打印数据
print(response.read().decode())
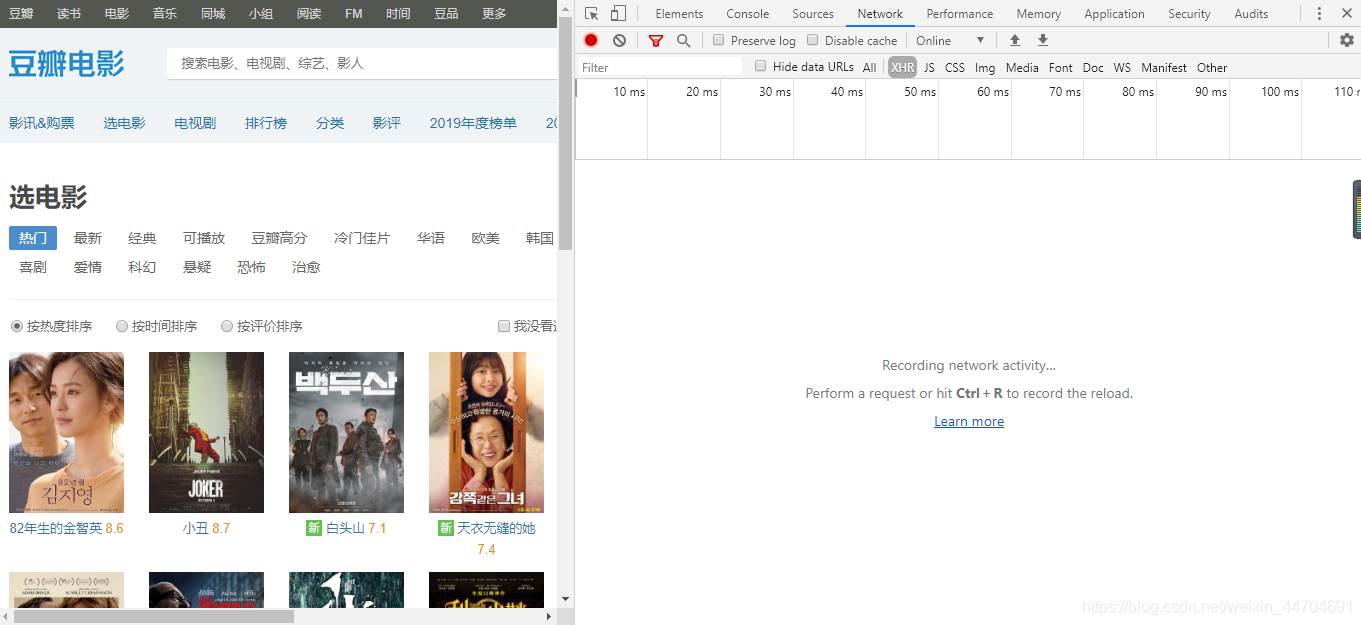
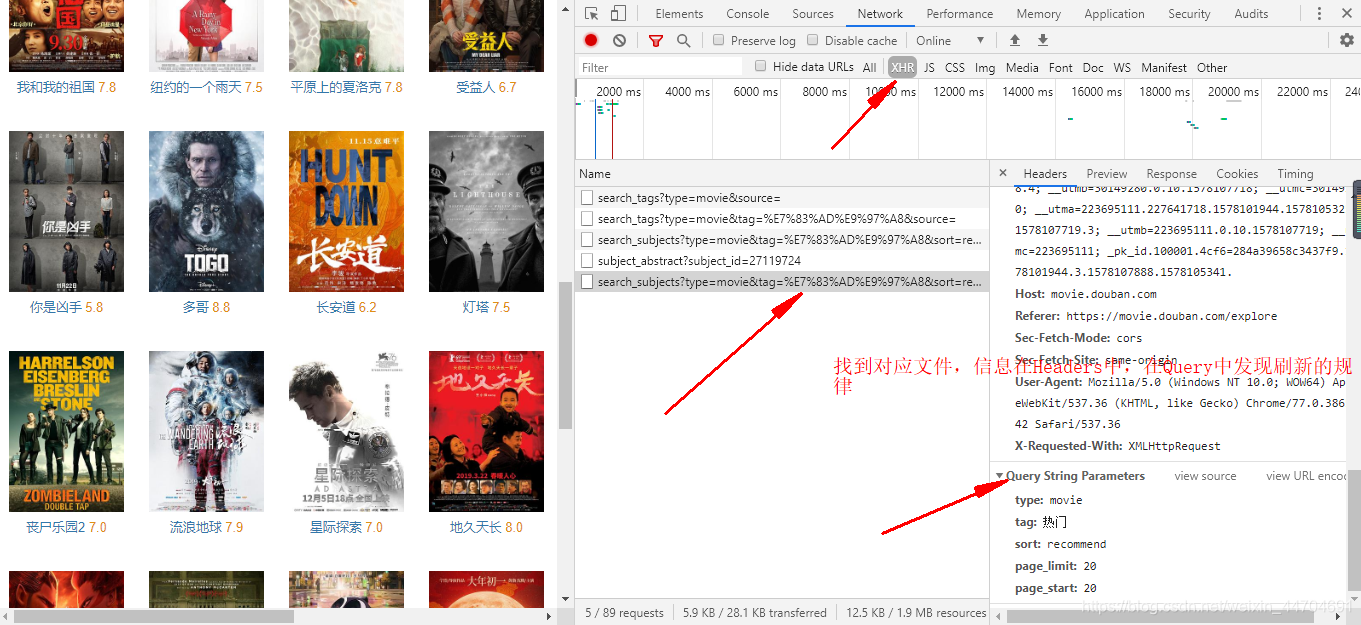
关于抓包获取信息
我使用pc谷歌浏览器的开发者工具……
爬取结果
请输入要查询的电影类型: 热门
请输入要查询电影的页数: 5
{“subjects”:[{“rate”:“7.6”,“cover_x”:3000,“title”:“世纪末”,“url”:“https://movie.douban.com/subject/30483380/”,“playable”:false,“cover”:“https://img9.doubanio.com/view/photo/s_ratio_poster/public/p2577169336.jpg”,“id”:“30483380”,“cover_y”:4374,“is_new”:false},{“rate”:“6.3”,“cover_x”:3000,“title”:“犯罪现场”,“url”:“https://movie.douban.com/subject/26235346/”,“playable”:true,“cover”:“https://img9.doubanio.com/view/photo/s_ratio_poster/public/p2570879785.jpg”,“id”:“26235346”,“cover_y”:4200,“is_new”:false},{“rate”:“6.5”,“cover_x”:1350,“title”:“大侦探皮卡丘”,“url”:“https://movie.douban.com/subject/26835471/”,“playable”:true,“cover”:“https://img1.doubanio.com/view/photo/s_ratio_poster/public/p2555538168.jpg”,“id”:“26835471”,“cover_y”:2000,“is_new”:false},{“rate”:“6.3”,“cover_x”:8100,“title”:“舞女大盗”,“url”:“https://movie.douban.com/subject/30294313/”,“playable”:false,“cover”:“https://img1.doubanio.com/view/photo/s_ratio_poster/public/p2565492557.jpg”,“id”:“30294313”,“cover_y”:12000,“is_new”:false},{“rate”:“7.3”,“cover_x”:1728,“title”:“朱迪”,“url”:“https://movie.douban.com/subject/27179039/”,“playable”:false,“cover”:“https://img3.doubanio.com/view/photo/s_ratio_poster/public/p2561885281.jpg”,“id”:“27179039”,“cover_y”:2664,“is_new”:false},{“rate”:“5.8”,“cover_x”:4000,“title”:“X战警:黑凤凰”,“url”:“https://movie.douban.com/subject/26667010/”,“playable”:true,“cover”:“https://img3.doubanio.com/view/photo/s_ratio_poster/public/p2555886490.jpg”,“id”:“26667010”,“cover_y”:5915,“is_new”:false},{“rate”:“5.1”,“cover_x”:1500,“title”:“小小的愿望”,“url”:“https://movie.douban.com/subject/30235440/”,“playable”:true,“cover”:“https://img1.doubanio.com/view/photo/s_ratio_poster/public/p2567277578.jpg”,“id”:“30235440”,“cover_y”:2100,“is_new”:false},{“rate”:“7.2”,“cover_x”:1000,“title”:“我身体里的那个家伙”,“url”:“https://movie.douban.com/subject/27088750/”,“playable”:false,“cover”:“https://img9.doubanio.com/view/photo/s_ratio_poster/public/p2540444795.jpg”,“id”:“27088750”,“cover_y”:1425,“is_new”:false},{“rate”:“5.7”,“cover_x”:1800,“title”:“新喜剧之王”,“url”:“https://movie.douban.com/subject/4840388/”,“playable”:true,“cover”:“https://img1.doubanio.com/view/photo/s_ratio_poster/public/p2555440969.jpg”,“id”:“4840388”,“cover_y”:2524,“is_new”:false},{“rate”:“6.3”,“cover_x”:1080,“title”:“速度与激情:特别行动”,“url”:“https://movie.douban.com/subject/27163278/”,“playable”:true,“cover”:“https://img3.doubanio.com/view/photo/s_ratio_poster/public/p2561542272.jpg”,“id”:“27163278”,“cover_y”:1581,“is_new”:false},{“rate”:“6.5”,“cover_x”:5656,“title”:“仲夏夜惊魂”,“url”:“https://movie.douban.com/subject/30288638/”,“playable”:false,“cover”:“https://img3.doubanio.com/view/photo/s_ratio_poster/public/p2550004671.jpg”,“id”:“30288638”,“cover_y”:8191,“is_new”:false},{“rate”:“7.2”,“cover_x”:1153,“title”:“密室逃生”,“url”:“https://movie.douban.com/subject/27109679/”,“playable”:true,“cover”:“https://img3.doubanio.com/view/photo/s_ratio_poster/public/p2543631842.jpg”,“id”:“27109679”,“cover_y”:1700,“is_new”:false},{“rate”:“7.4”,“cover_x”:2000,“title”:“驯龙高手3”,“url”:“https://movie.douban.com/subject/19899707/”,“playable”:true,“cover”:“https://img3.doubanio.com/view/photo/s_ratio_poster/public/p2546335362.jpg”,“id”:“19899707”,“cover_y”:2975,“is_new”:false},{“rate”:“5.8”,“cover_x”:806,“title”:“8号警报”,“url”:“https://movie.douban.com/subject/27066172/”,“playable”:false,“cover”:“https://img3.doubanio.com/view/photo/s_ratio_poster/public/p2572545203.jpg”,“id”:“27066172”,“cover_y”:1200,“is_new”:false},{“rate”:“6.5”,“cover_x”:1429,“title”:“坏家伙们”,“url”:“https://movie.douban.com/subject/30249076/”,“playable”:false,“cover”:“https://img1.doubanio.com/view/photo/s_ratio_poster/public/p2571799297.jpg”,“id”:“30249076”,“cover_y”:2048,“is_new”:false},{“rate”:“7.0”,“cover_x”:1000,“title”:“爱宠大机密2”,“url”:“https://movie.douban.com/subject/26848167/”,“playable”:true,“cover”:“https://img3.doubanio.com/view/photo/s_ratio_poster/public/p2555923582.jpg”,“id”:“26848167”,“cover_y”:1428,“is_new”:false},{“rate”:“6.5”,“cover_x”:1429,“title”:“烈火英雄”,“url”:“https://movie.douban.com/subject/30221757/”,“playable”:true,“cover”:“https://img3.doubanio.com/view/photo/s_ratio_poster/public/p2563630521.jpg”,“id”:“30221757”,“cover_y”:2000,“is_new”:false},{“rate”:“7.4”,“cover_x”:1000,“title”:“杀手寓言”,“url”:“https://movie.douban.com/subject/30255079/”,“playable”:false,“cover”:“https://img9.doubanio.com/view/photo/s_ratio_poster/public/p2551329804.jpg”,“id”:“30255079”,“cover_y”:1413,“is_new”:false},{“rate”:“6.4”,“cover_x”:485,“title”:“心愿房间”,“url”:“https://movie.douban.com/subject/30386678/”,“playable”:false,“cover”:“https://img3.doubanio.com/view/photo/s_ratio_poster/public/p2557967220.jpg”,“id”:“30386678”,“cover_y”:680,“is_new”:false},{“rate”:“6.9”,“cover_x”:5907,“title”:“惊奇队长”,“url”:“https://movie.douban.com/subject/26213252/”,“playable”:true,“cover”:“https://img3.doubanio.com/view/photo/s_ratio_poster/public/p2546360443.jpg”,“id”:“26213252”,“cover_y”:8269,“is_new”:false}]}
2、Post方法
爬取百度贴吧……
#Authors:xiaobei
## AJAX 适用于 1.滑动刷新的页面 2.分页刷新的页面
import urllib.request
import urllib.parse
url = 'http://tieba.baidu.com/f'
name = input('请输入要搜索的吧名:')
num = eval(input('请输入要获得的页数:'))
form_data = {
'kw': name,
'ie': 'utf-8',
'pn': 50*(num-1),
} # 通过抓包获得
# 构建Post请求形式
query_data = urllib.parse.urlencode(form_data).encode()
# 构建请求头
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/77.0.3865.42 Safari/537.36',
'Accept-Encoding': '',
'Accept-Language': 'zh-CN,zh;q=0.9',
}
# 构建请求对象
request = urllib.request.Request(url = url,headers = headers)
# 发送请求
response = urllib.request.urlopen(request,query_data)
# 接收并输出数据
print(response.read(1000))
urllib.request.urlretrieve(url,'baidutieba.html')
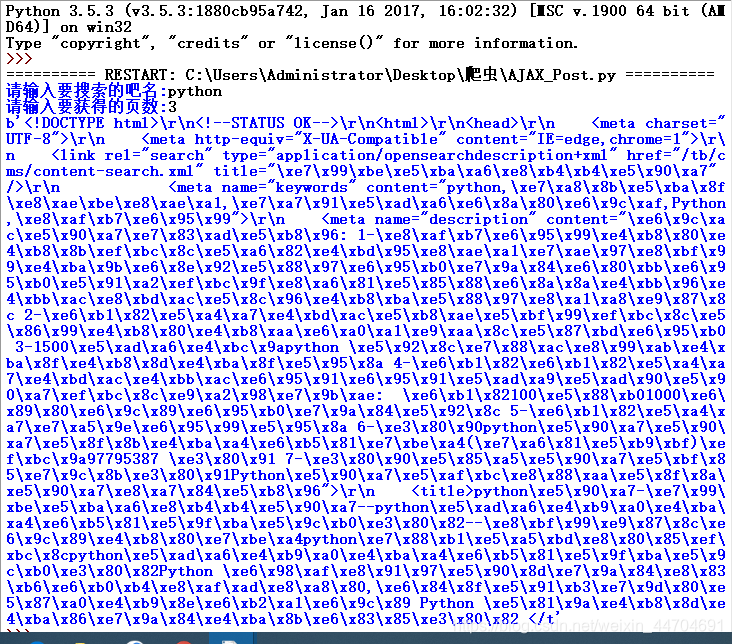
爬取结果
请输入要搜索的吧名: python
请输入要获得的页数: 3

thank you !!!
