
【转载】SqlServer 在线创建索引或在线重建索引(控制最大处理器数 、MAXDOP )
一、什么情况下需要重建索引
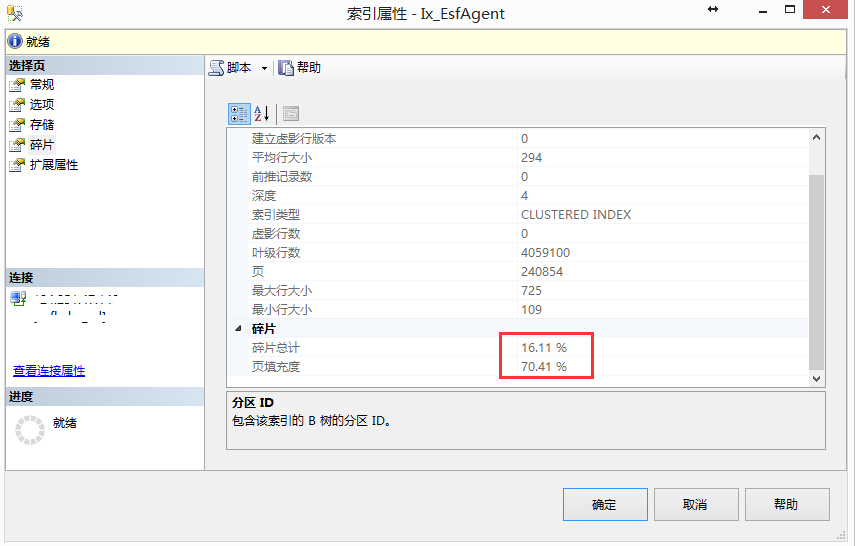
1、碎片过多(参考值:>20%)
索引碎片如何产生,请移步至《 T-SQL查询高级—SQL Server索引中的碎片和填充因子》
2、填充度过低(参考值:<75%)
导致填充度过低的可能原因:①.有删除 ②.有分区表 ③.聚集索引不是数字 ④.数据百万以内,比较少
二、在线创建索引
如果你正在一个存在数据的表上创建新的索引,所有存在的行将会被索引作为CREATE INDEX语句的一部分。如果表非常大,索引过程将会花费些时间。索引过程对其他用户会话的影响,基于SQL Server
是使用Offline模式还是Online模式。
默认,SQL Server以Offline模式执行索引操作,索引操作期间有表锁请求。一个离线索引操作,创建、重建、或删除一个聚集索引,或者重建或删除一个非聚集索引,需要一个表上的架构修改(Sch-M)锁。这阻止了所有用户在操作期间访问相应表。对一个离线索引操作,创建一个非聚集索引,在表上申请一个共享(S)锁。他阻止了对相关表的更新但是允许读操作,例如SELECT语句。
SQL Server Enterprise 版支持在线模式索引操作,其他的用户会话就不会被影响。然而,SQL Server Express 版不支持在线模式,执行报错。SQLServer2005以上版本支持在线索引创建和重建。
CREATE INDEX 索引名 ON 表名(字段) WITH (ONLINE = ON);
三、重建索引
ALTER INDEX 索引名 ON 表名或试图名 REBUILD WITH (ONLINE = ON,MAXDOP = 4)
ONLINE:是否在线执行,减少重建过程中的锁表 (执行时间延长)
MAXDOP :手动配置用于运行索引语句的最大处理器数
| 值 | 说明 |
| 0 | 指定服务器根据当前系统工作负荷确定所使用的 CPU 数目。这是默认值,还是推荐设置。 |
| 1 | 取消生成并行计划。操作将以串行方式执行。 |
| 2-64 | 将处理器的数量限制为指定的值。根据当前工作负荷,可能使用较少的处理器。如果指定的值大于可用的 CPU 数量,将使用实际可用的 CPU 数量。 |
-- 查找数据库碎片率大于40的索引信息 SELECT object_name(object_id) ,index_type_desc,alloc_unit_type_desc,avg_fragmentation_in_percent, fragment_count,avg_fragment_size_in_pages,page_count,record_count, avg_page_space_used_in_percent FROM sys.dm_db_index_physical_stats(DB_ID('数据库名'), OBJECT_ID(''),NULL,NULL,'Sampled') WHERE avg_fragmentation_in_percent>40
mysql数据库 SHOW TABLE STATUS LIKE '表名'; --查询索引碎片 OPTIMIZE TABLE `表名`;--清理索引碎片,会锁表
show OPEN TABLES where In_use > 0; 查看当前哪些表被锁了
SHOW PROCESSLIST; 查看当前正在执行的sql语句 和执行状态
在线整理索引,不锁表https://blog.51cto.com/dadaman/1957229
Data_free为索引碎片字段
出现Table does not support optimize, doing recreate + analyze instead提示使用ALTER TABLE table.name ENGINE='InnoDB';
https://www.kafan.cn/edu/9810546.html
四、扩展笔记:
对于碎片的解决办法 (引用自:宋沄剑 SQL Server索引中的碎片和填充因子)
基本上所有解决办法都是基于对索引的重建和整理,只是方式不同
1.删除索引并重建
这种方式并不好.在删除索引期间,索引不可用.会导致阻塞发生。而对于删除聚集索引,则会导致对应的非聚集索引重建两次(删除时重建,建立时再重建).虽然这种方法并不好,但是对于索引的整理最为有效
2.使用DROP_EXISTING语句重建索引
为了避免重建两次索引,使用DROP_EXISTING语句重建索引,因为这个语句是原子性的,不会导致非聚集索引重建两次,但同样的,这种方式也会造成阻塞
3.如前面文章所示,使用ALTER INDEX REBUILD语句重建索引
使用这个语句同样也是重建索引,但是通过动态重建索引而不需要卸载并重建索引.是优于前两种方法的,但依旧会造成阻塞。可以通过ONLINE关键字减少锁,但会造成重建时间加长.
4.使用ALTER INDEX REORGANIZE
这种方式不会重建索引,也不会生成新的页,仅仅是整理,当遇到加锁的页时跳过,所以不会造成阻塞。但同时,整理效果会差于前三种.
总结:
1、如果数据库当前有客户不断提交数据,使用第三种方式重建索引,亲测不会对用户插入和查询数据有影响(重建索引后,数据库变得更大)
2、如果数据库当前没有在线使用,可以先对数据库进行收缩(选中数据库-》任务-》收缩-》数据库)减小数据库大小后,再使用DBCC DBREINDEX('数据库表名')重建索引,然后清除数据库日志
--查看索引碎片情况 DBCC showcontig('数据库表名') WITH ALL_INDEXES --整表重建索引方式,会锁表,用户不能插入数据 DBCC DBREINDEX('数据库表名') --清理数据库日志 DBCC SHRINKFILE(2)
//查询索引id对应的字段名
SELECT a.name '索引名',a.indid '索引ID',c.name '表名',d.name '列名' FROM sysindexes a JOIN sysindexkeys b ON a.id=b.id AND a.indid=b.indid JOIN sysobjects c ON b.id=c.id JOIN syscolumns d ON b.id=d.id AND b.colid=d.colid WHERE a.indid NOT IN(0,255) AND c.name='要查询的表名' --查指定表
1. 填充因子
在向索引中添加新行时容易发生分页,不仅在页拆分时会降低性能,还会导致产生过多的索引碎片(内部碎片)。
SQL Server允许在创建索引时指定一个填充因子,以便在索引的每个叶级页上留出额外的间隙和保留一定百分比的空间,减少页拆分的可能性。
填充因子的值是从 0 到 100 之间的百分比数值,指定在创建索引后对数据页的填充比例。值为 0或100 时表示页将填满,所留出的存储空间量最小。只有当不会对数据进行更改时(例如,在只读表中)才会使用此设置。值越小则数据页上的空闲空间越大,这样可以减少在索引增长过程中对数据页进行拆分的需要,但需要更多的存储空间。当表中数据会频繁发生更改时,这种设置更为适当。
2. 通过脚本修改填充因子并重建索引
ALTER INDEX IX_person2_UserID ON person2 REBUILD WITH (FILLFACTOR = 60)
https://www.cnblogs.com/hanmos/archive/2011/03/28/1998054.html
一般的填充因子设置策略:
数据变化越频繁,填充因子越小
数据越少变化,填充因子越大
对于数据不变化的表,填充因子设置为100
原文地址:
https://www.cnblogs.com/hydor/p/5254292.html
http://blog.51cto.com/ultrasql/1737335
https://cloud.tencent.com/developer/article/1342498
设置定时执行步骤
(1)启动【sql server Management Studio】,在【对象资源管理器】窗口里选择【管理】——【维护计划】选项。
(2)右击【维护计划】,在弹出的快捷菜单里选择【维护计划向导】选项,弹出如图所示的【维护计划向导】对话框,单击【下一步】按钮
(3)弹出如图所示【选择目标服务器】对话框,在【名称】文本框里可以输入维护计划的名称;在【说明】文本框里可以输入维护计划的说明文字;【在服务器】文本框里可以输入要使用的服务器名;最后选择正确的身份证信息,单击【下一步】按钮。
(4)弹出如图所示【选择维护任务】对话框,在该对话框中可以选择执行sql维护任务,插入执行存储过程语句
(5)制定任务执行计划
不指定sql语句全局方法
重新生成索引任务,可不锁表和锁表
https://docs.microsoft.com/zh-cn/sql/relational-databases/maintenance-plans/rebuild-index-task-maintenance-plan?view=sql-server-ver15
重新组织索引任务,不锁表
https://docs.microsoft.com/zh-cn/sql/relational-databases/maintenance-plans/reorganize-index-task-maintenance-plan?view=sql-server-ver15
https://www.cnblogs.com/flysun0311/archive/2013/12/05/3459451.html
alter index来rebuild和reorganize索引来清除碎片,rebuild能够完全清除碎片,但是reorganize却不能。
online模式下
rebuild index会复制旧索引来新建索引,此时旧的索引依然可以被读取和修改,但是所以在旧索引上的修改都会同步更新到新索引下。中间会有一些冲突解决机制,具体参考Online Index Operations 里面的Build Phase这一章节。然后在rebuild这个过程完整的时候,会对table上锁一段时间,在这段时间里会用新索引来替换旧索引,当这个过程完成以后再释放table上面的锁。如果索引列包含 LOB对象的话,在SQL Server 2005/2008/R2中rebuild index online会失败。在sql server 2012中,即使索引列包含LOB对象,也可以rebuild index online了,可以参考 Online Index Operations for indexes containing LOB columns.
offline模式下
rebuilde index会对table上锁,所有对这个table的读写操作都会被阻塞,在这期间新索引根据旧索引来创建,其实就是一个复制的过程,但是新索引没有碎片,最后使用新索引替换旧索引。当rebuild整个过程完成以后,table上面的锁才会被释放。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号