
不止Oracle 读书笔记
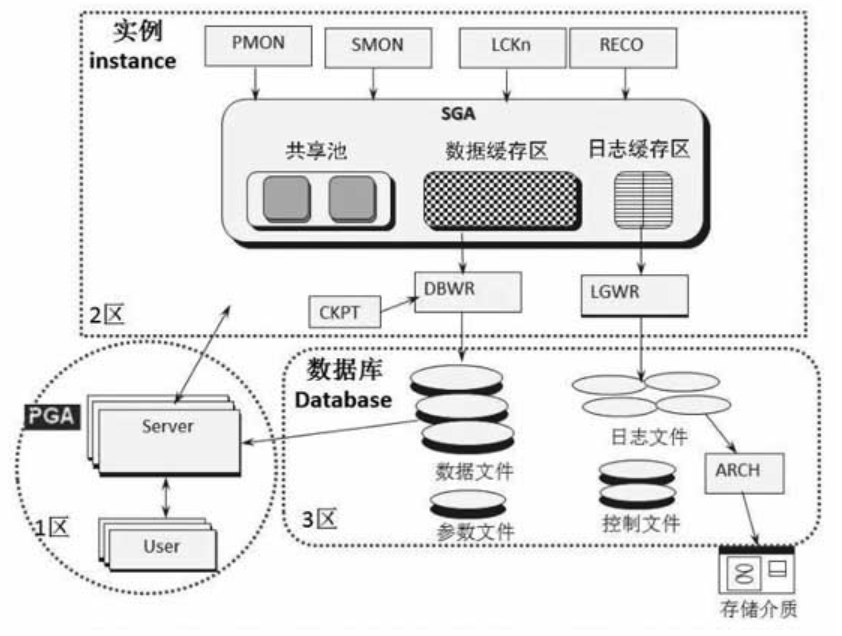
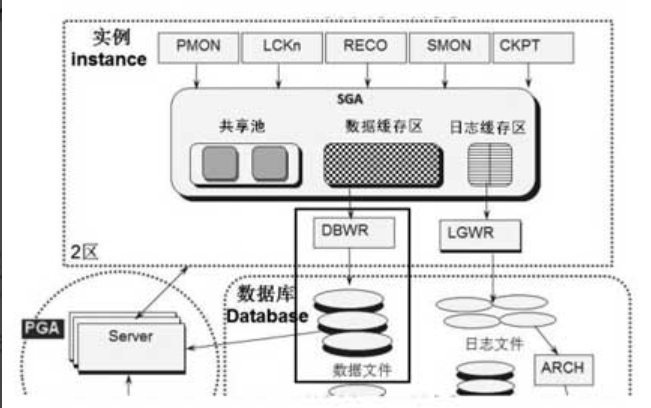
Oracle由实例和数据库组成,上半部的直角方框为实例instance,下半部的圆角方框为数据库Database。
实例是由一个共享内存区SGA(System Global Area)和一系列后台进程组成的,其中SGA主要被划分为共享池(shared pool)、数据缓存区(db cache)和日志缓存区(log buffer)三类。
后台进程包括PMON、SMON、LCKn、RECO、CKPT、DBWR、LGWR、ARCH等系列进程。
数据库是由数据文件、参数文件、日志文件、控制文件、归档日志文件等一系列文件组成的,其中归档日志最终可能会被转移到新的存储介质中,用于备份恢复使用。
PGA(Program Global Area)区,这也是一块内存区,和SGA最明显的区别在于,PGA不是共享内存,是私有不共享的。用户对数据库发起的无论查询还是更新的任何操作,都先在PGA进行预处理,然后才进入实例区域,由SGA和后台进程共同完成。
PGA 起到的具体作用主要有三点:
第一,保存用户的连接信息,如会话属性、绑定变量等;
第二,保存用户权限等重要信息,当用户进程与数据库建立会话时,系统会将这个用户的相关权限查询出来,然后保存在这个会话区内;
第三,当发起的指令需要排序的时候,PGA(Program Global Area)正是这个排序区,如果在内存中可以放下排序的尺寸,就在内存PGA区内完成,如果放不下,超出的部分就在临时表空间中完成排序,也就是在磁盘中完成排序。
一条SQL语句查询的过程
select object_name from t where object_id=29;,当你发出这条SQL语句后,该SQL语句从1区先做准备工作。
该SQL指令还会立即匹配成一条唯一的hash值,接下来该SQL指令进入2区进行处理,首先敲开SGA区的共享池的大门。
“共享池的大门打开了,该SQL指令先在房内查询是否什么地方存储过这个SQL指令的身份证(就是那个唯一的 hash 值)。
如果没有,那就要辛苦了。首先查询自己的语句语法是否正确(比如from是否写成了form)、语义是否正确(比如id字段根本就不存在)、是否有权限,在这些都没问题的情况下生成这条语句的身份证,唯一的hash值就被存储下来了。接下来开始进行解析,解析什么呢?比如select object_name from t where object_id=29;这条语句,在object_id列有索引的情况下,是用索引读更高效,还是全表扫描更高效呢?Oracle要做出选择。Oracle处理这件事情的依据很简单,就是把两种方式都估算一遍,看哪个代价(Cost)更低,就用哪种。假设Oracle认定使用索引代价(Cost)更低,于是Oracle就选用了索引读的执行计划而放弃了全表扫描方式。接下来这个索引读的执行计划就立即被存储起来,并且和之前存储的该SQL指令的身份证(唯一hash值)对应在一起。
该 SQL 指令好比钦差大臣一样,手持‘索引读获取某某数据’这个圣旨,继续往前走,它这是要去哪呢?原来是直奔‘数据缓存区’府内去宣读圣旨了。

数据缓存区根据ID列上的索引从t表中查找object_id值为29的宝物,但是所要的东西府内找不到,怎么办呢?数据缓存区府只好传令下去,八百里加急赶去偏远的Database军营的数据文件区去查找皇上要的东西。如果查到了,就带回数据缓存区府,并由钦差大臣展现给皇上,如果找不到,也只有就此复命。
一个SQL命令运行两次的实验
et autotrace on 是开始跟踪SQL指令的执行计划和执行的统计信息,而set timing on 是表示跟踪该语句执行完成的时间。这些都准备好了,最后关键语句select object_name from t where object_id=29
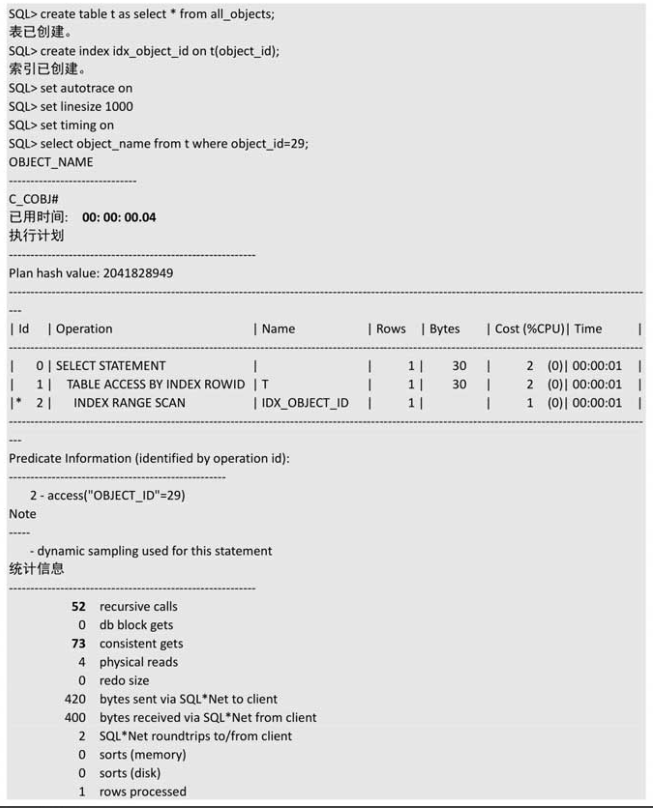
第一次结果
第二次结果
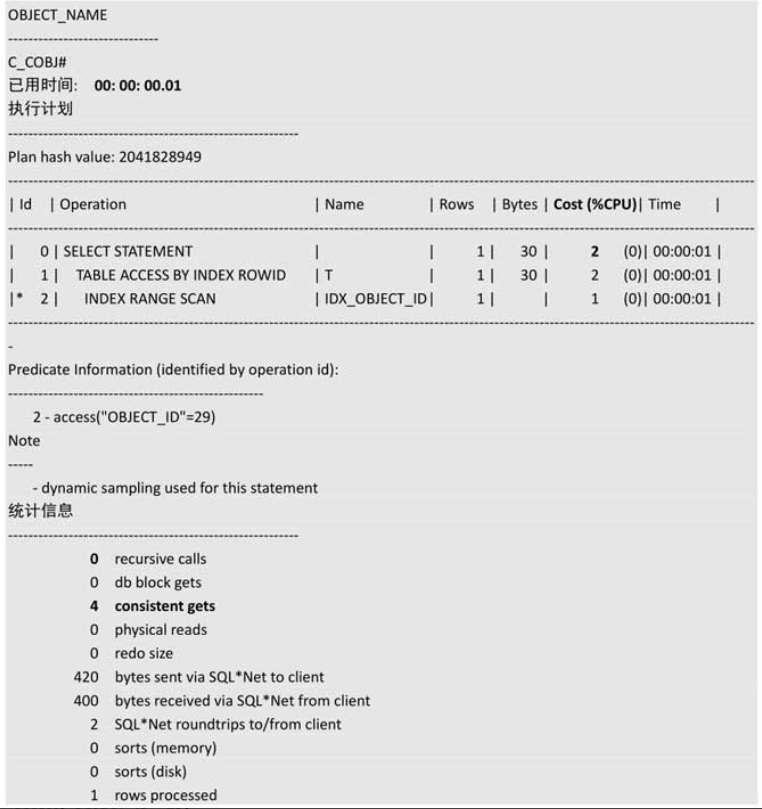
第一,用户首次执行该SQL指令时,该指令从磁盘中获取用户连接信息和相关权限信息,并保存在PGA内存里。当用户再次执行该指令时,由于SESSION之前未被断开重连,连接信息和相关权限信息就可以从PGA内存中直接获取,避免了物理读。
第二,首次执行该SQL指令结束后,SGA内存区的共享池里已经保存了该SQL指令唯一的hash值,并保留了语法语义检查及执行计划等相关解析动作的劳动成果,当再次执行该SQL指令时,由于该 SQL指令的hash值和共享池里保存的相匹配,所以之前的硬解析动作无须再做,不仅跳过了相关语法语义检查,对于该选取哪种执行计划也无须考虑,直接拿来就好。
第三,首次执行该 SQL 指令时,数据一般不在 SGA 的数据缓存区里(除非被别的 SQL读入内存了),只能从磁盘中获取,不可避免地产生了物理读,但是由于获取后会保存在数据缓存区里,再次执行时可直接从数据缓存区里获取,完全避免了物理读,大家可以注意到我们的试验,首次执行的物理读为4,第2次执行的物理读居然为0,没有物理读,数据全在缓存中,效率当然高得多!
DBWR
在数据缓存区内修改完数据后,会启用DBWR进程,完成更新的数据从内存中刷入磁盘
LGWR & ARCH
日志缓存区保存了数据库相关操作的日志,记录了这个动作,然后由 LGWR后台进程将其从日志缓存区这个内存区写进磁盘的日志文件里。目的很简单,就是为了便于将来出现异常情况时,可以根据日志文件中记录的动作,再继续执行一遍,从而保护数据的安全。

LGWR运行的频率:
一、每隔三秒,LGWR运行一次。
二、任何COMMIT触发LGWR运行一次。
三、DBWR要把数据从数据缓存写到磁盘,触发LGWR运行一次。
四、日志缓存区满三分之一或记录满1MB,触发LGWR运行一次。
五、联机日志文件切换也将触发LGWR。
ARCH进程,它的作用是在LGWR写日志写到需要被覆盖重写的时候,触发ARCH进程去转移日志文件,将日志文件复制出去形成归档日志文件,以免日志丢失。
DBWR写入频率
在数据库运行的过程中,批量刷出的数据占数据缓存区的比例越大,一般来说效率越高,而且也不用担心断电后的恢复问题。可是大家想想看,如果批量刷出的数据占数据缓存区的比例很大,那断电后数据库重启的恢复数据的动作必然需要的时间更长,因此很多时候要考虑一个平衡问题:批量刷出的量比较小,Oracle性能就会降低,但是断电开机恢复的时间就较短;反之,批量刷出的量比较大,Oracle 性能是更高了,但是断电开机恢复的时间也较长。
CheckPoint CKPT
什么时候将数据缓存区中的数据写到磁盘的动作正是由进程CKPT来触发的,CKPT触发DBWR写出。

我们可以通过设置某参数来控制CKPT的触发时间,万一出现数据库崩溃,希望最多用多长时间来做实例恢复,该参数就是FAST_START_MTTR_TARGET,通过调整该参数,Oracle会调配CKPT在适当的时候去调用DBWR.
SQL> show parameter fast start
NAME TYPE VALUE
------------------------------------ ----------- ------------------------------
_fast_full_scan_enabled boolean TRUE
fast_start_io_target integer 0
fast_start_mttr_target integer 0
fast_start_parallel_rollback string LOW
在 CKPT 的触发或者说命令下,DBWR将数据缓存区中的数据写到磁盘,但是如果LGWR出现故障了,DBWR此时还是会不听CKPT的命令罢工的,因为Oracle 在将数据缓存区中的数据写到磁盘前,会先进行日志缓存区写进日志文件的操作,并耐心地等待其先完成,才会去完成这个‘内存刷到磁盘’的动作,这就是所谓的凡事有记录。
PMON
PMON的含义为Processes Monitor,是进程监视器。如果你在执行某些更新语句,未提交时进程崩溃了,这时候PMON会自动回滚该操作,无须人工去执行ROLLBACK命令。除此之外它还可以干预后台进程,比如RECO出现异常失败了,此时PMON会重启RECO进程,如果遇到LGWR进程失败这样的严重问题,PMON会做出中止实例这个激烈的动作,用于防止数据错乱。
SMON
SMON的含义为System Monitor,可理解为系统监视器。与PMON不同的是,SMON关注的是系统级的操作而非单个进程,工作重点在于实例恢复,除此之外还有清理临时表空间、清理回滚段表空间、合并空闲空间等功能。
LCKn
LCKn仅用于RAC数据库,最多可有10个进程(LCK0,LCK1,…,LCK9),用于实例间的封锁。
RECO
RECO用于分布式数据库的恢复,全称是Distributed Database Recovery,适用于两阶段提交的应用场景。这里我简单描述一下,比如我们面临多个数据库A、B、C,某个应用跨越三个数据库,在发起的过程中需要A、B、C库都提交成功,事务才会成功,只要有一个失败,就必须全部回滚。
LRRG
将数据库服务注册到监听,轮询每60秒.
数据回滚
1.想更新object_id=29的记录,首先需要查到object_id=29的记录,检查object_id=29是否在数据缓存区里,不存在则从磁盘中将其读取到数据缓存区中,这一点和普通的查询语句类似。
2.但是这毕竟不是查询语句而是更新语句,于是要做一件和查询语句很不同的事,在回滚表空间的相应回滚段事务表上分配事务槽,从而在回滚表空间分配到空间。该动作需要记录日志写进日志缓存区。
3.在数据缓存区中创建 object_id=29的前镜像,前镜像数据也会写进磁盘的数据文件里(回滚表空间的数据文件),从缓存区写进磁盘的规律前面已经说过了,由CKPT决定,当然也别忘记这些动作都会记录日志,并将其写进日志缓存区,劳模LGWR还在忙着将日志缓存区中的数据写入磁盘形成redo文件呢。
4.前面的步骤做好了,才允许将object_id=29修改为object_id=92,这个显然也是要记录进日志缓存区的。
5.此时用户如果执行了提交,日志缓存区立即要记录这个提交信息,然后就把回滚段事务标记为非激活INACTIVE状态,表示允许重写。
6.如果是执行了回滚呢,Oracle需要从回滚段中将前镜像object_id=29的数据读出来,修改数据缓存区,完成回滚。这个过程依然要产生日志,要将数据写进日志缓存区。
普通数据操作可能会出现事务已经COMMIT了,但是数据在数据缓存区中并没有立即被刷新到磁盘,数据丢失后需要依据redo来重做的场景。回滚前镜像数据也是如此,你也需要用日志记录相关前镜像的操作来应对用户需要回滚的情况,否则当回滚的前镜像数据既不在内存又不在磁盘的情况出现后(比如突然断电等),依据记录了前镜像相关操作的日志来重新做一次还原前镜像的操作。
回滚段的相关参数,其中undo_management为AUTO表示是自动进行回滚段管理,回滚段空间不够时可以自动扩展;undo_retention 为900的含义是,DML语句需要记录前镜像,当 COMMIT 后,表示回滚段保留的前镜像被打上了可以覆盖重新使用的标记,但是要在900秒后方可允许;undo_tablespace为UNDOTBS1就不用多解释了,表示回滚段表空间的名字为UNDOTBS1。
SQL> show parameter undo
NAME TYPE VALUE
------------------------------------ ----------- ------------------------------
undo_management string AUTO
undo_retention integer 900
undo_tablespace string UNDOTBS1
posted on 2022-12-22 22:04 LeoZhangJing 阅读(70) 评论(0) 编辑 收藏 举报
