
推荐系统
一、协同过滤
# -*- coding: utf-8 -*- """ 参考链接:https://www.cnblogs.com/190260995xixi/p/5940356.html
这个链接原理很清楚:https://www.cnblogs.com/yangxiao99/p/4459595.html
https://blog.csdn.net/ygrx/article/details/15501679
数据下载:http://files.grouplens.org/datasets/movielens/ml-100k.zip 项目介绍: 基于协同过滤的算法做电影的评分,使用两种协同过滤,分别是usercf和itemcf 步骤: 1、构建用户-项目的评分矩阵,或者项目-用户的评分矩阵 2、计算用户或者项目之间的相似性,构造用户-用户相似矩阵,项目项目相似矩阵 3、计算预测矩阵,两种,一种是用户项目预测矩阵,一种项目用户预测矩阵 4、把预测的样本代入预测 """ import numpy as np import pandas as pd from sklearn.model_selection import train_test_split from sklearn.metrics.pairwise import pairwise_distances from sklearn.metrics import mean_squared_error #读取数据 df = pd.read_csv('ml-100k/u.data',sep='\t',names=['user_id','item_id','rating','timestamp']) n_users = df.user_id.value_counts().count() n_items = df.item_id.value_counts().count() #df.user_id.value_counts().count() 943个用户 #df.item_id.value_counts().count() 1682个项目 #切分训练集测试集 train,test = train_test_split(df,train_size = 0.7) #创建user_item矩阵 train_data_matrix = np.zeros((n_users,n_items)) for line in train.itertuples(): train_data_matrix[line[1]-1,line[2]-1] = line[3] test_data_matrix = np.zeros((n_users,n_items)) for line in test.itertuples(): test_data_matrix[line[1]-1,line[2]-1] = line[3] #计算余弦相似度 user_similarity = pairwise_distances(train_data_matrix,metric='cosine') item_similarity = pairwise_distances(train_data_matrix.T,metric='cosine') #计算预测矩阵 def predict(ratings,similarity,type='user'): if type=='user': diff = ratings-ratings.mean(axis=1)[:,np.newaxis] pred = ratings.mean(axis=1)[:,np.newaxis] + similarity.dot(diff)/np.array(np.abs(similarity).sum(axis=1))[:,np.newaxis] if type == 'item': pred = ratings.dot(similarity)/np.array([np.abs(similarity).sum(axis=1)]) return pred item_prediction = predict(train_data_matrix,item_similarity,type='item') user_prediction = predict(train_data_matrix, user_similarity, type='user') #预测并且评估 def rmse(prediction, ground_truth): prediction = prediction[ground_truth.nonzero()].flatten() ground_truth = ground_truth[ground_truth.nonzero()].flatten() return np.sqrt(mean_squared_error(prediction, ground_truth)) print(rmse(item_prediction,test_data_matrix)) print(rmse(user_prediction,test_data_matrix))
二、重新整理,梳理协同过滤
import numpy as np import pandas as pd from sklearn.metrics.pairwise import pairwise_distances from sklearn.metrics.pairwise import paired_cosine_distances data = pd.read_csv('./ml-1m/ratings.dat',sep='::',names=['uid','mid','score','timestamp']) df = data.head(1000)
先只选取部分数据来做验证看看
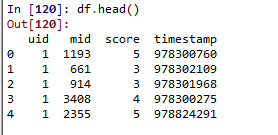
user_item = pd.pivot_table(df,index='uid',columns='mid',values='score',fill_value=0) item_user = pd.pivot_table(df,index='mid',columns='uid',values='score',fill_value=0)
用数据透视表来构造用户-项目,项目-用户矩阵
user_similarity = pairwise_distances(user_item,metric='cosine') item_similarity = pairwise_distances(item_user,metric='cosine')
计算用户用户相似度矩阵,项目项目相似度矩阵
通过计算出来的相似度矩阵,来计算用户对项目的评分,以用户-项目为例
已经有了用户-项目矩阵,然后也计算了用户用户的相似度,
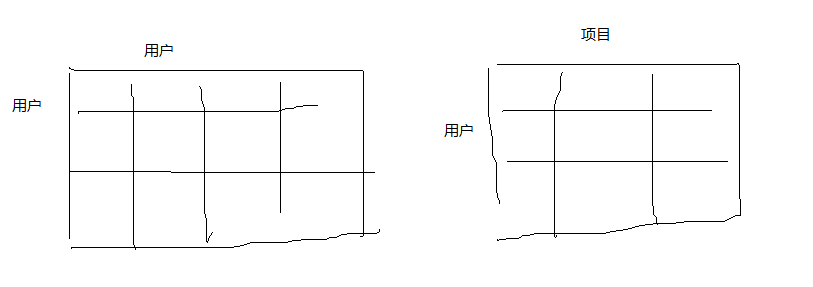
以上两个矩阵相乘就会得到用户项目的矩阵,里面的每个数值分别是由跟他相似的用户一同加权得到的分数,这里理解一下矩阵相乘。
但是有一个问题,每个用户评分都不一样,可能有的都评高分,有的都是低分,所以要做一些处理
用户的评分均值(代表这个用户到底是会评分高还是低) + 用户-用户相似矩阵 * (用户-项目矩阵 - 用户评分均值)/(用户用户相似矩阵的加和)
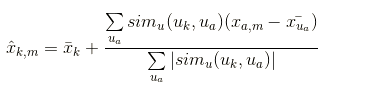
这样计算出来的分数就对了

 浙公网安备 33010602011771号
浙公网安备 33010602011771号