
卷积神经网络—第三周
一、目标定位
目标定位从标准的CNN图像分类出发,在这个基础上又增加了更多的y值,比如

PC表示图片中是否有检测物,如果有是1,否是0
bx,by,bh,bw分别是定位矩形区域参数
c1,c2,c3表示定位出来的物品属于哪个类别
注意,如果pc是-,后面就没有意义,就全部不关心
损失函数:
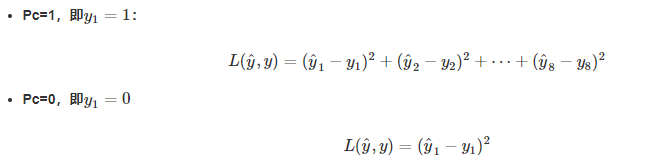
二、特征点检测
除了用矩形框选出区域,我们哈可以对关键点定位,输入每个关键点的x,y坐标来定位,比如第一个为是否是人脸,然后后面一次是每个关键点的横坐标,纵坐标

三、目标检测
目标检测采用的滑动窗口法,首选搜集很多的图片,包括有车的,没车的。但是图片里面的汽车要占据整个图片,然后用这些图片来训练一个cnn模型,得到最终的模型

然后再测试图片上面,选择合适的大小窗口和步长,进行滑动遍历整张图片,每次滑动方框中的图片就输入到CNN中,判断是否有车子,最终都遍历完都没车,那就是没车,如果有就有
这种方法的计算代价很大,并且滑动窗口大小和步长需要人为确定。

四、卷积的滑动窗口实现
由于前面计算代价很大,因此我们可以使用卷积的方式来处理,单个滑动窗口区域的全连接层转化成卷积层如下
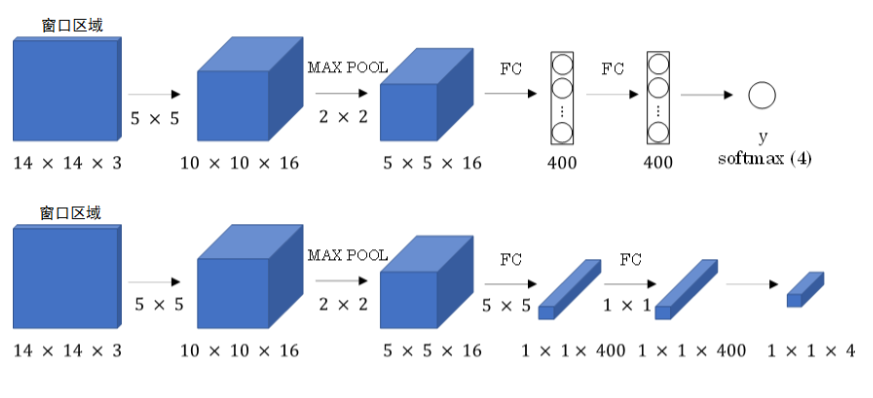
这个是单个窗口建立模型,也就是训练数据建立的模型
在检测图片上:同样用一样的卷积方式处理后会发现得到的是一个更大一点的图,图中每一个块代表了滑动过程中选择的区域。这里滑动步长是2,因为max_pool为2,要更改步长直接更改max_pool就可以了

五、bounding box预测
由于滑动窗口有可能会出现无法刚好覆盖目标的情况,因此这里出现了yolo算法,通过把检测图片划分成小块,每块来做检测,最后生成n*n*8的图片,
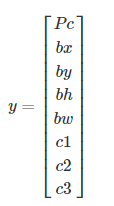
每个网格中包含八个数字,第一个是否有目标检测物,第二个第三个是中心点坐标,yolo中中心店左边的原点是该小单元格从0-1,bh,bw分别是一个小格子长宽的比例,比如200%宽度,这个可以超过1
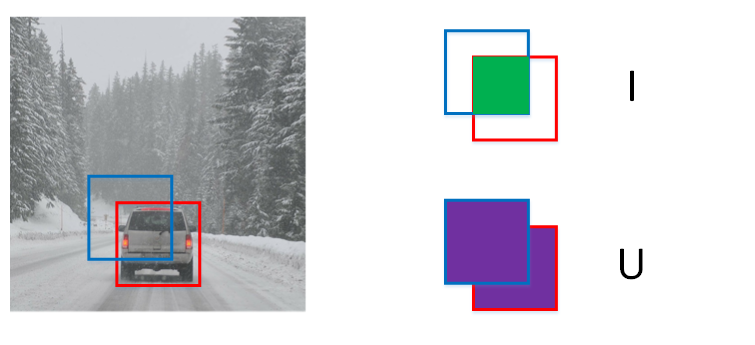
六、交并比
用来评价目标区域检测的准确性

七、非最大值抑制算法
在yolo算法中可能会多个网格都会检测到有目标存在,但是其实是同一个目标,所以就需要用非最大值抑制算法,
算法步骤:
1、先选择出最大的pc值的网格,
2、计算这个区域跟其他区域的iou值,剔除掉iou值比较大的区域
3.在选择出最大值的PC网格
4、重复第二步
这样就能够把多个不同的目标检测出来,又不至于一个目标检测多次

八、anchor boxes
前面介绍的都是一个网格检测一个目标的情况,如果在一个网格中出现了多个目标呢,这时候就要不同形状的anchor boxes
在anchor boxes为2的时候,我们的输出不再是3*3*8了而是3*3*2*8,然后查看检测区域与那个anchor boxes的iuo更大,就属于哪个anchorboxes
九、yolo算法
十、RPN网络

 浙公网安备 33010602011771号
浙公网安备 33010602011771号