
卷积神经网络—第一周
一、计算机视觉
包括三个部分:
1、图像分类(猫狗识别)
2、目标检测(比如自动驾驶目标检测)
3、图像神经风格转化,两个图片的风格进行融合

二、边缘检测示例
常见的有两种边缘检测:垂直边缘检测和水平边缘检测
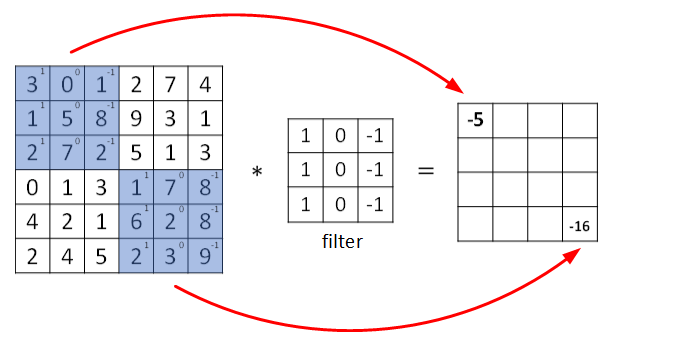
1、卷积的运算过程是这样的:
有一张图片,有一个滤波器(或者叫卷积核),然后两个进行卷积计算,得到新的图片,卷积运算就是对应相乘相加
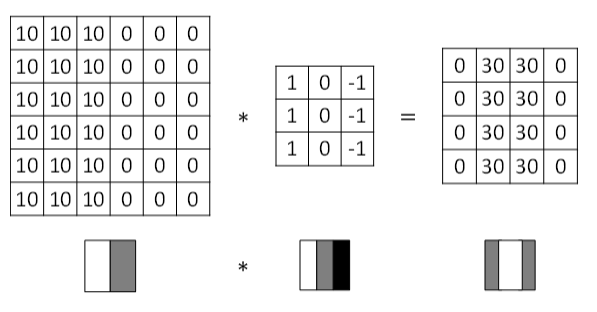
2、比如垂直边缘检测,用以下的滤波器(数字比较大的话比较亮),通过特殊卷积核的计算,就可以突出图片的边缘部分
三、更多边缘检测
除了有垂直的、水平的边缘检测,通过不同的滤波器会有更多的检测,比如偏向中心的检测
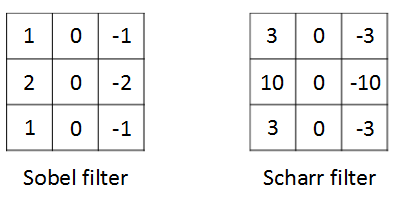
然而现在我们并不需要手动去写这些滤波器,而是通过把这些参数作为w来通过反向传播学习得到,这样的效果会更好
四、Padding
一个n*n的图片经过f*f的滤波器处理后会变成n-f+1 * n-f+1的图片,这就导致两个问题
1、图片变小了,如果神经网络层数越来越多,会越来越小
2、边缘部分的信息用到很少
卷积的方式两种:
1、valid:不填充
2、使用0的像素填充周边一圈,填充的p = (f-1)/2,这样就能够让卷积之后的图像与没卷积的一样大,这个叫same
通常使用基数比如3*3,5*5的过滤器,因为这里的p = (f-1)/2奇数除的断
五、卷积步长
步长(stride)表示过滤器在图片中每次水平或者垂直移动的步长,前面我们都是1,如果添加步长,那么最终得到的图片大小如下公式
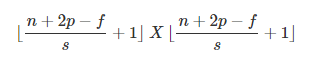
六、在多通道上的卷积
对于3通道的RGB图片,我们同样可以使用3通道的过滤器来进行卷积,然后把这三个过滤器结果加起来得到最终的图片(6*6*3和3*3*3的过滤器得到4*4的图片,注意这里图片只是4*4)
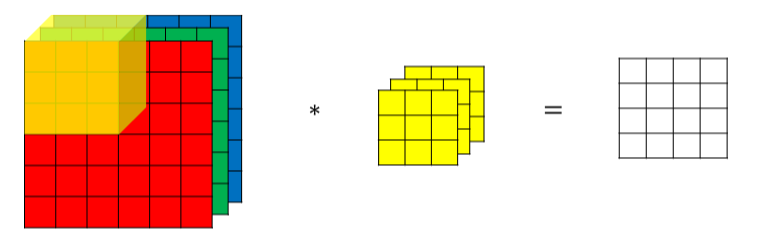
如果我们不仅要在垂直方向上检测,还有水平呢,这就可以使用多个过滤器
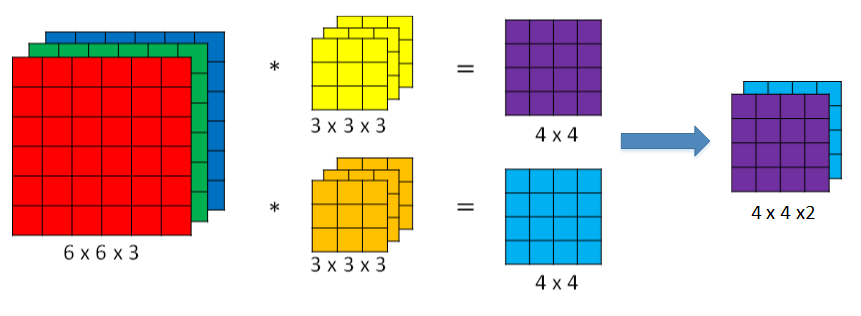
每个过滤器得到的结果,叠加在一起就得到最终的4*4*2

七、单层卷积网络
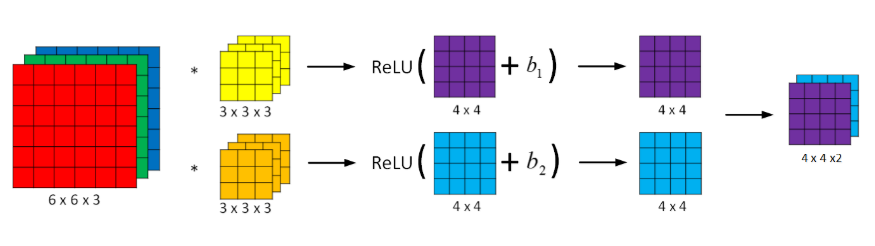
卷积网络的结构如下,其实这个和普通的神经网络是类似的

以上的式子的参数一共有多少个呢:3*3*3 = 27个,加上偏置1个,等于28个,两个过滤器一共56个参数,也就是不管图片多大,我们都只有五十几个参数,这样就大大减小了过拟合的问题。
以下总结一下CNN的标记

八、简单卷积网络示例
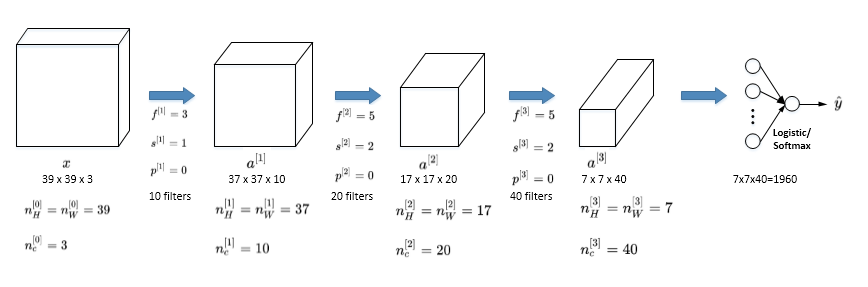
使用前面的那些概念,我们很容易把一个长宽比较大,厚度比较小的变成最后的长宽比较小,厚度比较大的图片,然后再把图片拉长,最后套一个logistic或者softmax形成最终的预测值
CNN通常有三层,分别是:
1、卷积层 convolution conv
2、池化层 pooling pool
3、全连接层 fully connected fc
九、池化层
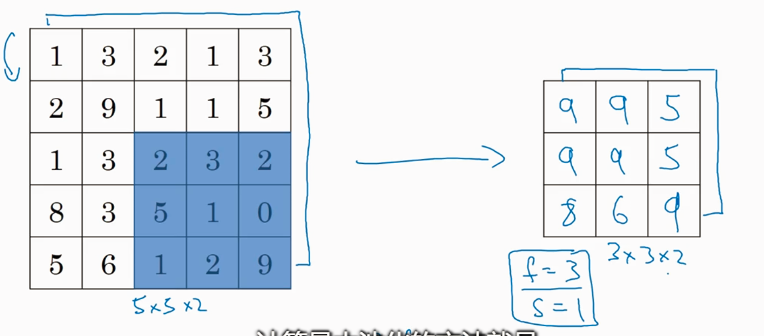
池化层很简单,这里演示的是max_pooling,就是当过滤器窗口滑动过程中选择最大值就可以,如果有多个,通道,同样最后的结果也是多个通道
除了max_pooling,还有average_pooling不过不常用
池化层的参数很少,只要确定过滤器的大小,和stride步长就可以,池化层很少用到padding
十、卷积神经网络示例
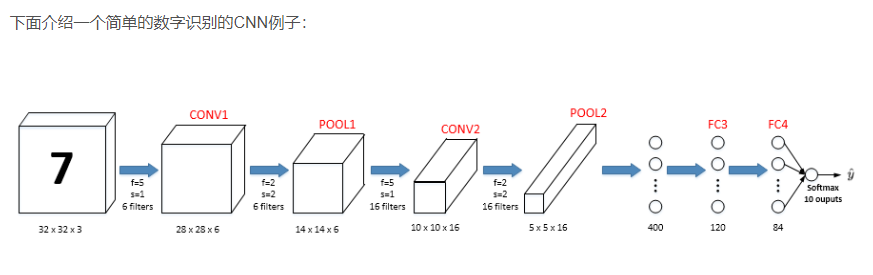
一个卷积层跟着一个池化层,最后再连接全连接层,整个网络的参数如下
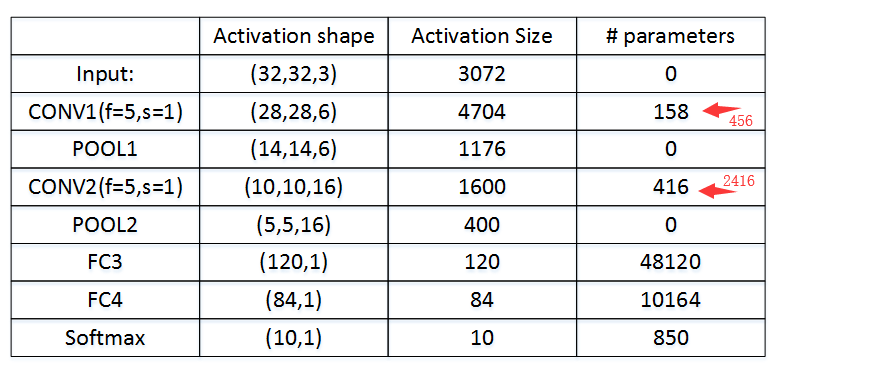
conv1:5*5*3*6+6 = 456
conv2:5*5*6*16+16=2416
fc3 = 5*5*16 = 400 然后400*120+120 = 48120
fc4 = 120*84+84 = 10164
sofgmax:84*10+10
十一、为什么使用卷积
相比标准神经网络,CNN的优势之一就是参数数目要少得多。参数数目少的原因有两个:
-
参数共享:一个特征检测器(例如垂直边缘检测)对图片某块区域有用,同时也可能作用在图片其它区域。
-
连接的稀疏性:因为滤波器算子尺寸限制,每一层的每个输出只与输入部分区域内有关。
除此之外,由于CNN参数数目较小,所需的训练样本就相对较少,从而一定程度上不容易发生过拟合现象。而且,CNN比较擅长捕捉区域位置偏移。也就是说CNN进行物体检测时,不太受物体所处图片位置的影响,增加检测的准确性和系统的健壮性。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号