
Python 数据分析—第七章 数据归整:清理、转换、合并、重塑
一、数据库风格的Dataframe合并
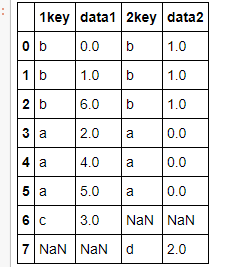
import pandas as pd import numpy as np df1 = pd.DataFrame({'1key':['b','b','a','c','a','a','b'], 'data1':np.arange(7)}) df2 = pd.DataFrame({'2key':['a','b','d'], 'data2':np.arange(3)}) df1 df2


pd.merge(df1,df2,left_on='1key',right_on = '2key',how='outer') #how还可以选择left right inner 还有一个参数是suffixes对于重复的名字处理 suffixes = ('_left','_right') #有时候是通过index连接的这里用left_index = True right_index = True
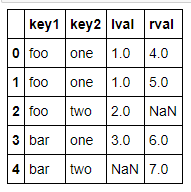
#可以通过两个键来做merge pd.merge(left,right,on=['key1','key2'],how='outer')
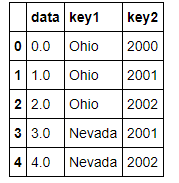
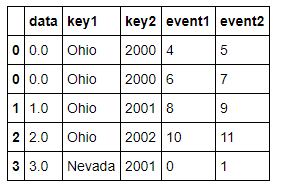
lefth = pd.DataFrame({'key1': ['Ohio', 'Ohio', 'Ohio', 'Nevada', 'Nevada'],
'key2': [2000, 2001, 2002, 2001, 2002],
'data': np.arange(5.)})
righth = pd.DataFrame(np.arange(12).reshape((6, 2)),
index=[['Nevada', 'Nevada', 'Ohio', 'Ohio', 'Ohio', 'Ohio'],
[2001, 2000, 2000, 2000, 2001, 2002]],
columns=['event1', 'event2'])
lefth
righth
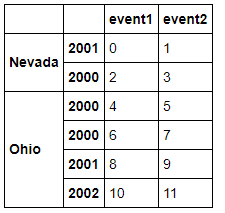
#多重索引的合并,需要指定多个值 pd.merge(lefth,righth,left_on=['key1','key2'],right_index=True)
二、轴向连接
s1 = pd.Series([0, 1], index=['a', 'b']) s2 = pd.Series([2, 3, 4], index=['c', 'd', 'e']) s3 = pd.Series([5, 6], index=['f', 'g']) pd.concat([s1,s2,s3]) pd.concat([s1,s2,s3],axis=1)


s4 = pd.concat([s1*5,s3]) s4 pd.concat([s1,s4],axis=1) pd.concat([s1,s4],axis=1,join='inner')
通过join来选择拼接模式,其实这个就跟merge差不多


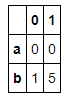
pd.concat([s1,s2,s4],keys=['one','two','three'])
pd.concat([s1,s2,s4],axis = 1,keys=['one','two','three'])
pd.concat({'one':s1,'two':s2,'three':s3},axis = 1) #这个结果跟上面那个一样的!
这个可以增加一个层次化索引,这个跟你axis有关系,

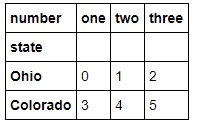
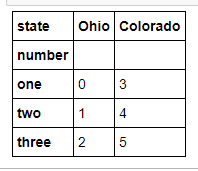
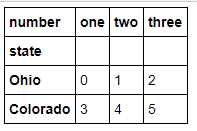
data = pd.DataFrame(np.arange(6).reshape((2, 3)), index=pd.Index(['Ohio', 'Colorado'], name='state'), columns=pd.Index(['one', 'two', 'three'], name='number')) data
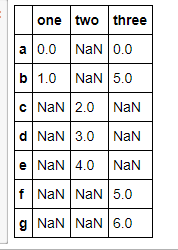
data.stack() temp = data.stack() temp.unstack(0) temp.unstack() #后面跟的数字看看差别就知道,其实这样就相当于装置.T

数据转换
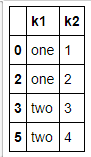
data = pd.DataFrame({'k1': ['one'] * 3 + ['two'] * 4,
'k2': [1, 1, 2, 3, 3, 4, 4]})
data
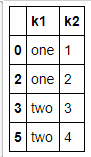
data[~data.duplicated()]
data.drop_duplicates() #里面可以指定列['k1'] 默认保留第一个,传入take_lase = True 保留最后一个
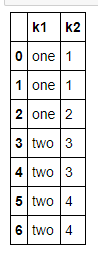
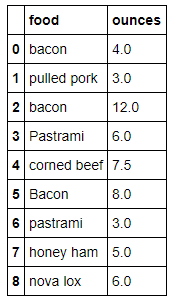
data = pd.DataFrame({'food': ['bacon', 'pulled pork', 'bacon', 'Pastrami',
'corned beef', 'Bacon', 'pastrami', 'honey ham',
'nova lox'],
'ounces': [4, 3, 12, 6, 7.5, 8, 3, 5, 6]})
data
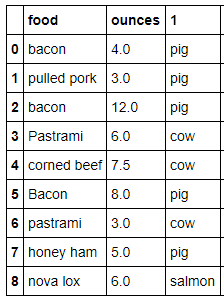
meat_to_animal = {
'bacon': 'pig',
'pulled pork': 'pig',
'pastrami': 'cow',
'corned beef': 'cow',
'honey ham': 'pig',
'nova lox': 'salmon'
}
data['1'] = data['food'].map(str.lower).map(meat_to_animal)
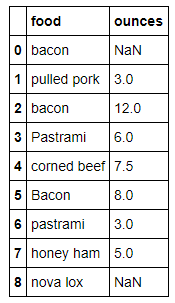
data.replace(-999,np.nan) #data.replace([-999,1000],np.nan) 在dataframe上面也是一样的
ages = np.arange(10,80,10) ages pd.cut(ages,bins=[10,30,50,71],right=False,labels=['a','b','c'])

df = pd.DataFrame({'key': ['b', 'b', 'a', 'c', 'a', 'b'],
'data1': range(6)})
pd.get_dummies(df['key'])


 浙公网安备 33010602011771号
浙公网安备 33010602011771号