
Python 数据分析—第九章 数据聚合与分组运算
打算从后往前来做笔记
第九章 数据聚合与分组运算
分组
#生成数据,五行四列 df = pd.DataFrame({'key1':['a','a','b','b','a'], 'key2':['one','two','one','two','one'], 'data1':np.random.randn(5), 'data2':np.random.randn(5)}) df
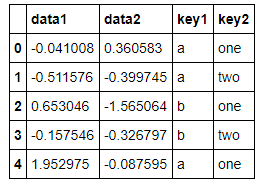
#可以按照key1分组计算data1的平均值 df.loc[:,'data1'].groupby(df.loc[:,'key1']).mean()
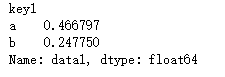
#可以按照key1,key2分组计算data1的平均值 df.loc[:,'data1'].groupby([df.loc[:,'key1'],df.loc[:,'key2']]).mean()
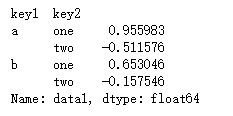
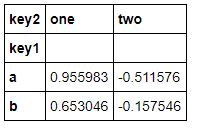
#两个键分组后可以unstack temp = df.loc[:,'data1'].groupby([df.loc[:,'key1'],df.loc[:,'key2']]).mean() temp.unstack()
注意:这里分组忽略null值,另外groupby()括号里可以选择axis = 0 或者1,表示按照航或者列来分组,同时如果df['列名'].groupby()这样就只有这列会group,不然就是全部数据groupby,groupby()里面还可以传入函数比如len
聚合
df.groupby('key1').std() #还有count(),sum(),mean(),median()std,var,min,max,prod,first,last
#可以自定义函数
df.groupby('key1').agg([lambda x : x.max()-x.min(),np.mean,np.std])
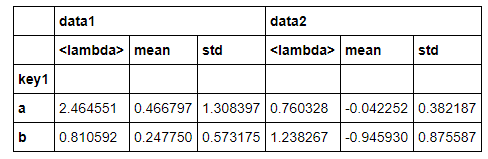
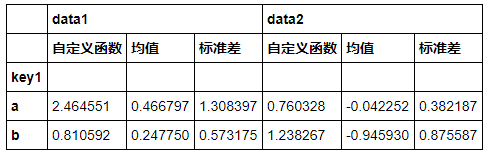
#可以自定义函数 df.groupby('key1').agg([('自定义函数',lambda x : x.max()-x.min()),('均值',np.mean),('标准差',np.std)])
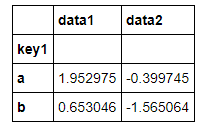
#不同列做不同的动作,一个取最大值,一个取最小值
df.groupby('key1').agg({'data1':np.max,'data2':np.min})
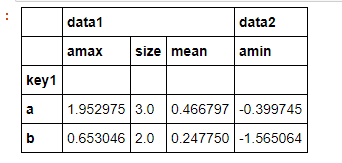
df.groupby('key1').agg({'data1':[np.max,np.size,np.mean],'data2':np.min}) #这个超级吊
透视表和交叉表
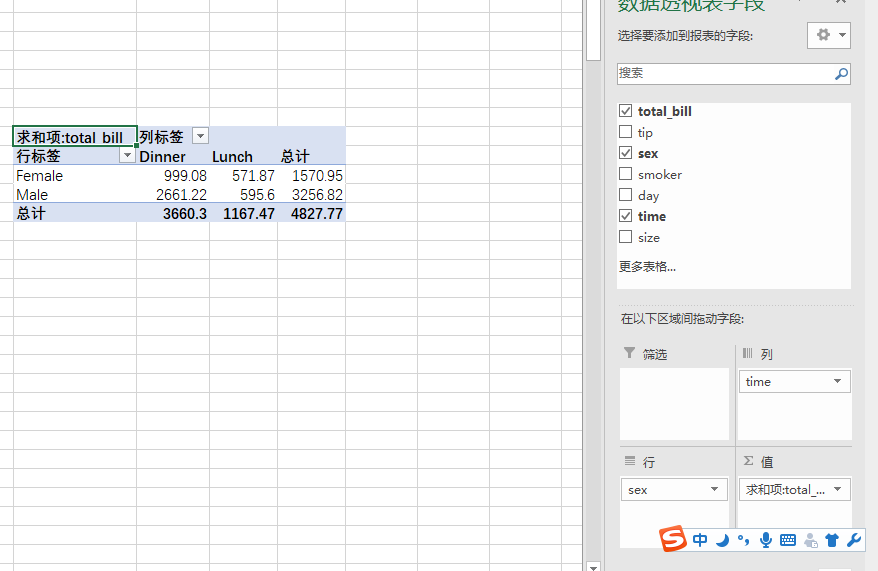
tips.pivot_table(index='sex',columns='time',values='total_bill',aggfunc=np.sum,margins=True,fill_value=0)
对照这个东西看就都懂了,index代表了行,columns代表了列,values代表值,然后aggfunc代表取sum,还是mean,margins代表是否显示汇总,fill_value填充缺失值


 浙公网安备 33010602011771号
浙公网安备 33010602011771号