
学习计划
最近太浮躁了,感觉做事情没有计划性,有点急于求成,因此打算将这个博客作为记录自己的一个学习过程,取名慢慢来会比较快,以下是接下来这段时间的学习计划
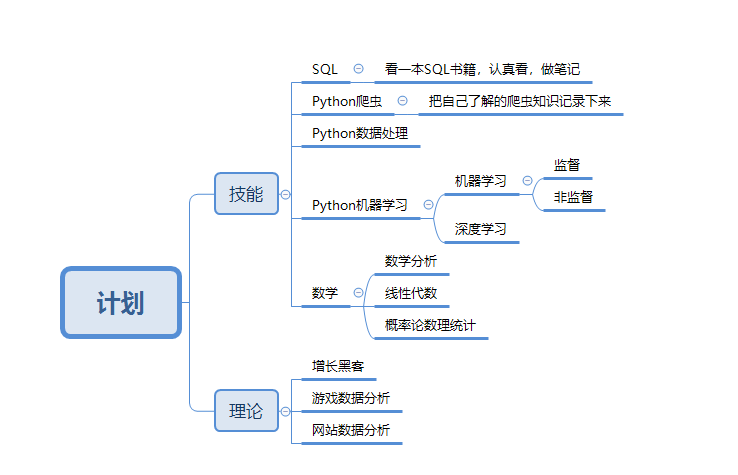
计划主要分成技能+理论两大块,主要以技能为主,包括SQL,Python爬虫、数据处理、机器学习等模块,用博客记录自己每天所学,并反复复习,希望能够得到改善,不求多不求快,但求精!
复习3-23的重点:
1、了解数据库,数据库管理软件,表,列,行,主键(不可重复,不可修改)概念
2、了解select语句用法,了解distinct(不重复的值,多个列要多个列都不重复),limit(限制输出行数),offset(从第几行开始,初始值0),注释的三种用法:-- # /* */
3、排序用法 order by,如果要降序order by desc,对于多个列都要降序可以加逗号,也可以直接是3,1这种数字不过不好用,多个列降序每格列后面都要加order by desc。同时order by都是用在最后面的
4、where的用法包括= != > < isnull isnotnull between
5、整理了线性模型的推导,损失函数生成,推广至广义线性回归,到logistic回归的损失函数,再模型基础上加入了L1 L2正则
心情:
看了一篇大牛写的关于自己学习工作历程,没有对比就没有伤害,同样都是差不多毕业,大学期间自己确实过得浑浑噩噩,不过都说最好的种树时间是十年前,其次是现在。最近自己也确实思考了很多关于自己的工作,生活方面的东西。虽然每天都有在学习一些东西,不过感觉自己很烦躁,心很大,什么都想学,怪自己进步太慢。或许什么都应该一步一步慢慢来吧,希望这个博客自己能够坚持下来,作为记录自己的前进的道路。
引用大牛的一句话:贵有恒,何必三更起五更睡;最无益,只怕一日暴十寒!坚持吧!
复习3.24的重点:
1、where与and or的组合用法,了解and优先级更高,因此有需要多个条件使用时候,最好用()。使用in类似于多个or组合。not跟在条件之前,代表取反,比如not in
2、熟悉like的用法,与%结合代表匹配0次或者无限次,_代表匹配一次。[]在mysql中代表的是正则用法,regexp [] 代表匹配括号中的任意一个
3、计算字段,concat拼接用法,trim rtrim ltrim用法,了解as重命名,明白+-*/用法
4、了解函数的使用,后期重新整理一个完整的函数使用博客
复习3.26的重点:
1、复习函数的用法包括:
数学函数:abs,ceiling,exp,floor,greatest,least,ln,log(x,y),mod(x,y),pi,rand(),round(x,y),sign(),sqrt(),trancate(x,y)
聚合函数:avg,count,min,max,sum,group_concat()
字符串函数:ascii,bit_length,concat,concat_ws(),insert,find_in_set,lcase,lower,ucase,upper,left,right,length,trim,rtrim,ltrim,position,quote,replace,repeat,reverse,strcmp
2、聚集函数:avg函数用法,忽略null,count()忽略null,如果是count(1)这样不会忽略null,max,min,sum,count(distinct col)
3、分组数据:group by的用法,可以选择多个列进行分组。若要在分组完之后过滤使用having,where针对的是列,而having针对的是分组,分组之后再跟order by。排序顺序是,select from where group by having order by
4、使用子查询:与in匹配,where in (接上子查询)
5、爬虫:beautifulsoup(html.text,'lxml')使用lxml解析;soup.find_all('div',class_='')如果要继续往下找,先取出那部分转成str,再转成beautifulsoup格式解析
6、线性回归手工实现:梯度下降法:w -= a*np.dot(x.T,(np.dot(x,w)-y)) 其中a为步长,如果选择太大,会无法收敛,记得在原数据源x中增加一列1
复习3.27的重点
1、连接的用法,inner join ;left join;right join用法
2、了解组合查询,两条select 语句中加入union来拼接,列数要一致才行,这个连接会去重,不去重用union all
3、插入数据:insert into table () values ();更新数据:update table set col = '' where ;删除数据:delete from table where
4、创建表:create table name ( not null ,default 2) 更改表结构:alter table name add col int alter table name drop col 删除表 drop table 重命名 rename table name to new_name
5、日期函数:curdate,curtime,date_add
6、python 处理时间:datetime.now() now.year timedelta.days 字符串日期转化:datetime.strptime(value,'') now.strftime(' ')
复习3.28的重点
1、复习SQL的知识点:
数据库的操作:create database show databases drop database
表的操作:create table table_name ( ...) not null default value primary key() show tables show create table table_name desc table_name alter table table_name add(drop) col
reaname table old_name to new_name drop table table_name truncate table table_name
数据的操作:insert into table_name (col) values() delete from table_name where update table_name set select col from table_name
数据类型:数值型:tinyint smallint int bigint 等 浮点型:float double 字符串:char varchar text 日期时间:time datetime date
select 语句:select from where group by order by limit
视图:create view view_name as select ...
2、复习Python作图:
matplotlib常用设置:fig.set_size_inches() 设置大小 ax.set_xlabel(,fontsize=10) y轴的名称 ax.legend(['','']) 图上的标签 ax.set_xticks(np.arange()) x轴的刻度
然后再使用ax.set_xticklabels(label) 设置每个标签的具体名字 plt.yticks(fontsize = 10) 标签上面的字体大小 plt.title() 标题
多个图画法:设置宽度,然后x选择原来的x+宽度,最后再重新设置x轴 散点图如果要画趋势线用sns.regplot(x = ,y= ,data = )
多个小图画法:fig,ax = plt.subplots() 然后ax[] 来做选择
seaborn的用法:sns.set_context('paper',font_scale = 2,rc = {'lines.linewidth':4}) ptl.figure(figsieze = ()) sns.boxplot sns.violinplot() 箱型图
sns.distplot()直方图 sns.joinplot()两个变量 sns.pairplot()多个变量
复习3.29的重点
1、数据聚合和分组:df[].groupby([可以跟多个列]).mean()或者count() , sum() , median() , std() , var() 等等,也可以是自定义函数agg(lambda:)
agg()这里面如果跟着一个列表,就可以针对多个函数进行,比如[np.mean,np.max,np.min]如果要重命名,用括号加起来[('均值',np.mean),('最小值',np.min),('最大值',np.max)]
如果是要对不同的列做的话:df.groupby().agg({'':,'':}) 里面加字典,分别是列名跟要做的函数
透视表:pd.pivot_table(index,columns,values,aggfunc,margins = True,fill_value = ) 分别于Excel透视表对应一下就能理解
链接:https://www.zhihu.com/question/51039416/answer/263401630
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
1、人工智能基础 — 高等数学必知必会
- 数据分析(就是高数)
- 常数e
- 导数
- 梯度
- Taylor
- gini系数
- 信息熵与组合数
- 梯度下降
- 牛顿法
2.概率论(大一大二学过有木有)
- 微积分与逼近论
- 极限、微分、积分基本概念
- 利用逼近的思想理解微分,利用积分的方式理解概率
- 概率论基础
- 古典模型
- 常见概率分布
- 大数定理和中心极限定理
- 协方差(矩阵)和相关系数
- 最大似然估计和最大后验估计
3.线性代数及矩阵(大一大二学过有木有)
- 线性空间及线性变换
- 矩阵的基本概念
- 状态转移矩阵
- 特征向量
- 矩阵的相关乘法
- 矩阵的QR分解
- 对称矩阵、正交矩阵、正定矩阵
- 矩阵的SVD分解
- 矩阵的求导
- 矩阵映射/投影
4.凸优化(看不懂不要紧,掌握基础即可)
- 凸优化基本概念
- 凸集
- 凸函数
- 凸优化问题标准形式
- 凸优化之Lagerange对偶化
- 凸优化之牛顿法、梯度下降法求解
2、人工智能基础-Python入门及实践课程
- Python快速入门
- 科学计算库Numpy
- 数据分析处理库Pandas
- 可视化库Matplotlib
- 更简单的可视化Seaborn
3、人工智能提升 — Python项目
- Python爬虫项目
4、机器学习基础入门-算法讲解
- 线性回归算法
- 梯度下降原理
- 逻辑回归算法
- 案例实战:Python实现逻辑回归
- 案例实战:对比不同梯度下降策略
- 案例实战:Python分析科比生涯数据
- 案例实战:信用卡欺诈检测
- 决策树构造原理
- 案例实战:决策树构造实例
- 随机森林与集成算法
- 案例实战:泰坦尼克号获救预测
- 贝叶斯算法推导
- 案例实战:新闻分类任务
- Kmeans聚类及其可视化展示
- DBSCAN聚类及其可视化展示
- 案例实战:聚类实践
- 降维算法:线性判别分析
- 案例实战:Python实现线性判别分析
- 降维算法:PCA主成分分析
- 案例实战:Python实现PCA算法
5、机器学习进阶提升-项目演练
- EM算法原理推导
- GMM聚类实践
- 推荐系统
- 案例实战:Python实战推荐系统
- 支持向量机原理推导
- 案例实战:SVM实例
- 时间序列ARIMA模型
- 案例实战:时间序列预测任务
- Xgbooost提升算法
- 案例实战:Xgboost调参实战
- 计算机视觉挑战
- 神经网络必备基础
- 神经网络整体架构
- 案例实战:CIFAR图像分类任务
- 语言模型
- 自然语言处理-word2vec
- 案例实战:Gensim词向量模型
- 案例实战:word2vec分类任务
- 探索性数据分析:赛事数据集
- 探索性数据分析:农粮组织数据集
6、深度学习基础
- 计算机视觉-卷积神经网络
- 三代物体检测框架
- 卷积神经网络基本原理
- 卷积参数详解
- 案例实战CNN网络
- 网络模型训练技巧
- 经典网络架构与物体检测任务
- 深度学习框架Tensorflow基本操作
- Tensorflow框架构造回归模型
- Tensorflow神经网络模型
- Tensorflow构建CNN网络
- Tensorflow构建RNN网络
- Tensorflow加载训练好的模型
- 深度学习项目实战-验证码识别
- 深度学习框架Caffe网络配置
- Caffe制作数据源
- Caffe框架小技巧
- Caffe框架常用工具
7、深度学习项目演练
- 项目演练:人脸检测数据源制作与网络训练(基于Caffe)
- 项目演练:实现人脸检测(基于Caffe)
- 项目演练:关键点检测第一阶段网络训练(基于Caffe)
- 项目演练:关键点检测第二阶段模型实现(基于Caffe)
- 项目演练:对抗生成网络(基于Tensorflow)
- 项目演练:LSTM情感分析(基于Tensorflow)
- 项目演练:机器人写唐诗(基于Tensorflow)
- 项目演练:文本分类任务解读与环境配置
- 项目演练:文本分类实战(基于Tensorflow)
- 项目演练:强化学习基础(基于Tensorflow)
- 项目演练:DQN让AI自己玩游戏(基于Tensorflow)
8、人工智能综合项目实战
- 语音识别、人脸识别、
- 电商网站数据挖掘及推荐算法
- 金融P2P平台的智能投资顾问
- 自动驾驶技术
- 医疗行业疾病诊断监测
- 教育行业智能学习系统

 浙公网安备 33010602011771号
浙公网安备 33010602011771号