GO语言学习笔记-数据篇 Study for Go ! Chapter four - Data
- GO语言学习笔记-函数篇 Study for Go ! Chapter three - Function
- GO语言学习笔记-数据篇 Study for Go ! Chapter four - Data
- GO语言学习笔记-方法篇 Study for Go ! Chapter five - Method
- GO语言学习笔记-接口篇 Study for Go ! Chapter six - Interface
- GO语言学习笔记-并发篇 Study for Go ! Chapter seven - Concurrency
- GO语言学习笔记-包结构篇 Study for Go ! Chapter eight - Package Structure
- GO语言学习笔记-反射篇 Study for Go ! Chapter nine - Reflect
- GO语言学习笔记-测试篇 Study for Go ! Chapter ten- Test
- GO语言学习笔记-工具链篇 Study for Go ! Chapter eleven - Tool Chain
-
字符串是不可变字节 (byte)序列,其本身是一个复合结构
-
头部指针指向字节数组,但没有 NULL 结尾,默认以 UTF-8 编码 存储 Unicode 字符, 字面量里允许使用十六进制、八进制和 UTF 编码格式
-
字符串默认值不是 nil, 而是 “”
-
使用 “ ` ” 定义不做转义处理的原始字符串 ( raw string ),支持跨行
-
编译器不会解析原始字符串内的注释语句,且前置缩进空格也属于字符串内容
-
支持 “ != 、==、<、>、+、+=”操作符
-
允许以索引号访问字节数组 (非字符),但不能获取元素地址
-
以切片语法 (起始和结束索引号)返回字串时,其内部依旧指向原字节数组
-
使用 for 遍历字符串时,分 byte 和 rune 两种方式
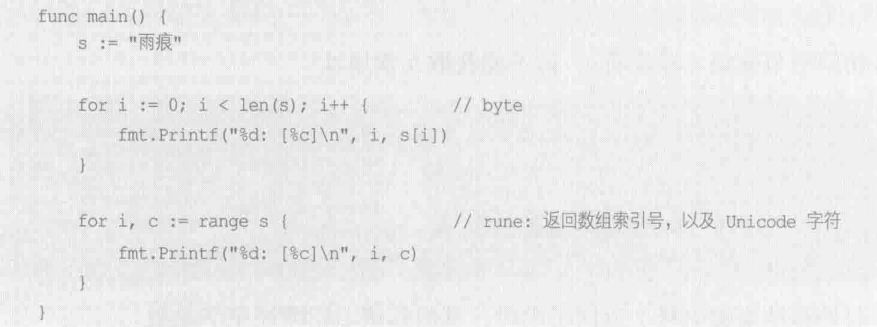
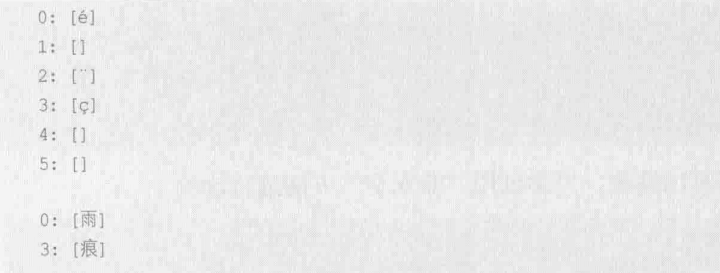
转换
-
要修改字符串,需要将其转化为可变类型 ([ ]rune 或 [ ]byte),待完成后再转换回来,但不管如何转换都需要重新分配内存,并复制数据
-
某些时候,转换操作会拖累算法性能,可尝试用“ 非安全 ” 方法进行改善


-
用 append 函数, 可将 string 直接追加到 [ ]byte 内
-
考虑到字符串只读特征,转换时复制数据到新分配内存是可以理解的。当然,性能同样重要,编译器会为某些场合进行专门优化,避免格外分配和复制操作
性能
-
除了类型转换外,动态构建字符串也容易造成性能问题
-
用加法操作符拼接字符串时,每次都需重新分配内存。如此,构建 “ 超大 ” 字符串时,性能就显得很差
-
改进思路是预分配足够的内存空间。常用的方法是用 “ string. Join ”, 它会统计所有参数的长度,并一次性完成内存分配操作
-
bytes. Buffer 也能完成类似操作,且性能相当
-
对于数量较小的字符串格式化拼接,可用 fmt. Sprintf、text/template 等方法
-
字符串操作通常在对上分配内存,这回对 Web 等高并发应用会造成较大影响,会由大量字符串对象要做垃圾回收。建议使用 [ ]byte 缓存池,或在栈上自行拼装等方式来实现zero-garbage
Unicode
-
类型 rune 专门用来存储 Unicode 码点 ( code point ),他是 int32 的别名, 相当于 UCS-4/UTF-32 编码格式。使用单引号的字面量,其默认类型就是 rune
-
除 [ ]rune 外, 还可直接在 rune、byte、string 间进行转换
-
字符串存储的字节数组,不一定就是合法的 UTF-8 文本
-
标准库 Unicode 里提供了丰富的操作函数。除了验证函数以外,还可以用 RuneCountInString 代替 len 返回准确的 Unicode 字符数量
2. Array
-
定义数组类型时,数组长度必须是非负整数常量表达式,长度是类型组成部分。也就是说,元素类型相同,但长度不同的数组不属于同一类型
-
对于结构等复合类型,可省略元素初始化类型标签
-
在定义多维数组时,仅第一维度允许使用 “ ... ”
-
内置函数 len 和 cap 都返回第一维度长度
-
如果元素类型支持 “ ==、!= ” 操作符,那么数组也支持此操作
指针
-
要分清指针数组和数组指针的区别,指针数组是指元素为指针类型的数组,数组指针是获取数组变量的地址
复制
-
与C数组变量隐式作为指针使用不同,golang 数组是值类型,赋值和传参操作都会赋值整个数组数据
-
如果需要可以改用 指针或者 切片,以此避免数据赋值
3. Slice
-
切片本身并非动态数组或数组指针,它内部通过指针引用底层数组,设定相关属性将数据读写操作限定在指定区域内
-
切片本身是个只读对象,其工作机制类似于数组指针的一种包装
-
可基于数组或者数组指针创建切片,以开始和结束索引位置确定所引用的数组片段。不支持反向索引,实际范围是一个右半开区间
-
属性 cap 表示切片所引用数组片段的真实长度,len 用于限定可读的写元素数量。另外,数组必须addressable ,否则会引发错误。
-
和数组一样,切片同样使用索引号访问元素内容。起始索引为0,而非对应的底层数组真实索引位置
-
可以直接创建切片对象,不需要预先准备数组,因为是引用类型,需要使用 make 函数或显式初始化语句,它会自动完成底层数组内存分配
Attention:
注意下面两种定义方式的区别,前者仅定义了一个[ ]int类型变量,并未执行初始化操作,而后者则用初始化表达式完成了全部创建过程。



-
切片不支持比较操作,计算元素类型支持也不行,仅能判断是否为 nil
-
切片可获取元素地址,但不能像数组那样直接用指针访问内容

-
入宫元素类型也是切片,那么就可以实现类似交错数组 ( jagged array )功能

-
显然,切片是很小的结构体对象,用来代替数组传参可避免复制开销,还有,make函数允许在运行期动态指定数组长度,绕开了数组类型必须使用编译期常量的限制
-
但是,并非所有时候都适合用切片代替数组,以为切片底层数组可能会在堆上分配内存,而且小数组在栈上拷贝的消耗也未必就比 make 代价大
reslice
-
将切片视作 [ cap ]slice 数据源,据此创建新的切片对象,不能超出 cap ,但不受 len 限制
-
新建切片对象依旧指向原底层数组,也就是说修改对所有关联切片可见
-
利用 reslice 操作很容易实现一个栈式数据结构
append
-
向切片尾部 ( slice[ len ] )添加数据,返回新的切片对象
-
数据被追加到原底层数组。如果超出 cap 限制,则为新切片对象重新分配数组
Attention:
-
是超出切片 cap 限制,而非底层数组长度限制,因为 cap 可小于数组长度
-
新分配数组长度是原 cap 的 2 倍,而非原数组的 2 倍 ( 也并非总是 2 倍,对于较大的切片,会尝试扩容 1/4,以节约内存 )
-
向 nil 切片追加数据时,会为其分配底层数组内存
-
正因为存在重新分配底层数组的缘故,在某些场合建议预留足够多的空间,避免中途内存分配和数据复制开销
copy
-
在两个切片对象间复制数据,允许指向同一底层数组,允许目标区间重叠,最终所复制长度以较短的切片长度 ( len )为准
-
还可直接从字符串中复制数据到 [ ]byte
-
如果切片长时间引用大数组中很小的片段,那么建议新建独立切片,复制出所需数据,以便原数组内存可被及时回收。
4. Map
-
字典 (哈希表)是一种使用频率极高的数据结构,将其作为语言内置类型,从运行时层面进行优化,可获得更高校的性能
-
作为无序键值对集合、字典要求 key 必须是支持相等运算符 (==、!=)的数据类型,比如,数字、字符串、指针、数组、结构体,以及对应接口类型
-
字典是引用类型,使用 make 函数或初始化表达语句来创建
-
访问不存在的键值,会默认返回零值,不会引发错误。但推荐使用 ok-idiom 模式,毕竟通过零值无法判断键值是否存在,或许存储的 value 本就是零
-
对字典进行迭代,每次返回的键值次序都不相同
-
函数 len 返回当前键值对数量,cap 不接受字典类型。另外因内存访问安全和哈希算法等问题,字典被设计成 “ not addressable ”,所以不能直接修改 value 成员 (结构或函数)
-
正确的做法是返回整个 value,待修改后再设置字典键值,或直接用指针类型
-
不能对 nil 字典进行写操作,但却能读
-
内容为空的字典 ≠ nil
安全
-
在迭代期间删除或新增键值是安全的
-
运行时会对字典并发操作做出检测,如果某个任务正在对字典进行写操作,那么其他任务就不能对该字典执行并发操作 (读、写、删除),否则会导致进程崩溃
-
上述问题可用 数据竞争 ( data race )检查,它会输出详细检测信息
性能
-
字典对象本身是指针包装,传参时无需再次取地址
-
在创建时预先准备足够的空间有助于提升性能,减少扩张时的内存分配和重新哈希操作
-
对于海量小对象,应直接用字典存储键值数据拷贝,而非指针,这有助于减少需要扫描的对象数量,大幅缩短垃圾回收时间。另外,字典不会收缩内存,所以适当替换成新对象时必要的
5. Struct
-
结构体将多个不同类型命名字段(field)序列打包成一个符合类型
-
字段名必须唯一,可以用 “ _ ” 补位,支持使用自身指针类型成员。字段名,排列顺序属于类型组成成分。除对齐处理外,编译器不会优化,调整内存布局
-
可以按照顺序初始化全部字段,或使用命名方式初始化指定字段
-
可以直接定义匿名结构类型变量,或用作字段类型,但因其缺少类型标识,在作为字段类型时无法直接初始化,稍显麻烦
-
只有在所有字段类型全部支持时,才可做相等操作
-
可使用指针直接操作结构字段,但不能是多级指针
空结构(struct{ })
-
空结构是指没有字段的结构类型,它比较特殊,因为无论是其自身还是作为数组元素类型,其长度都为0
-
尽管没有分配数组内存,但依然可以操作元素,对应切片 len、cap 属性也正常
-
实际上,这类”长度“为 0 的对象通常都指向 runtime.zerobase 变量
-
空结构可作为通道元素类型,用于事件通知
匿名字段( anonymous field )
-
匿名字段是指没有名字、仅有类型的字段,也被称作嵌入字段或者嵌入类型
-
从编译器角度看,这只是隐式地以类型名作为字段名字,可直接引用匿名字段的成员,但初始化时须当作独立字段
-
如嵌入其他包中的类型,则隐式字段名字不包括包名
-
不仅仅时结构体,除接口指针和多级指针以外的任何命名类型都可作为匿名字段
-
不能将基础类型和其指针类型同时嵌入,因为两者隐式名字相同
-
虽然可以像普通字段那样访问匿名字段成员,但会存在重名问题,默认情况下,编译器从当前显式命名字段开始,逐步向内查找匿名字段成员,如果匿名字段成员被外层同名字段遮蔽,那么必须使用显式字段名
-
如果多个相同层级的匿名字段成员重名,就只能使用显式字段名访问,因为编译器无法确定目标
-
严格来说,golang 并不是传统意义上的面向对象编程语言,或者说仅实现了最小面向对象机制,匿名嵌入不是继承,无法实现多态处理。虽然配合方法集,可用接口来实现一些类似的操作,但是其本质是完全不同的
字段标签 ( tag )
-
字段标签并不是注释,而是用来对字段进行描述的元数据,尽管它不属于数据成员,但是确实类型的组成成分
-
在运行期,可用反射获取标签信息,它常被用做格式校验,数据库关系映射等
内存布局
-
不管结构体中包含多少字段,其内存总是一次性分配的,各字段在相邻的地址空间按定义顺序排列。
-
对于引用类型、字符串和指针,结构内存中只包含其基本(头部)数据
-
包含匿名字段成员
-
借助 unsafe 包中的相关函数,可输出所有字段的偏移量和长度
-
分配内存时,字段必须做对齐处理,通常以所有字段中最长的基础类型宽度为标准
-
比较特殊的时空结构类型字段,如果它是最后一个字段,那么编译器将其作为长度为 1 的类型做类型处理,以便地址不会越界,避免引发垃圾回收错误
-
如果仅有一个空结构字段,那么同样按 1 对齐,只不过长度为 0 ,且指向 runtime.zerobase 变量
-
对齐的原因于硬件平台,以及访问效率有关,某些平台只能访问特定地址,比如只能是偶数地址。而另一方面,CPU 访问自然对齐的数据所需的读周期最少,还可以避免拼接数据
本文来自博客园,作者:slowlydance2me,转载请注明原文链接:https://www.cnblogs.com/slowlydance2me/p/17190882.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号