792. 匹配子序列的单词数 ----- find()暴力、队列分桶查询、二分法哈希 upper_bound()、闭包匿名函数
给定字符串 s 和字符串数组 words, 返回 words[i] 中是s的子序列的单词个数 。
字符串的 子序列 是从原始字符串中生成的新字符串,可以从中删去一些字符(可以是none),而不改变其余字符的相对顺序。
例如, “ace” 是 “abcde” 的子序列。
示例 1:
输入: s = "abcde", words = ["a","bb","acd","ace"]
输出: 3
解释: 有三个是 s 的子序列的单词: "a", "acd", "ace"。
Example 2:
输入: s = "dsahjpjauf", words = ["ahjpjau","ja","ahbwzgqnuk","tnmlanowax"]
输出: 2
提示:
1 <= s.length <= 5 * 104
1 <= words.length <= 5000
1 <= words[i].length <= 50
words[i]和 s 都只由小写字母组成。
来源:力扣(LeetCode)
链接:https://leetcode.cn/problems/number-of-matching-subsequences
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
find暴力:

class Solution { public: int numMatchingSubseq(string s, vector<string>& words) { int cnt = 0; for (string &word : words) { int cur = -1; bool ok = true; for (char &c : word) { // 查找 cur 之后是否出现了 c cur = s.find(c, cur + 1); if (cur == string::npos) { ok = false; break; } } if (ok) cnt++; } return cnt; } };
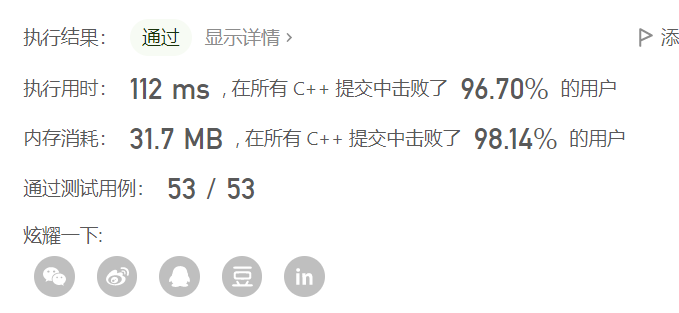
队列分桶:
优化前:
class Solution { public: int numMatchingSubseq(string s, vector<string>& words) { vector<queue<string>> d(26); // 将26个字母分成26个桶 for (auto& w : words) d[w[0] - 'a'].emplace(w);// 对字符串数组中的每一个字符串根据首字母进行装桶。 int ans = 0; // 设置s的子序列个数 for (char& c : s) { // 对s进行每个字母遍历 auto& q = d[c - 'a']; // 将该字母的桶设置为队列q0 for (int k = q.size(); k; --k) { //遍历桶 auto t = q.front(); // 队首 q.pop(); // 出队 if (t.size() == 1) ++ans; // 如果队首只有一个字母(该字母就是分桶首字母)ans++ else d[t[1] - 'a'].emplace(t.substr(1)); // 其他情况,将队首字符串的首字母去掉,以新的首字母放进新的桶里。 } } return ans; } };
优化后:
class Solution { public: int numMatchingSubseq(string s, vector<string>& words) { vector<queue<pair<int, int>>> d(26); for (int i = 0; i < words.size(); ++i) d[words[i][0] - 'a'].emplace(i, 0); // 根据首字母装桶 int ans = 0; for (char& c : s) { auto& q = d[c - 'a']; // 每个桶 为一个队列 for (int t = q.size(); t; --t) { //遍历桶 auto [i, j] = q.front(); //队首 j = 0 i 为第几个字符串 q.pop(); // 出队 if (++j == words[i].size()) ++ans; // 队首为单字符 ans++ else d[words[i][j] - 'a'].emplace(i, j); // 其他情况,j = 1,去掉首字母,以第二个字母装桶。 } } return ans; } };
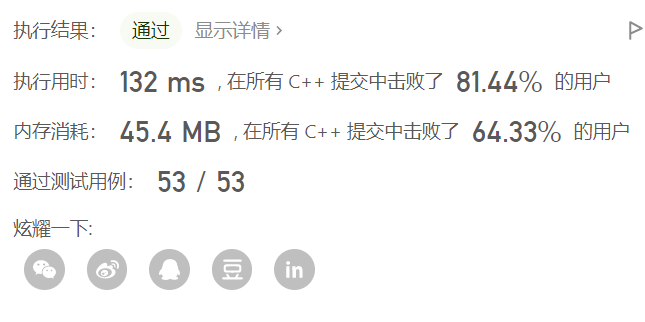
二分哈希:
class Solution { public: int numMatchingSubseq(string s, vector<string>& words) { vector<vector<int>> d(26); // 二维数组哈希表 for (int i = 0; i < s.size(); ++i) d[s[i] - 'a'].emplace_back(i); // 对s的每个字母入表。 int ans = 0; // 计数器 auto check = [&](string& w) { // 闭包取 w int i = -1; for (char& c : w) { // 对每个字母检查 auto& t = d[c - 'a']; // t 是哈希表中该字母的值 int j = upper_bound(t.begin(), t.end(), i) - t.begin(); if (j == t.size()) return false; i = t[j]; } return true; }; for (auto& w : words) ans += check(w); // true则+1 return ans; } };


hello my world
本文来自博客园,作者:slowlydance2me,转载请注明原文链接:https://www.cnblogs.com/slowlydance2me/p/16898886.html


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 使用C#创建一个MCP客户端
· 分享一个免费、快速、无限量使用的满血 DeepSeek R1 模型,支持深度思考和联网搜索!
· ollama系列1:轻松3步本地部署deepseek,普通电脑可用
· 基于 Docker 搭建 FRP 内网穿透开源项目(很简单哒)
· 按钮权限的设计及实现