推荐系统算法 :基于内容CB(用户反馈检测UGC ++ 高频权重增加但热门权重减少TF-IDF)----- 机器学习





TF-IDF词频-逆文档频率算法 python代码实现:
0.引入依赖
import numpy as np import pandas as pd
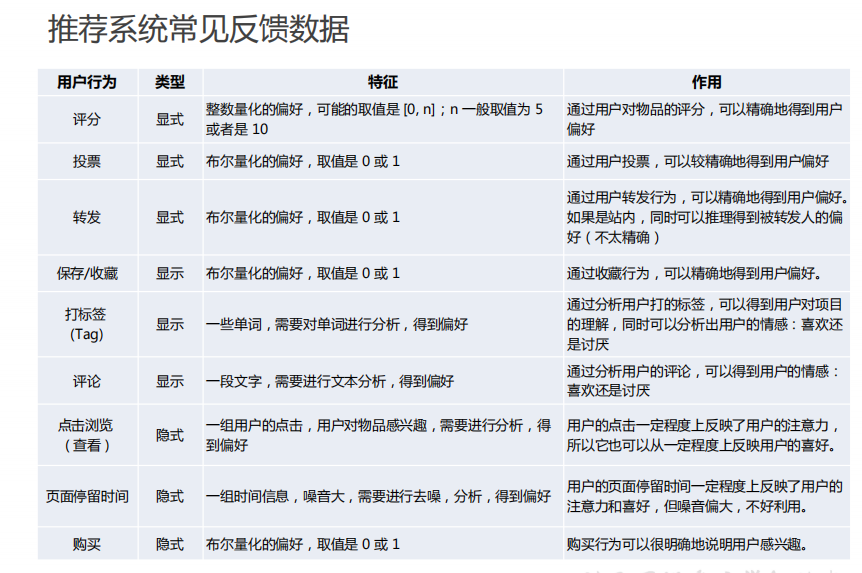
docA = "The cat sat on my bed" docB = "The dog sat on my knees" # 构建词袋 bowA = docA.split(" ") bowB = docB.split(" ") bowA # 构造词库 wordSet = set(bowA).union(set(bowB)) wordSet
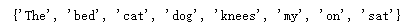
2.进行次数统计
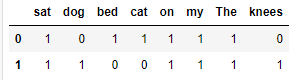
# 用一个统计字典 保存词出现次数 wordDictA = dict.fromkeys( wordSet, 0 ) wordDictB = dict.fromkeys( wordSet, 0 ) # 遍历文档统计词数 for word in bowA: wordDictA[word] += 1 for word in bowB: wordDictB[word] += 1 pd.DataFrame([wordDictA, wordDictB])
3.计算词频TF
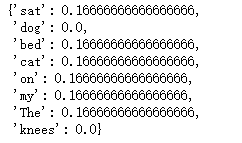
def computeTF( wordDict, bow ): #用一个字典对象记录tf, 把所有的词对应在bow文档里的TF都算出来 tfDict = {} nbowCount = len(bow) for word, count in wordDict.items(): tfDict[word] = count / nbowCount return tfDict tfA = computeTF(wordDictA, bowA) tfB = computeTF(wordDictB, bowB) tfA
4.计算逆文档频率IDF
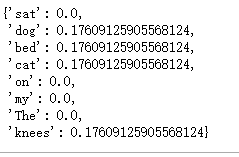
def computeIDF( wordDictList ): # 用一个字典对象保存IDF结果。每个词作为key, 初始值为0 idfDict = dict.fromkeys(wordDictList[0], 0) N = len(wordDictList) import math for wordDict in wordDictList: # 遍历字典中的每一个词汇 for word, count in wordDict.items(): if count > 0: # 先把NI增加1, 存入到idfDict idfDict[word] += 1 # 已经得到所有词汇i对应的Ni,现在根据公式把它替换成idf值 for word, ni in idfDict.items(): idfDict[word] = math.log10 ( (N+1)/(ni+1) ) return idfDict idfs = computeIDF([wordDictA, wordDictB]) idfs
5. 计算TF-IDF
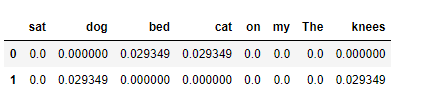
def computeTFIDF( tf, idfs ): tfidf = {} for word, tfval in tf.items(): tfidf[word] = tfval * idfs[word] return tfidf tfidfA = computeTFIDF( tfA, idfs ) tfidfB = computeTFIDF( tfB, idfs ) pd.DataFrame( [tfidfA, tfidfB] )
hello my world
本文来自博客园,作者:slowlydance2me,转载请注明原文链接:https://www.cnblogs.com/slowlydance2me/p/16872816.html
