Kmeans_K均值算法-----机器学习(非监督学习)
K means教程
0.引入依赖
import numpy as np import matplotlib.pyplot as plt # 引入数据 from sklearn.datasets import make_blobs
1.数据加载
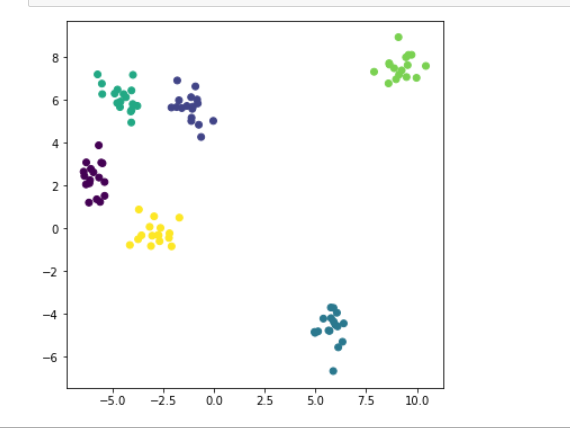
x, y = make_blobs( n_samples = 100, centers = 6, random_state=1234, cluster_std=0.6) plt.figure(figsize=(6,6)) #定义画布大小 plt.scatter(x[:,0], x[:,1], c=y) plt.show()
2.算法实现

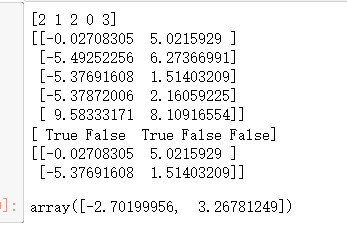
# 距离函数,默认计算欧式距离 from scipy.spatial.distance import cdist class K_Means(object): # 初始化, 参数 n_clusters(K)、迭代次数:max_iter、初始质心:centroids def __init__(self, n_clusters=6, max_iter=300, centroids=[]): self.n_clusters = n_clusters self.max_iter = max_iter self.centroids = np.array( centroids, dtype=np.float ) #训练模型方法,k_means聚类过程,传入原始数据 def fit(self, data): #加入没有指定初始质心,就随机选取data中的点作为初始质心 if (self.centroids.shape == (0,) ): # 从data中随机生成0到data行数的6个整数,作为索引值 self.centroids = data[ np.random.randint( 0, data.shape[0], slef.n_clusters ) ,: ] # 开始迭代 for i in range(self.max_iter): # 1. 计算距离矩阵, 得到一个100*6的矩阵 distances = cdist(data, self.centroids) # 2. 对距离按由远到近排序,选取最近的质心点的类别(下标),作为当前点的分类 c_ind = np.argmin( distances, axis=1 ) # 3. 对每一类数据进行均值计算,更新质心点坐标 for i in range(self.n_clusters): # 排除掉没有在c_ind里的类别 if i in c_ind: # 选出所有类别是i的点,取data里面坐标的均值,更新第i个质心 self.centroids[i] = np.mean( data[c_ind==i], axis=0 ) # 实现预测方法 def predict(self, samples): # 跟上面一样,先计算距离矩阵,然后选取距离最近的那个质心的类别 distances = cdist(samples, self.centroids) c_ind = np.argmin( distances, axis=1 ) return c_ind dist = np.array([[121,221,32,43], [121,1,12,23], [65,21,2,43], [1,221,32,43], [21,11,22,3],]) c_ind = np.argmin( dist, axis=1 ) print(c_ind) x_new = x[0:5] print(x_new) print(c_ind==2) print(x_new[c_ind == 2]) np.mean(x_new[c_ind==2], axis=0)
3.测试
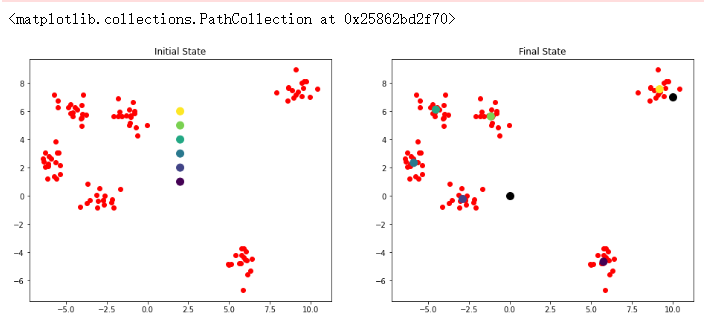
def plotKMeans(x, y, centroids, subplot, title): # 分配子图 plt.subplot(subplot) plt.scatter(x[:,0],x[:,1],c='r') # 画出质心点 plt.scatter(centroids[:,0], centroids[:,1], c=np.array(range(6)), s=100) plt.title(title) kmeans = K_Means(max_iter = 300, centroids=np.array([[2,1],[2,2],[2,3],[2,4],[2,5],[2,6]])) plt.figure(figsize=(16, 6)) plotKMeans( x, y, kmeans.centroids, 121, 'Initial State') # 开始聚类 kmeans.fit(x) plotKMeans( x, y, kmeans.centroids, 122, 'Final State') # 预测新数据点的类别 x_new = np.array([[0,0],[10,7]]) y_pred = kmeans.predict(x_new) print(y_pred) plt.scatter(x_new[:,0], x_new[:,1], s=100, c='black')
hello my world
本文来自博客园,作者:slowlydance2me,转载请注明原文链接:https://www.cnblogs.com/slowlydance2me/p/16870515.html


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本
· C#/.NET/.NET Core优秀项目和框架2025年2月简报
· Manus爆火,是硬核还是营销?
· 终于写完轮子一部分:tcp代理 了,记录一下
· 【杭电多校比赛记录】2025“钉耙编程”中国大学生算法设计春季联赛(1)