KNN _ K近邻算法 的实现 ----- 机器学习
导入相关包
import numpy as np import pandas as pd # 引入 sklearn 里的数据集,iris(鸢尾花) from sklearn.datasets import load_iris from sklearn.model_selection import train_test_split # 切分为训练集和测试集 from sklearn.metrics import accuracy_score # 计算分类预测的准确率
1.数据加载预处理

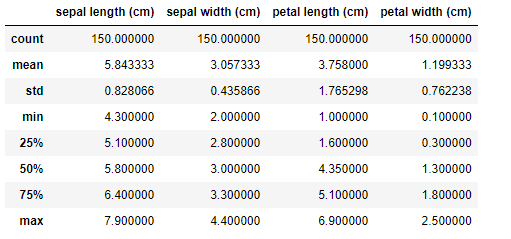
iris = load_iris() df = pd.DataFrame(data = iris.data, columns = iris.feature_names) df['class'] = iris.target df['class'] = df['class'].map({0:iris.target_names[0], 1:iris.target_names[1], 2:iris.target_names[2]}) df.describe() # 描述
x = iris.data y = iris.target.reshape(-1,1) print(x.shape, y.shape)

# 划分训练集和测试集 x_train, x_test, y_train, y_test = train_test_split(x, y, test_size = 0.3, random_state=35, stratify=y) print(x_train.shape, y_train.shape) print(x_test.shape, y_test.shape)
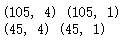
2. 核心算法实现
# 距离函数定义 def l1_distance(a, b): return np.sum(np.abs(a-b), axis=1 ) def l2_distance(a, b): return np.sqrt(np.sum((a-b) ** 2, axis=1) ) # 分类器实现 class kNN(object): # 定义一个初始化方法:__init__是类的构造方法 def __init__(self, n_neighbors = 1, dist_func = l1_distance): self.n_neighbors = n_neighbors self.dist_func = dist_func # 调整模型方法 def fit(self, x, y): self.x_train = x self.y_train = y # 模型预测方法 def predict(self, x): # 初始化预测分类数组 y_pred = np.zeros((x.shape[0], 1), dtype = self.y_train.dtype) # 遍历输入X的数据点 (每一个测试点的下标序号i和数据) for i, x_test in enumerate(x): # 测试数据x_test和训练数据计算距离 distances = self.dist_func(self.x_train,x_test) # 由近到远排序,取得索引值 nn_index = np.argsort(distances) # 输出索引值 # 选取最近的K个点, 保存它们对应的分类类别 nn_y = self.y_train[nn_index[:self.n_neighbors] ].ravel() # 变成一维数组 #统计类别中出现频率最高的那个, 赋给y_pred[i] y_pred[i] = np.argmax(np.bincount(nn_y))# binnary count 统计每个值出现的次数 输出成数组 return y_pred
3. 测试
# 定义实例 knn = kNN(n_neighbors = 3) # 训练模型 knn.fit(x_train, y_train) # 传入测试数据, 做预测 y_pred = knn.predict(x_test) # 求出预测准确率 accuracy = accuracy_score(y_test, y_pred) print("预测准确率:",accuracy)
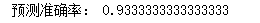
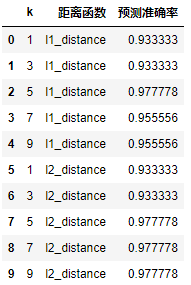
# 定义实例 knn = kNN() # 训练模型 knn.fit(x_train, y_train) # list保存结果 result_list = [] # 针对不同的参数选取,做预测 for p in [1, 2]: knn.dist_func = l1_distance if p == 1 else l2_distance # 考虑不同的K取值. 步长为2 ,避免二元分类 偶数打平 for k in range(1, 10, 2): knn.n_neighbors = k # 传入测试数据, 做预测 y_pred = knn.predict(x_test) # 求出预测准确率 accuracy = accuracy_score(y_test, y_pred) result_list.append([k, 'l1_distance' if p == 1 else 'l2_distance', accuracy]) df= pd.DataFrame(result_list, columns=['k', '距离函数', '预测准确率']) df
hello my world
本文来自博客园,作者:slowlydance2me,转载请注明原文链接:https://www.cnblogs.com/slowlydance2me/p/16857906.html


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本
· Manus爆火,是硬核还是营销?
· 终于写完轮子一部分:tcp代理 了,记录一下
· 别再用vector<bool>了!Google高级工程师:这可能是STL最大的设计失误
· 单元测试从入门到精通