python 爬虫 -----爬取猪八戒网
1.使用元素定位:找到一个模块的分区,复制它完整的Xpath
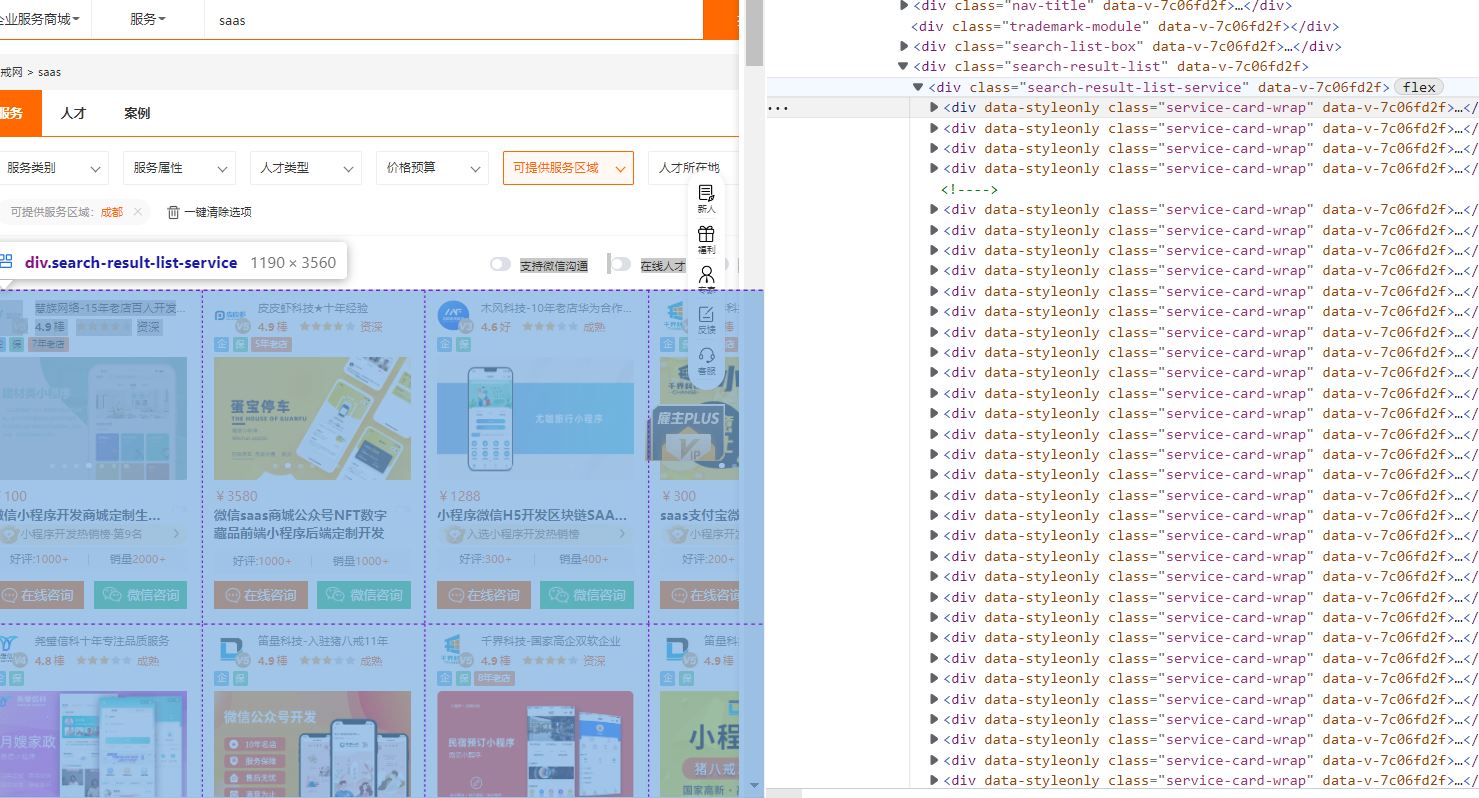
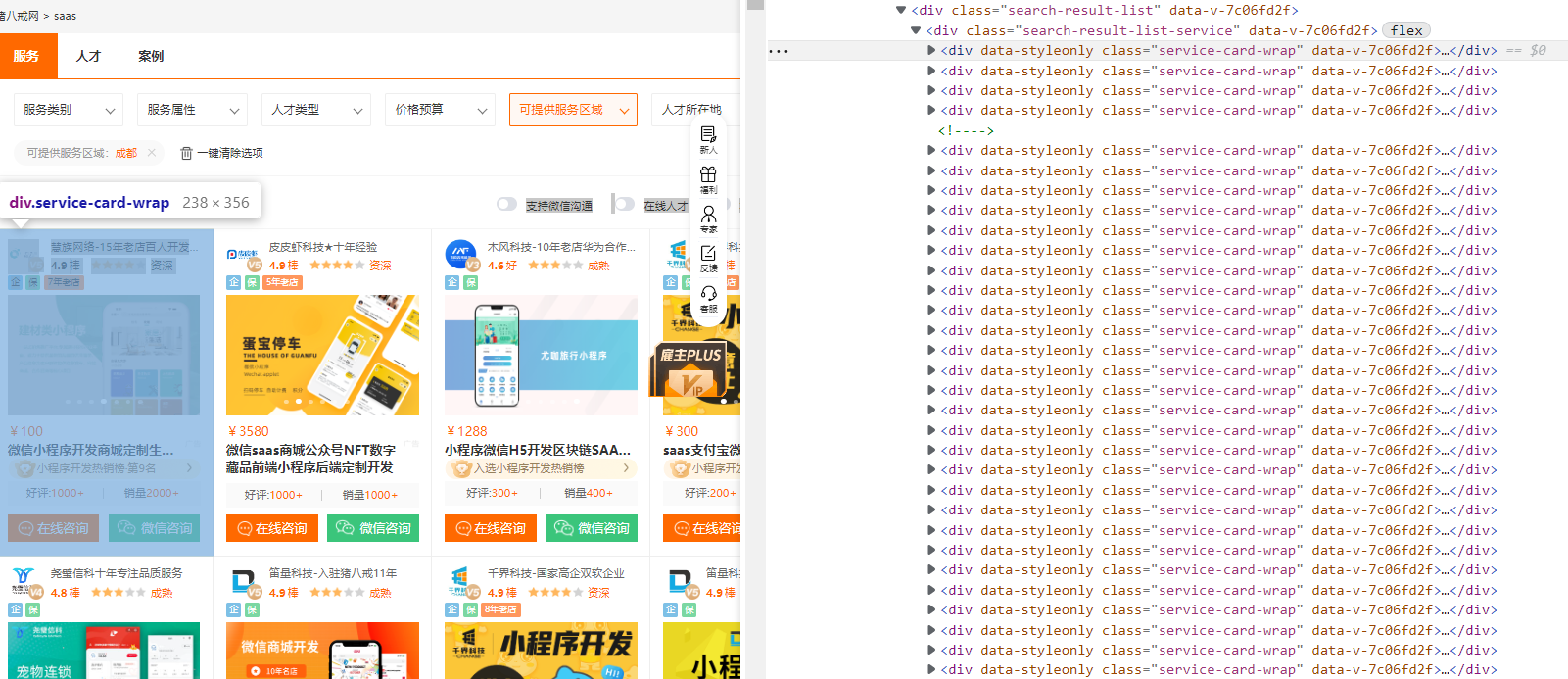
2. 修饰并利用循环得出每一个模块
import requests from lxml import etree # 获取源码 url = "https://chengdu.zbj.com/search/service/?kw=saas" resp = requests.get(url) # print(resp.text) html = etree.HTML(resp.text) divs = html.xpath("/html/body/div[2]/div/div/div[3]/div/div[3]/div[4]/div[1]/div[1]") for div in divs: #循环 每一个模块
3.依次使用xpath爬取想得到的数据存放到列表
import requests from lxml import etree # 获取源码 url = "https://chengdu.zbj.com/search/service/?kw=saas" dic = { "User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/106.0.0.0 Safari/537.36 Edg/106.0.1370.52" } resp = requests.get(url, headers=dic) # print(resp.text) # 解析 html = etree.HTML(resp.text) divs = html.xpath('//*[@id="__layout"]/div/div[3]/div/div[3]/div[4]/div[1]/div') # print(divs) for div in divs: # 循环 每一个模块 ./div/div[3]/div[1]/span price = div.xpath("./div/div[3]/div[1]/span[1]/text()")[0].strip("¥") # 从列表取出,并且过滤¥ company_name = div.xpath("./div/a/div[2]/div[1]/div/text()")[0] title= "saas".join(div.xpath("./div/div[3]/a/text()"))
# 使用"saas".join()拼接title
print(price) print(company_name) print(title) resp.close()
4.运行结果
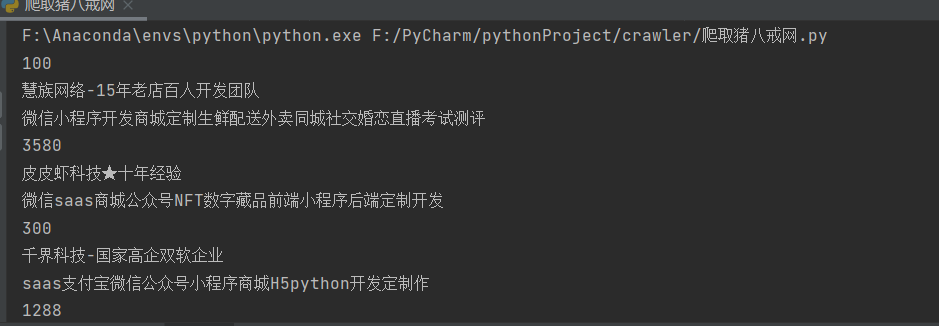
hello my world
本文来自博客园,作者:slowlydance2me,转载请注明原文链接:https://www.cnblogs.com/slowlydance2me/p/16837428.html

