python 爬虫 ----- xpath
- xpath 是在XML文档中搜索内容的一门语言
- html是xml的一个子集
xml代码示例
""" <book> <id>1</id> <name>野花遍地香</name> <price>1.23</price> <author> <nick>周大枪</nick> <nick>周芷若</nick> </author> </book> """
#安装lxml
完整代码
from lxml import etree xml = """ <book> <id>1</id> <name>野花遍地香</name> <price>1.23</price> <author> <nick>周大枪</nick> <nick>周芷若</nick> <div> <nick>大</nick> <nick>周</nick> </div> </author> </book> """ tree = etree.XML(xml) # result = tree.xpath("/book/name/text()") # 表示层级关系,第一个/是根节点 # text()表示拿文本 # result = tree.xpath("/book/author//nick/text()") # //表示所有 拿出所有的后代 result = tree.xpath("/book/author/*/nick/text()") # *表示任意名字 print(result)
tips:Xpath 数数是从1开始
筛选
[数字] :表示第几个
[@属性=“值”] :表示筛选特定的属性值

相对查找:先从根目录里找到需要的当前目录 存入list
再在list里面 通过 “ ./ " 进行相对查找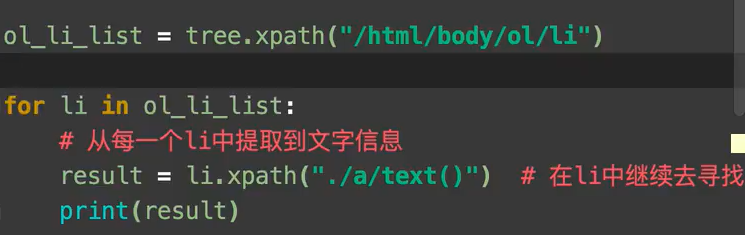
拿属性值 @操作符

技巧:
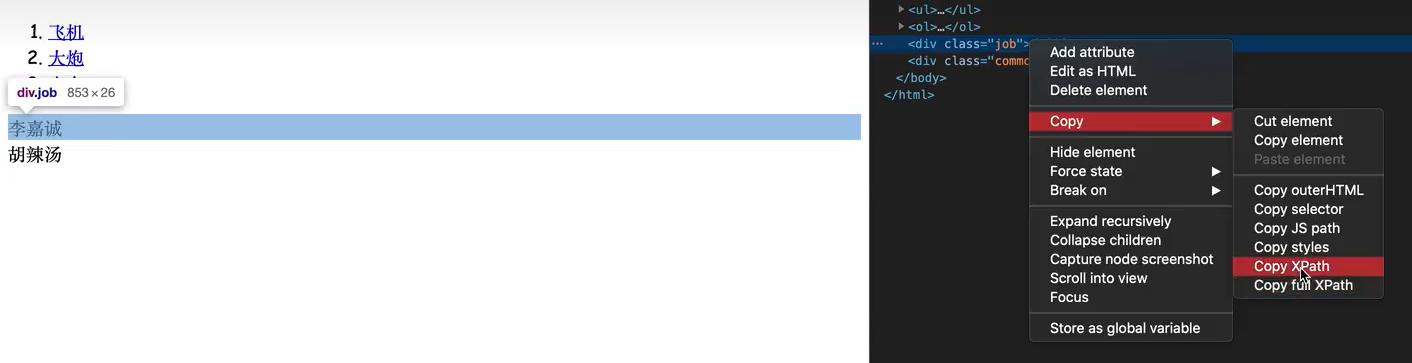
通过F12 检查 来快捷获取Xpath (可以自行微调)
hello my world
本文来自博客园,作者:slowlydance2me,转载请注明原文链接:https://www.cnblogs.com/slowlydance2me/p/16837325.html
