python 爬虫 -----爬取电影天堂
代码如下:
# 1. 定位到电影天堂最新电影更新栏目 # 2. 从其中提取到子页面的连接地址 # 3. 请求子页面的连接地址并拿到下载地址 import requests import re domain = "https://dy.dytt8.net/index2.htm" resp = requests.get(domain, verify=False)# verify=False 去掉了安全验证 resp.encoding = "gbk"#发现该网页使用的字符编码规范(charset)是"gb2312",而默认编码为utf-8,所以需要修改 print(resp.text)
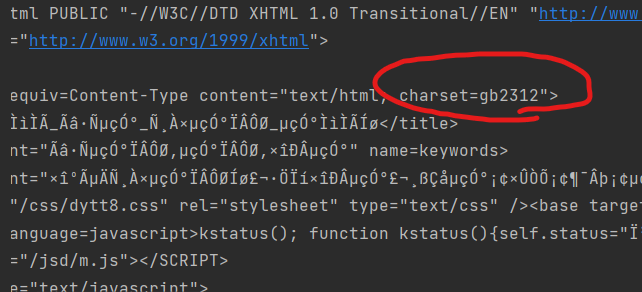
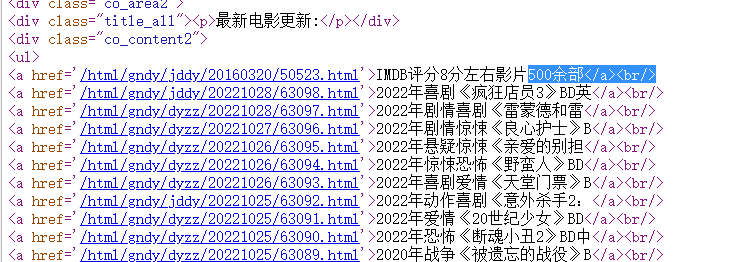
# 1. 定位到电影天堂最新电影更新栏目 obj1 = re.compile(r"最新电影更新.*?<ul>(?P<ul>.*?)</ul>", re.S) result1 = obj1.finditer(resp.text) for it in result1: ul = it.group('ul') print(ul)

# 2. 从其中提取到子页面的连接地址
obj2 = re.compile(r"<a href='(?P<href>.*?)'", re.S)
result2 = obj2.finditer(ul)
for itt in result2:
#print(itt.group('href'))
#拼接子页面的url地址: 域名 + 子页面地址
child_href_list = []
child_href = domain1 + itt.group('href').strip("/")
child_href_list.append(child_href)

# 3. 请求子页面的连接地址并拿到下载地址 提取子页面内容 for href in child_href_list: child_resp = requests.get(href, verify=False) child_resp.encoding = 'gbk' #print(child_resp.text) result3 = obj3.search(child_resp.text) print(result3.group("movie")) print(result3.group("download"))
完整代码
# 1. 定位到电影天堂必看片栏目 # 2. 从其中提取到子页面的连接地址 # 3. 请求子页面的连接地址并拿到下载地址 import requests import re import urllib3 urllib3.disable_warnings() domain = "https://dy.dytt8.net/index2.htm" domain1 = "https://dy.dytt8.net/" resp = requests.get(domain, verify=False)# verify=False 去掉了安全验证 resp.encoding = "gbk" #print(resp.text) #解析数据 # 1. 定位到电影天堂必看片栏目 obj1 = re.compile(r"最新电影更新.*?500余部</a><br/>(?P<ul>.*?)</ul>", re.S) obj2 = re.compile(r"<a href='(?P<href>.*?)'", re.S) obj3 = re.compile(r'◎片 名(?P<movie>.*?)<br />' r'.*?<br /><br /><br /><a target="_blank" href="(?P<download>.*?)">', re.S) result1 = obj1.finditer(resp.text) child_href_list = [] for it in result1: ul = it.group('ul') #print(ul) # 2. 从其中提取到子页面的连接地址 result2 = obj2.finditer(ul) for itt in result2: #print(itt.group('href')) #拼接子页面的url地址: 域名 + 子页面地址 child_href = domain1 + itt.group('href').strip("/") child_href_list.append(child_href) # 3. 请求子页面的连接地址并拿到下载地址 提取子页面内容 for href in child_href_list: child_resp = requests.get(href, verify=False) child_resp.encoding = 'gbk' #print(child_resp.text) result3 = obj3.search(child_resp.text) print(result3.group("movie")) print(result3.group("download"))
hello my world
本文来自博客园,作者:slowlydance2me,转载请注明原文链接:https://www.cnblogs.com/slowlydance2me/p/16834351.html
