python crawler 入门学习 -----初爬豆瓣
#进入豆瓣电影网站,点击排行榜、选择喜剧分类
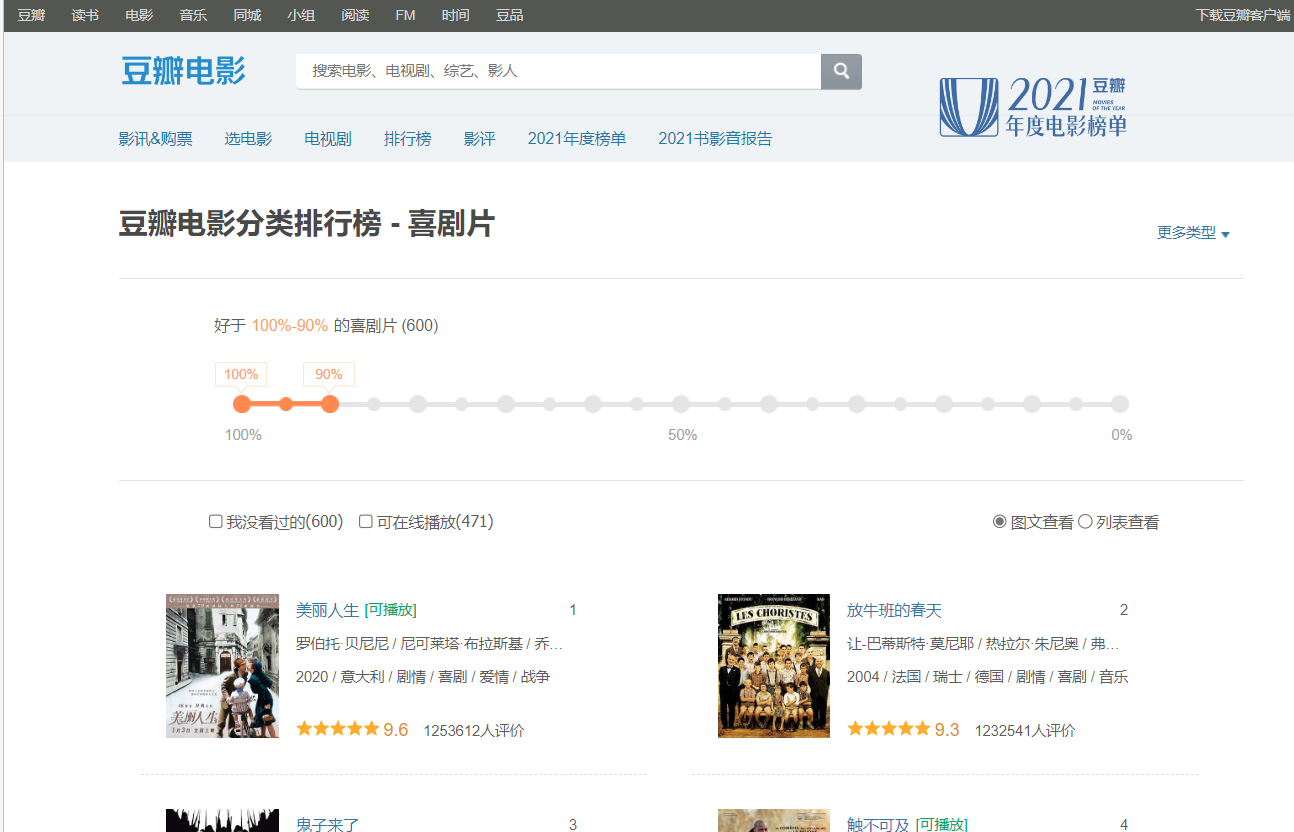
按下F12进入检查界面,点击Network(网络)、重新加载网站、点击typerank文件、选择XHR (XMLHttpRequest(简称xhr),是浏览器提供的JS对象,通过它可以请求到服务器上的数据资源。) 在preview中找到齐全的top文件、点击headers(标头),观察请求URL、观察请求方法(这里为get)、查看字符串参数
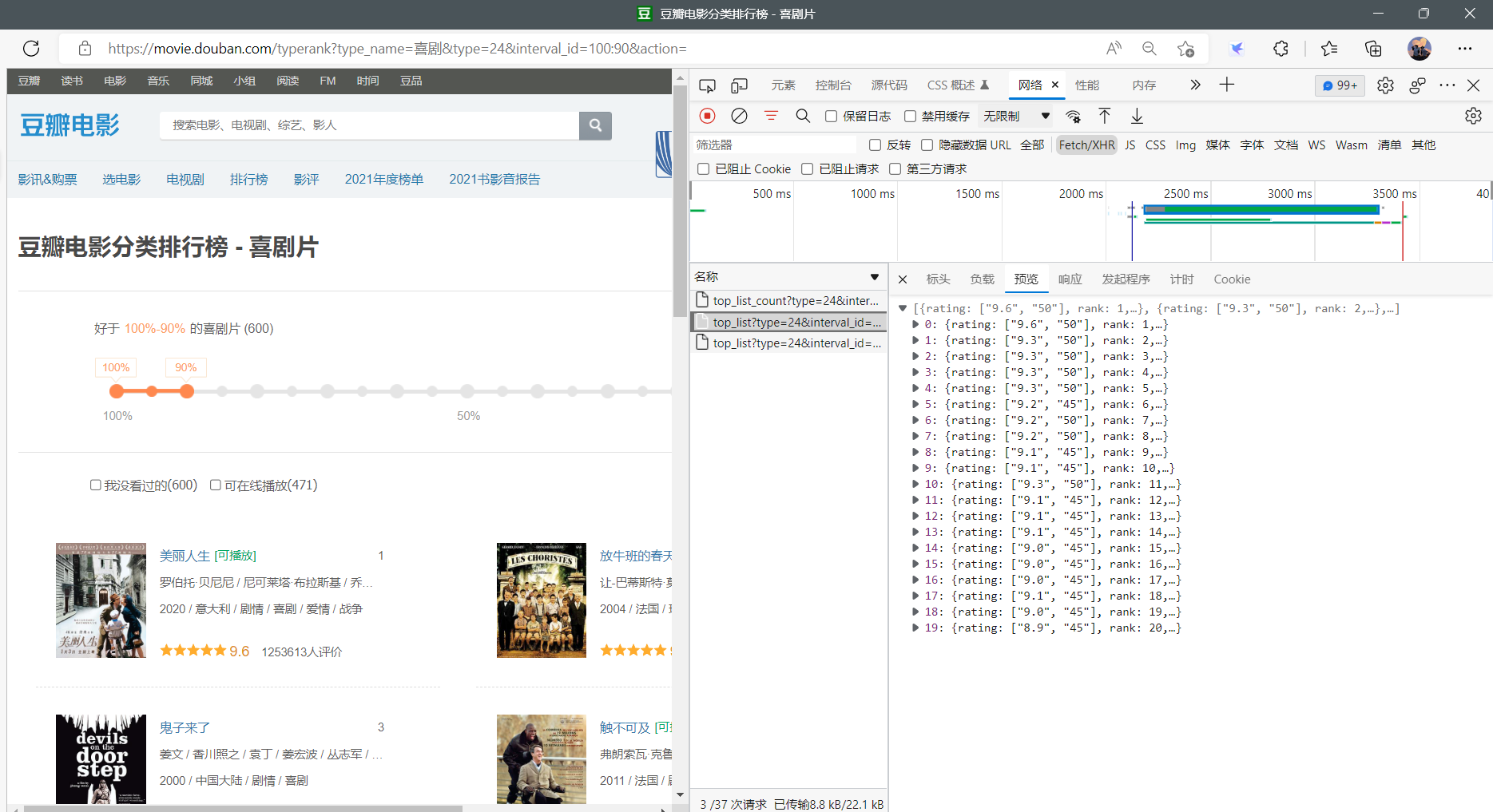
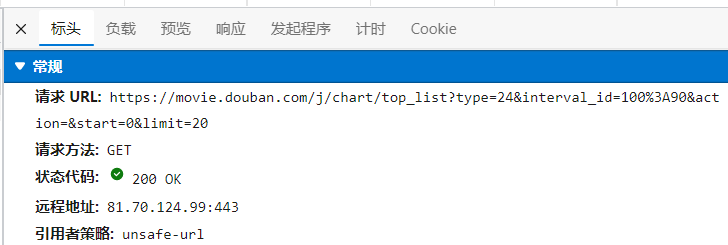

python代码:
import requests url = "https://movie.douban.com/j/chart/top_list" param = { "type": "24", "interval_id": "100:90", "action":"", "start": "0",#递增抓取从0~开始(加循环) "limit": "20", } dic = { "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/106.0.0.0 Safari/537.36 Edg/106.0.1370.52" } #存在反扒所以需要修改代理(Agent) resp = requests.get(url=url, params=param, headers=dic)#请求方法是get所以使用params print(resp.json())#打印json resp.close()#记得关闭resp
hello my world
本文来自博客园,作者:slowlydance2me,转载请注明原文链接:https://www.cnblogs.com/slowlydance2me/p/16833402.html
