

一、ES在项目中的使用
前面我们使用SpringBoot整合了ES的客户端,并且测试了ES的一些复杂操作。而es在项目中的使用场景:
1、作为全文检索引擎,承担所有项目里面的全文检索功能,京东手机首页,可以按照名字全文检索,也可以按照手机不同规格属性,进行全文检索,
2、承担日志的分析检索功能,可能需要对日志进行快速定位,日志也有检索需求,就可以将日志存储到es里面,有一个技术栈ELK logStash负责收集日志存到es里面
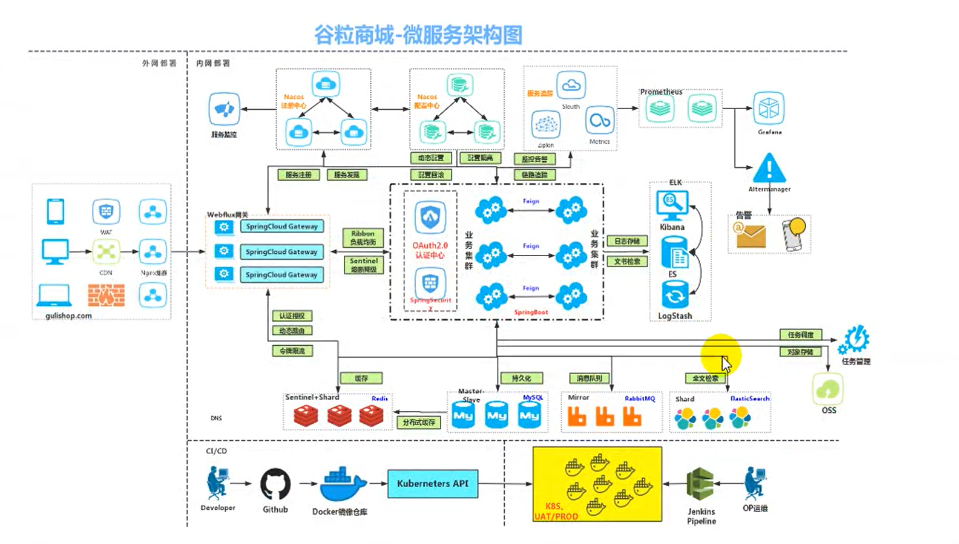
检索需要给es存储数据,不用mysql的原因,mysql全文检索功能没有es强大,这么复杂的检索分析数据,mysql性能远不及es,es数据是存在内存中的。商品都存在内存中够吗?es是天然支持分布式的,一个es不够可以多装几个es分布在不同服务器里面。然后就会将数据分片存储。容量不够,数量来凑。
所以我们要做的第一件事,先要将商品数据es里面存一份,方便做检索功能。
二、商品上架
商品从数据库里面保存到es里面这一过程,称为商品的上架。
点击上架,首先此商品状态改为上架状态,其次商品的数据要在es中保存,前端的商城项目要检索就在es中检索商品数据。要给es保存,首先分析需要保存哪些数据,虽然是在spu上架,但是要将什么信息保存进来呢?
2.1、sku在ES的存储模型
首先,es所有数据都是存在内存中的。虽然原生支持分布式,理论上容量无限。但是内存比硬盘贵得多,尽量能节省就节省。
第一个共识就是只保留页面有用的数据,没用的全部不保存。要用的时候,大不了再检索出来。已经查到skuid了,想要看sku的全部图片,包括整个商品的完整介绍,我们去数据库再查一遍就行了。
其次我们考虑哪些数据要进es,搜索名字的时候搜索的是sku的标题,sku信息得进来,可能还会根据sku价格区间进行检索,sku的销量,也就是说sku一些基本信息都是要用的。还要保存当前sku对象的规格信.
设计存储方式:
1. 方便检索
{
skuId:1,
spuId:11,
skuTitle:华为xxx,
price:988,
saleCount:99,
attrs:[
{尺寸:5寸},
{CPU:高通945},
{分辨率:全高清}
]
}
冗余:100万*20 = 1000000*2KB = 2G
2. 节省空间
sku索引:
{
skuId:1,
spuId:11,
skuTitle:华为xxx,
xxx
}
attr索引:
{
spuId:11,
attrs:[
{尺寸:5寸},
{CPU:高通945},
{分辨率:全高清}
]
}
搜索:小米; 粮食,手机,电器
10000个,4000个spu
分布,4000个spu对应的所有可能属性:
esClient:spuId:[4000个spuId] 4000*8=32000byte=32kb
32kb*10000=32GB第一种浪费空间但是节省时间,第二种节省空间,分到了两个索引下,一定会造成一些时间的浪费
分析:商品上架在es中是存sku还是spu?
1)、检索的时候输入名字,是需要按照sku的title进行全文检索的
2)、检索使用商品规格,规格是spu的公共属性,每个spu是一样的
3)、按照分类id进去的都是直接列出spu的,还可以切换。
4)、我们如果将sku的全量信息保存到es中(包括spu属性)就太多量字段了。
5)、我们如果将spu以及他包含的sku信息保存到es中,也可以方便检索。
但是sku属于spu的级联对象,在es中需要nested模型,这种性能差点。
6)、但是存储与检索我们必须性能折中。
7)、如果我们分拆存储,spu和attr一个索引,sku单独一个索引可能涉及的问题。
检索商品的名字,如“手机”,对应的spu有很多,我们要分析出这些spu的所有关联属性,再做一次查询,
就必须将所有spuid都发出去。假设有1万个数据,数据传输一次就10000*4=4MB;
并发情况下假设1000检索请求,那就是4GB的数据,传输阻寒时间会很长,业务更加无法继续。
所以,我们如下设计,这样才是文档区别于关系型数据库的地方,宽表设计,不能去考虑数据库范式。
PUT product
{
"mappings":{
"properties":{
"skuId":{
"type":"long"
},
"spuId":{
"type":"keyword"
},
"skuTitle":{
"type":"text",
"analyzer": "ik_smart"
},
"skuPrice":{
"type":"keyword"
},
"skuImg":{
"type":"text",
"analyzer": "ik_smart"
},
"saleCount":{
"type":"long"
},
"hasStock":{
"type":"boolean"
},
"hotScore":{
"type":"long"
},
"brandId":{
"type":"long"
},
"catelogId":{
"type":"long"
},
"brandName":{
"type":"keyword",
"index": false,
"doc_values": false
},
"brandImg":{
"type":"keyword",
"index": false,
"doc_values": false
},
"catalogName":{
"type":"keyword",
"index": false,
"doc_values": false
},
"attrs":{
"type":"nested",
"properties": {
"attrId":{
"type":"long"
},
"attrName":{
"type":"keyword",
"index":false,
"doc_values":false
},
"attrValue": {
"type":"keyword"
}
}
}
}
}
}2.2、nested数据类型场景
nested相关介绍:https://www.elastic.co/guide/en/elasticsearch/reference/7.4/nested.html
ES中数组类型的对象会被扁平化处理

 posted on
posted on

 浙公网安备 33010602011771号
浙公网安备 33010602011771号