一个真实数据集的完整机器学习解决方案(上)

更多精彩内容,欢迎关注公众号:数量技术宅。想要获取本期分享的完整策略代码,请加技术宅微信:sljsz01
引言
我们到底应该怎么学会、灵活使用机器学习的方法?技术宅做过小小的调研,许多同学会选择一本机器学习的书籍,或是一门机器学习的课程来系统性地学习。而在学完书本、课程后,并不清楚如何将这些理论、技术应用到实际的项目流程中。
这就好比,你的机器学习知识储备中已经有了一块块碎片化的机器学习知识,但不知道怎样才能将它们融合成一个整体。在本次的分享中,技术宅将借用国外机器学习大牛的数据,为大家系统的讲解一个针对真实数据集的完整机器学习解决方案,让你碎片化的知识,一文成型。
我们先来看,一个完整的机器学习工程的实现步骤:
1. 数据预处理
2. 探索性数据特征统计
3. 特征工程与特征选取
4. 建立基线
5. 机器学习建模
6. 超参数调优
7. 测试集验证
首先,我们来看本次机器学习模型想要解决的问题 。我们使用的是纽约市的公共可用建筑能源数据(数据源下载地址:
http://www.nyc.gov/html/gbee/html/plan/ll84_scores.shtml),想要实现的是通过该数据集,利用机器学习算法建立模型,该模型可以预测出纽约市建筑物的能源之星评分,而且我们要求实现的模型,即筛选出的影响评分的特征,尽可能具有可解释性。我们将使用范例数据集,通过Python对上述的每个步骤,分步实现。而该项目的完整代码,我们也将在文章的最后分享给大家。
通过对于我们想要实现的这一模型的简单分析,可以知道我们需要做的是一个有监督的回归机器学习模型:
其一,我们训练的数据集中,既有潜在的特征变量,也有目标,整个学习过程就是找到目标与特征之间的有效映射模型
其二,纽约市建筑物的能源之星评分,是一个0-100的连续变量,而非分类标签,构建的模型属于回归的范畴
简单分析完我们想要解决的问题,接下来,我们就遵循上述七个步骤,依次开发实现我们想要的模型。
数据预处理
在实际的数据集中,包含互联网数据、金融数据等,往往都会存在缺失值和异常值,我们进行机器学习的建模,第一步就需要对数据进行清洗,并在清洗的过程中处理这些缺失、异常。
我们使用pandas读取准备好的csv数据集

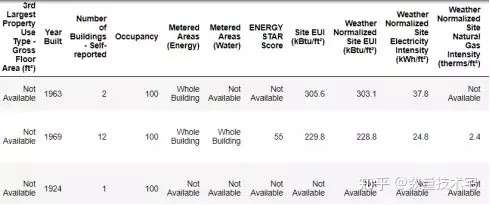
我们读入的Dataframe共有60列,此处只截取了一部分的数据因子。其中,能源之星得分(ENERGY STAR Score)是我们需要预测的目标列,而其余的列,我们都可以将它看作是潜在能够构成特征的变量,对于这些列,我们最好都能够清楚每一列的数据代表的含义,以便于我们能够更好的在将来解释这个模型。
对于我们想要预测的目标列,能源之星得分(ENERGY STAR Score),我们来做一个详细的说明:该得分来自纽约州每年所提交的能源使用情况报告,使用的是1~100的百分制排名,分数越高越好,代表该建筑物使用能源的效率的越高,相对来说更加节能环保。
接下来,我们使用dataframe的info()方法查看每一列的数据类型:

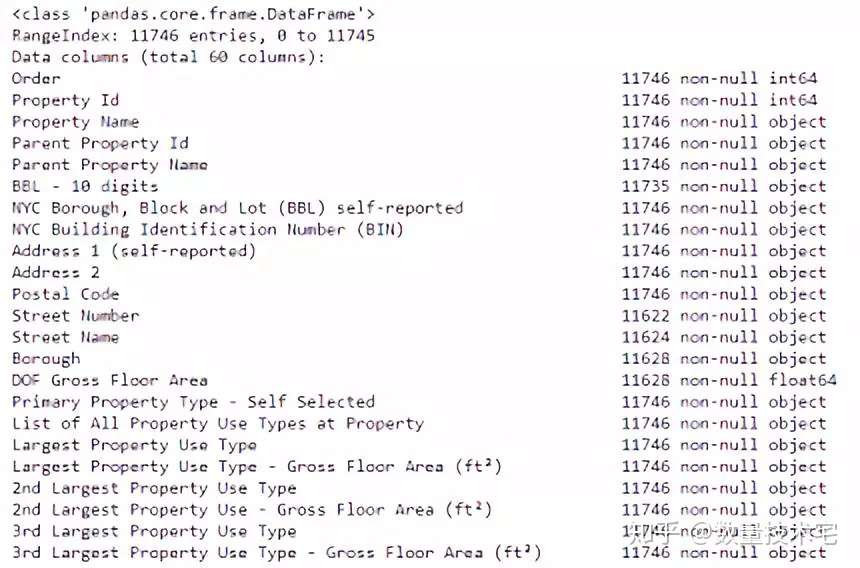
可以看到,其中有相当多的列属于objects类型(非数据类型)。如果我们需要用这些列来形成模型的特征,就需要将其转换为数值数据类型。我们将所有“Not Available”条目替换为np.nan,然后再将相关列转换为float数据类型,如此一来,所有的列,就都纳入分析范围了。
在处理完非数据类型的列后,我们在进行机器学习模型训练前,必须对缺失数据进行处理。缺失数据的处理方式一般有两者:删除、填充,删除指的是直接删除缺失数据对应的行或列,而填充可以有前向填充、均值填充等多种方式。对于样例中的数据集,我们先来看每列中缺失值的数量。
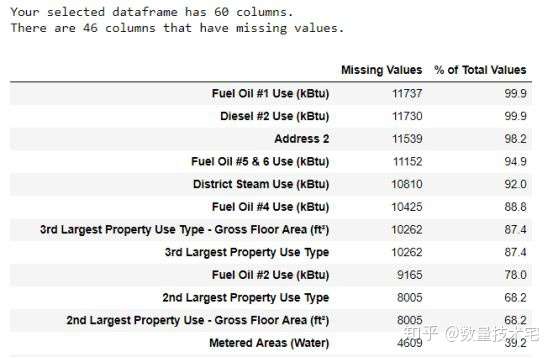
从上图的统计结果中,%of Total Values列表示缺失数据量占该列总数据量的百分比。对于缺失数据量超过一定比例的列,加入机器学习模型训练数据,显然会受到缺失值的影响,因此,我们考虑剔除缺失值超过一定比例的列数据。
除了缺失数据外,我们还需要对离群数据进行进一步的处理,离群数据或是由一些偶发现象产生,或是本身数据在存储的过程中出现了错误,它们会对特征的计算值产生较大的影响。我们对于离群值采用缩尾处理(Winsorize) ,具体是指,对于低于第一四分位数(Q1) - 3 *四分位差、高于第三四分位数(Q3) + 3 *四分位差的数值,进行缩尾。
处理完缺失数据、离群数据后,我们进入下一环节。
探索性数据特征统计
探索性数据统计分析(简称EDA)是对我们预处理完的数据进行探索性分析的阶段,通过EDA,我们可以初步知道数据的一些统计特征,以帮助我们更加合理的选择和使用数据构建特征。
单变量统计特征
由于所有数据列中,能源之星得分(ENERGY STAR Score)是最重要的、也是我们要预测的目标变量,于是我们先通过hist函数,画出能源之星得分的直方图,来看一下能源之星得分的一个具体的分布。
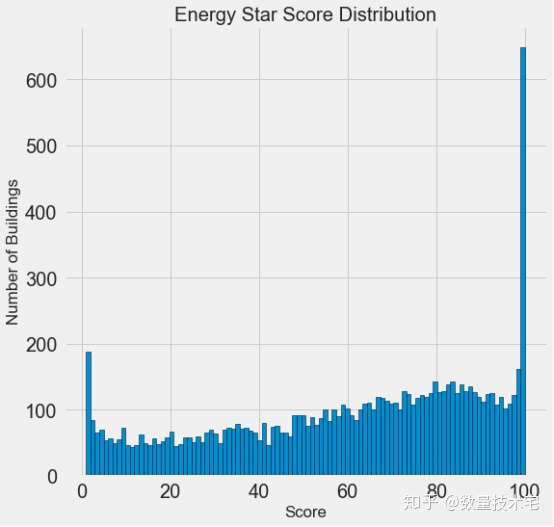
通过hist绘制的直方图可以看到,能源之星得分这一目标变量,既不是均匀分布,也不是类似正态分布那样的钟形曲线,而是一个两端分布频率极高,中间分布频率较低且不均匀的一个分布。
这个分布看上去比较奇怪,但如果仔细看一下能源之星得分的官方定义,它是基于“自我报告的能量使用”,也就是要求每个建筑物的所有者自行报告能源的使用情况,这就好比每个学生在考试的时候能自定成绩,那谁又不想拿满分呢?而对于0分频率的突然增高,或许是因为有些建筑物年久失修,连所有者也几乎放弃治疗了。
但是,无论能源之星得分的分布多么不合乎常理,它都是我们这个项目需要预测的唯一目标,我们更需要关注的是如何准确的预测分数。
分组特征
我们可以先用其中的某一个变量对所有的建筑物进行一次分类,再在每个分类中计算该分类的能源之星得分的数据分布。我们可以按类别对密度图进行着色,以查看变量对分布影响。我们首先查看建筑物分布类型对于能源之星得分的影响,如下是实现代码与可视化结果。
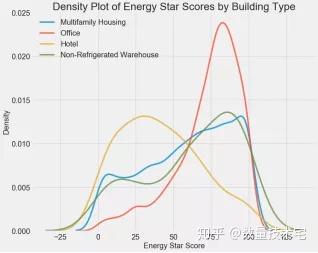
上图直观地反应出了不同建筑物类型,对于得分确实存在较大的影响,比如办公楼在高得分段分布频率更高,而酒店的低得分区域分布频率更高。因此,建筑物类型应该是一个比较重要的影响变量。由于建筑物类型是一个离散变量,我们可以通过对建筑物类型进行独热编码,将他们转换为数值变量。
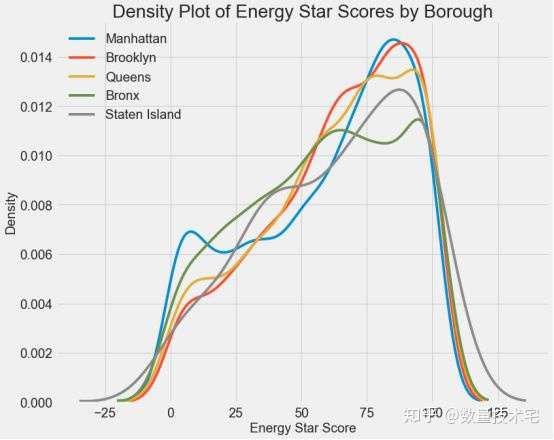
我们再来看一个纽约市下属不同行政区域对于能源之星得分的影响,从下图可以看出,不同区域对于得分基本上没有区分度,也能说明该变量大概率不是一个好的特征变量。
相关性统计
我们可以使用皮尔逊(Pearson)相关系数来衡量目标与其他数据列的相关关系,从而找到与目标变量相关性(正负)最强的列的排序。


我们分布截取了负相关性、正相关性最高的两组变量,可以看到,负相关性的变量,其相关性的绝对数值更高,并且最负相关的几项类别变量几乎都与能源使用强度(EUI)有关。EUI表示建筑物的能源使用量是其规模或其他特性的函数(越低越好)。直观来看,显著的负相关性是有意义的:随着EUI的增加,能源之星评分趋于下降。
双变量分析
我们还可以使用散点图来对双变量进行分析,并在散点图中用不同颜色,代表某个变量所区分的不同子类别,比如下图以不同建筑物的类型作为分类,绘制的能源之星评分与Site EUI(即负相关排名第一变量)的二维散点图。
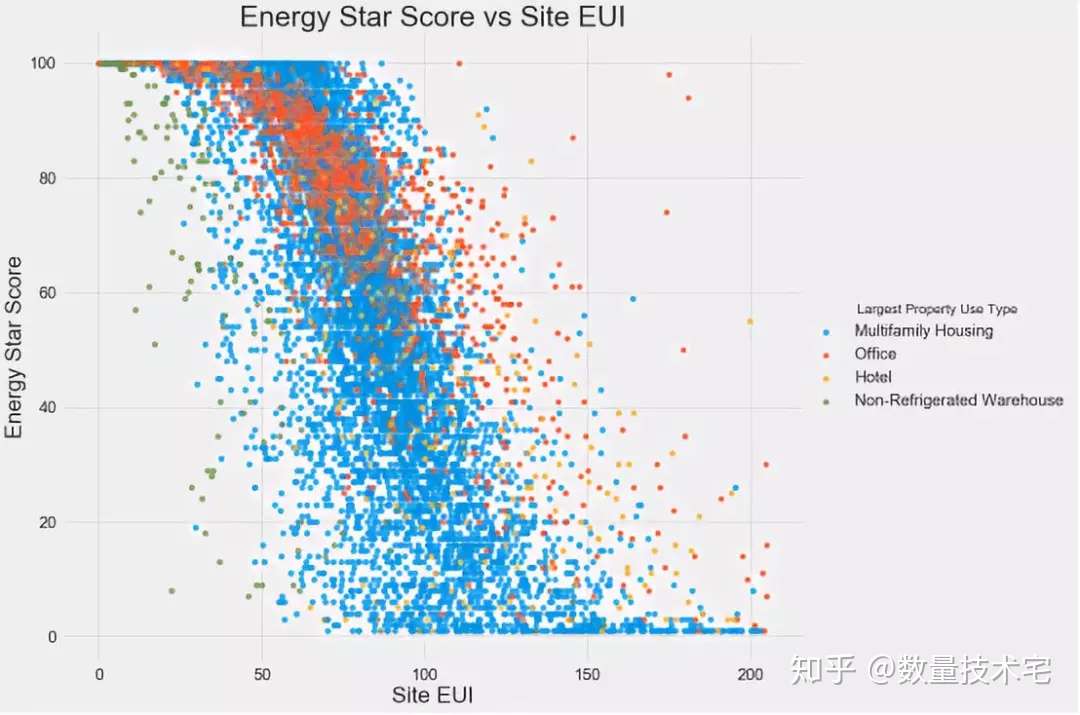
通过这个图,可以印证我们在此前计算的相关性系数,不同类型的建筑物,随着SiteEUI的减少,能源之星得分呈现上升态势。
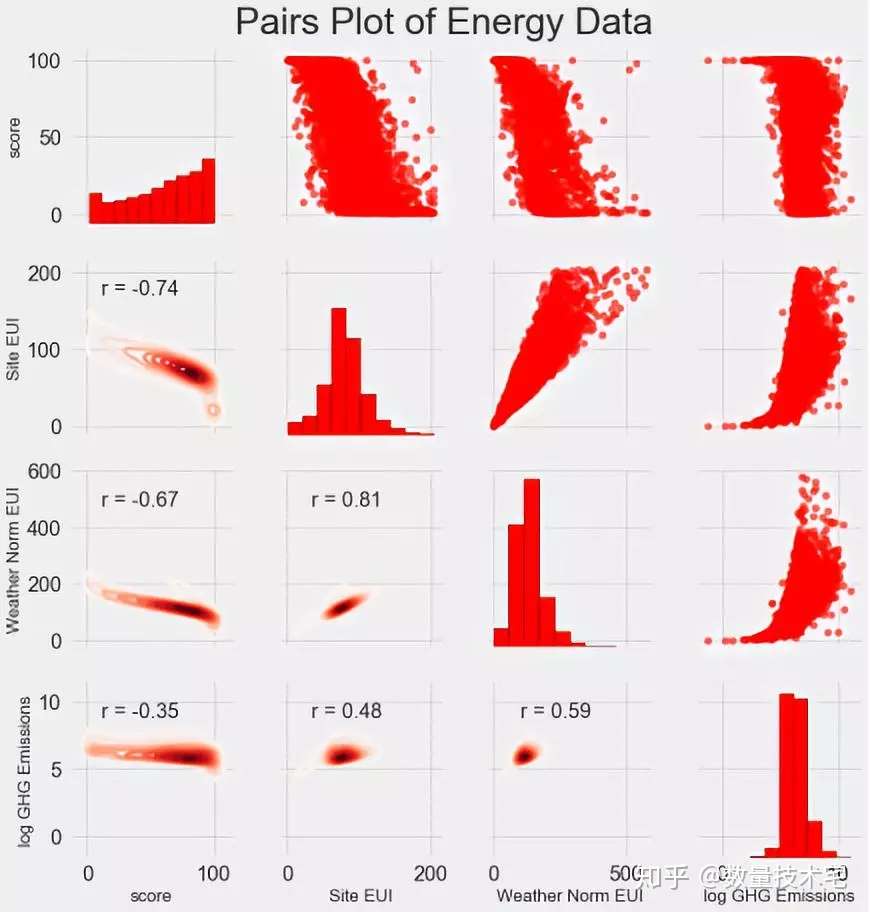
此外,成对图(Pairs Plot)也是一种很不错的分析工具,比如4*4的Pairs Plot,我们就能同时分析4组变量相互之间的联合分布与相关关系,我们使用seaborn可视化库和PairGrid函数来创建Pais Plot--上三角部分使用散点图,对角线使用直方图以及下三角形使用二维核密度图和相关系数。
特征工程与特征选取
特征工程和特征选取,可以说是整个机器学习项目中最为关键的一步。一个机器学习模型在样本内外能否有优异的表现,模型的构建与参数的选择,并不是最重要的,最重要的还是特征对于目标的预测能力。如果特征的预测能力足够强,即使简单的线性模型,也能有较好的拟合能力。我们先来简单解释一下特征工程和特征选取:
特征工程:特征工程是指通过原始数据,提取或创建新特征,在这个过程中,可能需要对部分原始变量进行转换。例如对于某些非正态分布数据取自然对数、对分类变量进行独热(one-hot)编码,使得他们能够被纳入模型训练中。
特征选取:特征选取在实际过程中是一项需要经验的操作,往往通过删除无效或重复的数据特征以帮助模型更好地学习和总结数据特征并创建更具可解释性的模型。特征选择更多的是对特征做减法,只留下那些相对重要的特征,在删除的过程中,需要特别注意避免重要特征被删除的情况。
机器学习模型只能从我们提供的数据和特征中学习,所以必须确保数据中有预测我们目前所需要的全部数据,如果我们提供的数据特征维度不够丰富,最终的学习效果也许会达不到我们的预期。
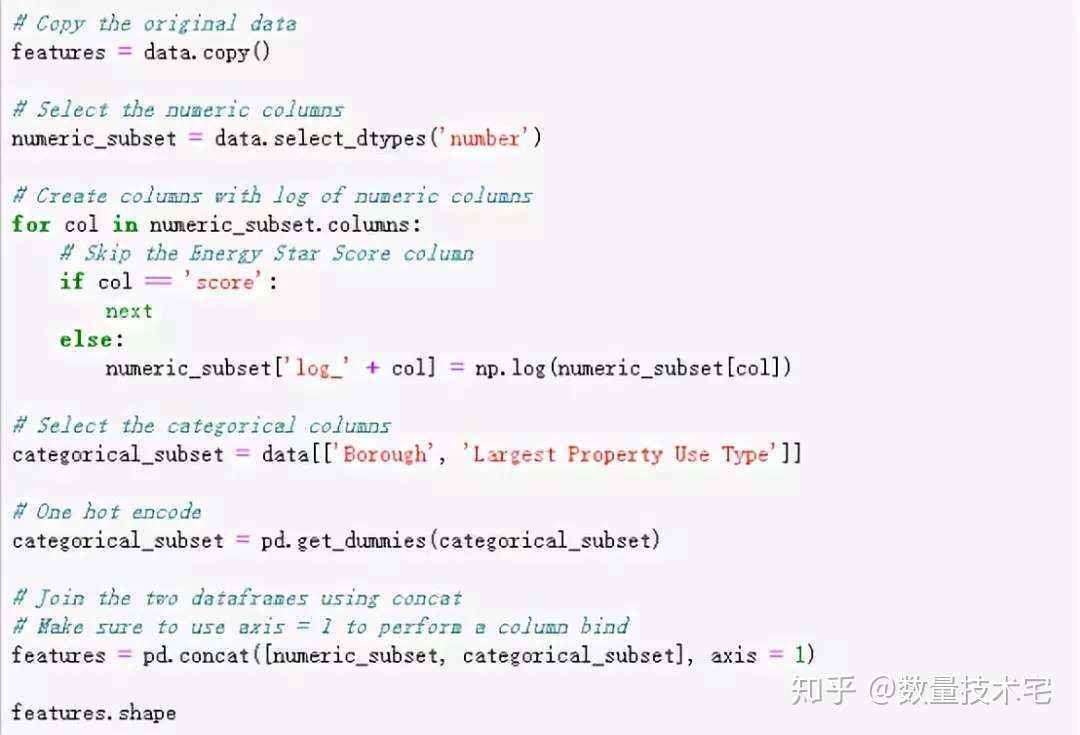
接下来,我们对本次项目的数据集分两块进行特征工程。第一是对于分类变量,采用独热(one-hot)编码进行分类,转换为数值。独热(one-hot)编码在模型的训练数据中包含分类变量时,应用很常见。比如,我们的某个变量包含三个类别,那么就用001、010、100三个独热编码,分别对应三个原始分类。
第二是对数值型数据取对数。我们知道,很多原始的数据的分布都不是正态分布,如果我们直接将数据放入模型训练,可能存在由数据偏态分布带来的潜在偏差,于是,我们对所有数值特征取自然对数并添加到原始数据中。以下是上述两个特征工程操作步骤的Python代码实现。
完成上述特征工程后,我们的变量维度又增加了许多(独热编码、指数变换),这其中大概率存在着一些冗余的变量,比如高度相关的变量。以下图为例,Site EUI与Weather Norm EUI,这两个变量的相关系数高达0.997,显然我们不需要都做保留。
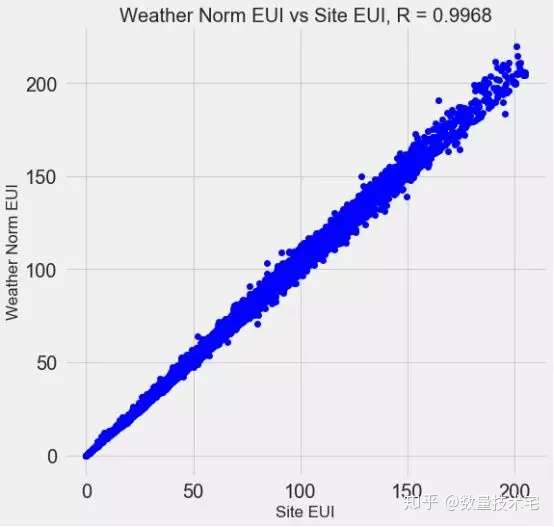
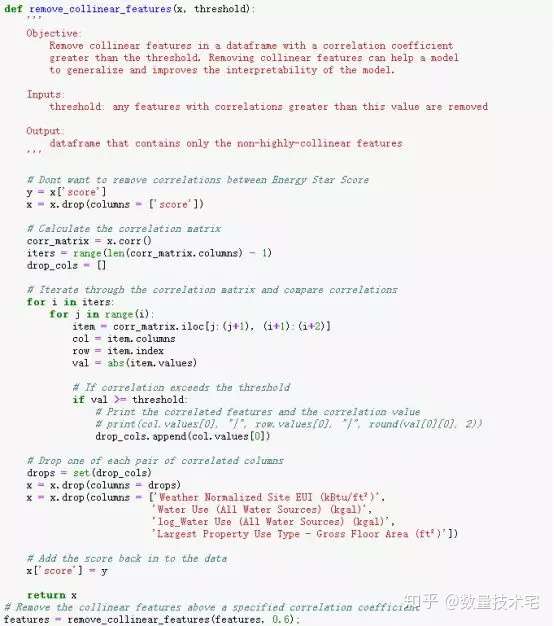
这些相关性很高的变量,在模型中我们称之为共线性(collinear),消除变量之间的共线性,能够让机器学习模型更鲁棒并且具有更强的可解释性。我们将使用相关系数来识别和删除共线性的冗余特征,具体做法是,我们通过循环遍历,两两计算除目标变量外所有变量的相关系数,当某两个变量相关系数大于一定阈值,我们就放弃其一,具体实现代码如下。筛选完成后,剩下64列特征和1列目标特征(能源之星得分)。

建立基线(Baseline)
在完成特征工程和冗余特征的筛选后,我们开始下一步工作:建立模型绩效对比的基准,我们也把它称之为基线(Baseline)。我们通过基线来与最终模型的绩效评估指标对比,如果机器学习最终训练得到的模型没有超越基线,那么说明该模型并不适用该数据集,或是我们的特征工程特征选取存在着问题。
对于回归问题,一个合理的基线是通过预估测试集中所有示例的运行结果为训练集中目标结果的均值,并根据均值计算平均绝对误差(MAE)。选择MAE作为基线有两方面考虑,一是它的计算简单,二是其可解释性强。
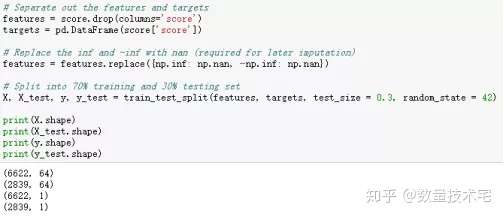
在计算基线前,我们需要先将原始数据划分为训练集和测试集,这也是为了在后续的处理过程中,绝对避免数据泄露的发生。我们采用比较常规的70%原始数据进行训练,30%用于测试。
划分完训练与测试集,我们再计算MAE的数值,并计算基线。由下图结果可以看到,计算得出预估模型表现为66,在测试集中的误差约为25左右(百分制)。可以说是比较容易达到的性能。

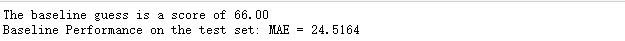
深夜码字,困意袭来,上篇暂且先到这里,下篇争取明天更完
关注 “数量技术宅”不迷路(下篇精彩继续),您的点赞、转发,是我输出干货,最大的动力


往期干货分享推荐阅读
【数量技术宅|量化投资策略系列分享】基于指数移动平均的股指期货交易策略
AMA指标原作者Perry Kaufman 100+套交易策略源码分享
【数量技术宅|金融数据系列分享】套利策略的价差序列计算,恐怕没有你想的那么简单
【数量技术宅|量化投资策略系列分享】成熟交易者期货持仓跟随策略
【数量技术宅|金融数据分析系列分享】为什么中证500(IC)是最适合长期做多的指数
商品现货数据不好拿?商品季节性难跟踪?一键解决没烦恼的Python爬虫分享
【数量技术宅|金融数据分析系列分享】如何正确抄底商品期货、大宗商品

 浙公网安备 33010602011771号
浙公网安备 33010602011771号