
Shell Sort(希尔排序)
近日学习了Shell Sort,也就是希尔排序,也称递减增量排序算法。在1959年由DL.Shell提出于1959年提出,由此得名。
此版本算法是在插入排序(Insertion Sort)基础上,将数组分成了h份(gap).也就是在数组中每隔h个数取出一个数,为一个子数组。先在子数组上进行排序,然后不断减小h的大小,直到h == 1 时,也就是完全变成插入排序的时候,排序完成。
算法复杂度取决于h(步长/步进)的选择,在最差的时候,也就是h == 1的时候,希尔排序就变成了插入排序,复杂度为O(n2)。而且算法的性能不仅取决于h,还取决于h之间的数学性质,比如它们之间的公因式(Algorithm 4th).
但是,很多论文研究了各种不同的递增序列,都无法证明某个序列的性质是最好的。
以下引自Wiki:
步长的选择是希尔排序的重要部分。只要最终步长为1任何步长串行都可以工作。算法最开始以一定的步长进行排序。然后会继续以一定步长进行排序,最终算法以步长为1进行排序。当步长为1时,算法变为插入排序,这就保证了数据一定会被排序。
Donald Shell 最初建议步长选择为
并且对步长取半直到步长达到 1。虽然这样取可以比
类的算法(插入排序)更好,但这样仍然有减少平均时间和最差时间的余地。 可能希尔排序最重要的地方在于当用较小步长排序后,以前用的较大步长仍然是有序的。比如,如果一个数列以步长5进行了排序然后再以步长3进行排序,那么该数列不仅是以步长3有序,而且是以步长5有序。如果不是这样,那么算法在迭代过程中会打乱以前的顺序,那就不会以如此短的时间完成排序了。
步长串行 最坏情况下复杂度 已知的最好步长串行是由Sedgewick提出的 (1, 5, 19, 41, 109,...),该串行的项来自 9 * 4^i - 9 * 2^i + 1 和 4^i - 3 * 2^i + 1 这两个算式[1].这项研究也表明“比较在希尔排序中是最主要的操作,而不是交换。”用这样步长串行的希尔排序比插入排序和堆排序都要快,甚至在小数组中比快速排序还快,但是在涉及大量数据时希尔排序还是比快速排序慢。
另一个在大数组中表现优异的步长串行是(斐波那契数列除去0和1将剩余的数以黄金分区比的两倍的幂进行运算得到的数列):(1, 9, 34, 182, 836, 4025, 19001, 90358, 428481, 2034035, 9651787, 45806244, 217378076, 1031612713, …)[2]
 并且对步长取半直到步长达到 1。虽然这样取可以比
并且对步长取半直到步长达到 1。虽然这样取可以比 类的算法(插入排序)更好,但这样仍然有减少平均时间和最差时间的余地。 可能希尔排序最重要的地方在于当用较小步长排序后,以前用的较大步长仍然是有序的。比如,如果一个数列以步长5进行了排序然后再以步长3进行排序,那么该数列不仅是以步长3有序,而且是以步长5有序。如果不是这样,那么算法在
类的算法(插入排序)更好,但这样仍然有减少平均时间和最差时间的余地。 可能希尔排序最重要的地方在于当用较小步长排序后,以前用的较大步长仍然是有序的。比如,如果一个数列以步长5进行了排序然后再以步长3进行排序,那么该数列不仅是以步长3有序,而且是以步长5有序。如果不是这样,那么算法在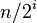

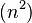
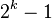

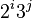
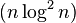
此版本算法与复杂递增序列性能相近。
Source Code in Java:
1 public static void ShellSort(Comparable[] a) { 2 int N = a.length; 3 int h = 1; 4 while(h < N / 3) 5 h = 3 * h + 1; 6 while(h >= 1) { 7 for(int i = h; i < N; i++) { 8 for(int j = i; j >= h && less(a[j], a[j-h]); j -= h) { 9 exch(a, j, j-h); 10 } 11 } 12 h /= 3; 13 } 14 }
一般说来,h或(length - h)就是所分的组数:
所以也可以这么写:
Source Code in C++:
1 void ShellSort(int a[], int n) 2 { 3 4 // 此版本下 h 从 n / 2 起步 5 for (int h = n / 2; h > 0; h /= 2) 6 { 7 // 可以从前面开始数,有 h 组 8 for (int i = 0 ;i < h; i++) 9 { 10 for (int j = i + h; j < n; j += h) 11 { 12 // 如果a[j] < a[j-h],则寻找a[j]位置,并将后面数据的位置都后移。 13 // 这样做比exch效率稍高 in Algorithm 4th 14 if (a[j] < a[j - h]) 15 { 16 int temp = a[j]; 17 int k = j - h; 18 while (k >= 0 && a[k] > temp) 19 { 20 a[k + h] = a[k]; 21 k -= h; 22 } 23 a[k + h] = temp; 24 } 25 } 26 } 27 28 } 29 }
图示实例如下:

将各自子序列用插入排序法排序。
完整版本图示:

Vane_Tse On the Road. 2014-06-19 11:20:07

 浙公网安备 33010602011771号
浙公网安备 33010602011771号