



kubernetes生态--ELK服务
elk是一套收集搜索展示日志的一套服务,
架构:
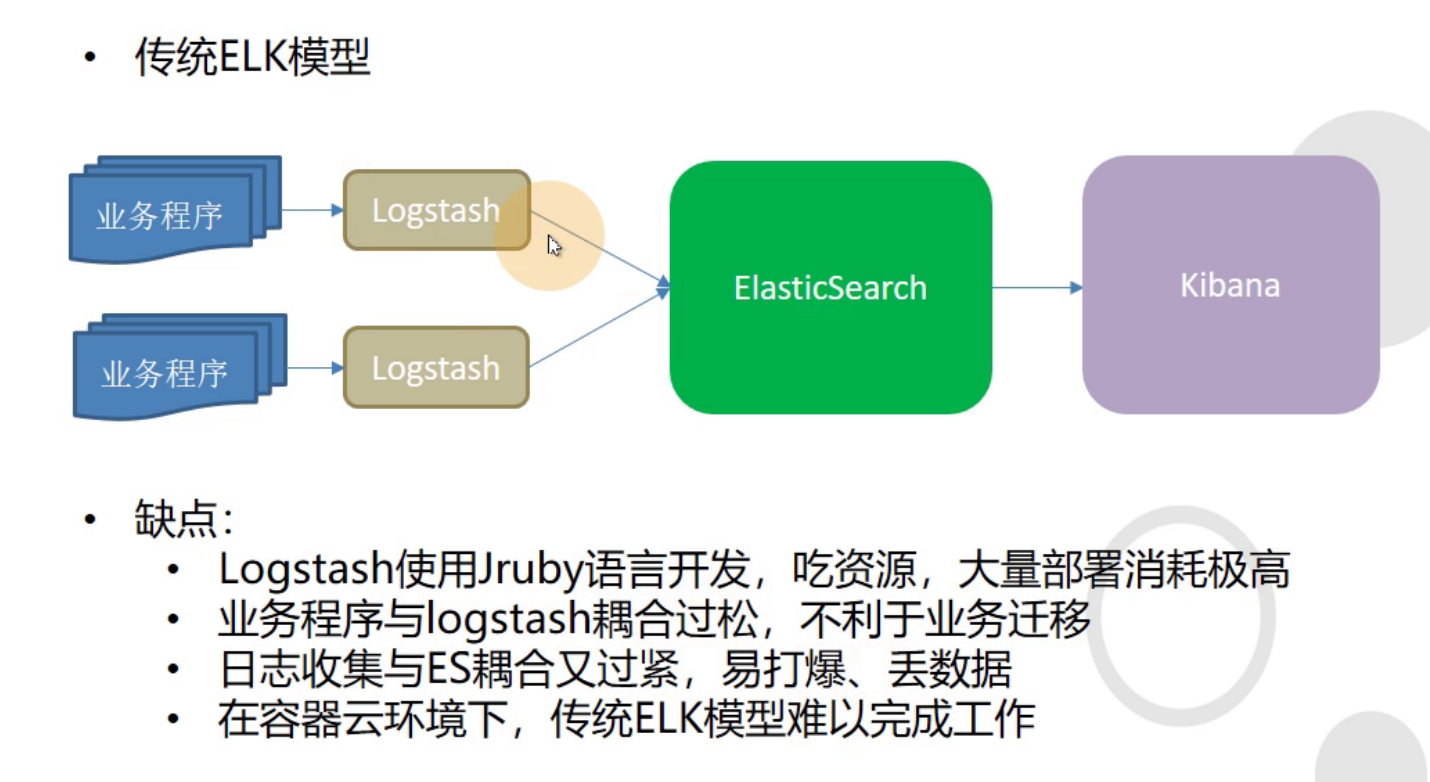
优化后的架构:更适合k8s集群,使用topic区分服务,使用index-patterm区分环境(prod,test)
将filebeat使用边车模式与容器绑定到一起,中间采用kafka来做异步。
改造项目,将我们原来的dubbo-demo-consumer改造成tomcat项目,然后交付tomcat到k8s:
下载tomcat:
# wget http://mirrors.tuna.tsinghua.edu.cn/apache/tomcat/tomcat-8/v8.5.50/bin/apache-tomcat-8.5.50.tar.gz
准备制作dockerfile:
# mkdir /data/dockerfile/tomcat # tar -zxf apache-tomcat-8.5.50.tar.gz -C /data/dockerfile/tomcat/
# cd /data/dockerfile/tomcat
# vim Dockerfile
From harbor.od.com/public/jre:8u112 RUN /bin/cp /usr/share/zoneinfo/Asia/Shanghai /etc/localtime &&\ echo 'Asia/Shanghai' >/etc/timezone ENV CATALINA_HOME /opt/tomcat ENV LANG zh_CN.UTF-8 ADD apache-tomcat-8.5.50/ /opt/tomcat ADD config.yml /opt/prom/config.yml ADD jmx_javaagent-0.3.1.jar /opt/prom/jmx_javaagent-0.3.1.jar WORKDIR /opt/tomcat ADD entrypoint.sh /entrypoint.sh CMD ["/entrypoint.sh"]
优化一下tomcat:
1、关闭tomcat与apache前端通信的端口:
# vi /data/dockerfile/tomcat/apache-tomcat-8.5.50/conf/server.xml

2、关闭无用的日志:
# vim /data/dockerfile/tomcat/apache-tomcat-8.5.50/conf/logging.properties
删除handle:
找到handlers,删除后面的3跟4


注释掉下面的:

将其他的日志level修改为:INFO
根据上面的dockerfile准备相关的文件:
jmx_javaagent-0.3.1.jar --之前在部署jre8的底包镜像时候,已经下载过了,直接拿过来用
entrypoint.sh
config.yml
entrypoint.sh
#!/bin/bash M_OPTS="-Duser.timezone=Asia/Shanghai -javaagent:/opt/prom/jmx_javaagent-0.3.1.jar=$(hostname -i):${M_PORT:-"12346"}:/opt/prom/config.yml" C_OPTS=${C_OPTS} MIN_HEAP=${MIN_HEAP:-"128m"} MAX_HEAP=${MAX_HEAP:-"128m"} JAVA_OPTS=${JAVA_OPTS:-"-Xmn384m -Xss256k -Duser.timezone=GMT+08 -XX:+DisableExplicitGC -XX:+UseConcMarkSweepGC -XX:+UseParNewGC -XX:+CMSParallelRemarkEnabled -XX:+UseCMSCompactAtFullCollection -XX:CMSFullGCsBeforeCompaction=0 -XX:+CMSClassUnloadingEnabled -XX:LargePageSizeInBytes=128m -XX:+UseFastAccessorMethods -XX:+UseCMSInitiatingOccupancyOnly -XX:CMSInitiatingOccupancyFraction=80 -XX:SoftRefLRUPolicyMSPerMB=0 -XX:+PrintClassHistogram -Dfile.encoding=UTF8 -Dsun.jnu.encoding=UTF8"} CATALINA_OPTS="${CATALINA_OPTS}" JAVA_OPTS="${M_OPTS} ${C_OPTS} -Xms${MIN_HEAP} -Xmx${MAX_HEAP} ${JAVA_OPTS}" sed -i -e "1a\JAVA_OPTS=\"$JAVA_OPTS\"" -e "1a\CATALINA_OPTS=\"$CATALINA_OPTS\"" /opt/tomcat/bin/catalina.sh cd /opt/tomcat && /opt/tomcat/bin/catalina.sh run 2>&1 >> /opt/tomcat/logs/stdout.log
config.yml
--- rules: - pattern: '.*'
制作docker镜像:
# docker build . -t harbor.od.com/base/tomcat:v8.5.50 # docker push harbor.od.com/base/tomcat:v8.5.50
在jenkins上添加适用tomcat的流水线项目:

执行build

启动test和prod上的apollo服务,修改之前dubbo-demo-consumer项目的资源配置清单:将镜像修改为tomcat那版镜像
然后启动dubbo-demo-service和dubbo-demo-consumer
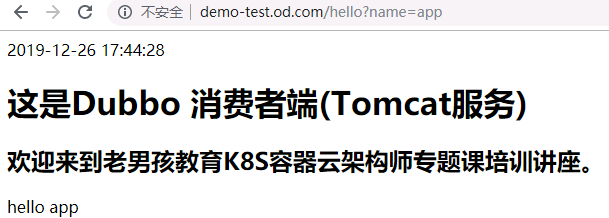
tomcat启动的dubbo-demo-web服务已经起来了。
部署elasticsearch:
由于elasticsearch是有状态服务,所以采用二进制方式部署:由于资源有限,我们部署单节点,部署到7-12上
elastic 官方地址
建议所有组件版本用一致的版本:
我们这里使用6.8.6版本:
# cd /opt/src # wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-6.8.6.tar.gz
# tar -zxf elasticsearch-6.8.6.tar.gz -C /opt/
# ln -s /opt/elasticsearch-6.8.6/ /opt/elasticsearch
配置elastic:
创建存储数据和日志的目录:
# mkdir -p /data/elasticsearch/{data,logs}
#修改配置文件,将以下配置进行修改。其他不动
# vi config/elasticsearch.yml
cluster.name: es.od.com node.name: hdss7-12.host.com path.data: /data/elasticsearch/data path.logs: /data/elasticsearch/logs bootstrap.memory_lock: true network.host: 10.4.7.12 http.port: 9200
优化ES JVM:生产环境建议最大不要超过32G。
# vi config/jvm.options
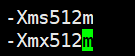
创建es用户:-M参数为不创建家目录。
# useradd -s /bin/bash -M es
# chown -R es.es /opt/elasticsearch-6.8.6/
# chown -R es.es /data/elasticsearch/
调整文件描述符配置:
# vi /etc/security/limits.d/es.conf
es hard nofile 65536 es soft fsize unlimited es hard memlock unlimited es soft memlock unlimited
调整内核参数:
参数说明:限制一个进程可以拥有的VMA(虚拟内存区域)的数量。虚拟内存区域是一个连续的虚拟地址空间区域。在进程的生命周期中,每当程序尝试在内存中映射文件,链接到共享内存段,或者分配堆空间的时候,这些区域将被创建。调优这个值将限制进程可拥有VMA的数量。限制一个进程拥有VMA的总数可能导致应用程序出错,因为当进程达到了VMA上线但又只能释放少量的内存给其他的内核进程使用时,操作系统会抛出内存不足的错误。如果你的操作系统在NORMAL区域仅占用少量的内存,那么调低这个值可以帮助释放内存给内核用。
# sysctl -w vm.max_map_count=262144 # echo "vm.max_map_count=262144" >> /etc/sysctl.conf # sysctl -p
启动es:
# su -c "/opt/elasticsearch/bin/elasticsearch -d" es
# netstat -lntp | grep 9200

调整es日志模板,由于我们没有只有一个节点,所以我们将replicas调整为0
curl -H "Content-Type:application/json" -XPUT http://10.4.7.12:9200/_template/k8s -d '{ "template" : "k8s*", "index_patterns": ["k8s*"], "settings": { "number_of_shards": 5, "number_of_replicas": 0 } }'
部署kafka:官方地址
版本建议不要超过2.2.0,因为我们要部署的kafka-manager最高支持到2.2.0,部署到7-11上
# cd /opt/src # wget https://archive.apache.org/dist/kafka/2.2.0/kafka_2.12-2.2.0.tgz
# tar -zxf kafka_2.12-2.2.0.tgz -C /opt/
# ln -s /opt/kafka_2.12-2.2.0/ /opt/kafka
配置kafka:
# mkdir -p /data/kafka/logs
# vi config/server.properties
修改以下配置:
log.dirs=/data/kafka/logs zookeeper.connect=localhost:2181 log.flush.interval.messages=10000 log.flush.interval.ms=1000
添加以下配置:
delete.topic.enable=true host.name=hdss7-11.host.com
启动kafka:
# bin/kafka-server-start.sh -daemon config/server.properties

交付kafka-manager到k8s,kafka-web管理工具:github地址
介绍两种部署方法:
1、自己制作dockerfile:我们使用这种方法
# mkdir /data/dockerfile/kafka-manager
# cd /data/dockerfile/kafka-manager
# vi Dockerfil
FROM hseeberger/scala-sbt ENV ZK_HOSTS=10.4.7.11:2181 \ KM_VERSION=2.0.0.2 RUN mkdir -p /tmp && \ cd /tmp && \ wget https://github.com/yahoo/kafka-manager/archive/${KM_VERSION}.tar.gz && \ tar xxf ${KM_VERSION}.tar.gz && \ cd /tmp/kafka-manager-${KM_VERSION} && \ sbt clean dist && \ unzip -d / ./target/universal/kafka-manager-${KM_VERSION}.zip && \ rm -fr /tmp/${KM_VERSION} /tmp/kafka-manager-${KM_VERSION} WORKDIR /kafka-manager-${KM_VERSION}
# docker build . -t harbor.od.com/public/kafka-manager:v2.0.0.2
2、直接下载docker镜像:docker地址
不论使用哪种方法,制作完docker镜像后,上传到自己的私有仓库中:
# docker push harbor.od.com/infra/kafka-manager:v2.0.0.2
制作资源配置清单:
1、dp.yaml
# cd /data/k8s-yaml/ # mkdir kafka-manager # vi dp.yaml
kind: Deployment apiVersion: extensions/v1beta1 metadata: name: kafka-manager namespace: infra labels: name: kafka-manager spec: replicas: 1 selector: matchLabels: app: kafka-manager strategy: type: RollingUpdate rollingUpdate: maxUnavailable: 1 maxSurge: 1 revisionHistoryLimit: 7 progressDeadlineSeconds: 600 template: metadata: labels: app: kafka-manager spec: containers: - name: kafka-manager image: harbor.od.com/infra/kafka-manager:v2.0.0.2 imagePullPolicy: IfNotPresent ports: - containerPort: 9000 protocol: TCP env: - name: ZK_HOSTS value: zk1.od.com:2181 - name: APPLICATION_SECRET value: letmein imagePullSecrets: - name: harbor terminationGracePeriodSeconds: 30 securityContext: runAsUser: 0
2、svc.yaml
kind: Service apiVersion: v1 metadata: name: kafka-manager namespace: infra spec: ports: - protocol: TCP port: 9000 targetPort: 9000 selector: app: kafka-manager
3、ingress.yaml
kind: Ingress apiVersion: extensions/v1beta1 metadata: name: kafka-manager namespace: infra spec: rules: - host: km.od.com http: paths: - path: / backend: serviceName: kafka-manager servicePort: 9000
添加域名解析:

应用资源配置清单:
# kubectl apply -f http://k8s-yaml.od.com/kafka-manager/dp.yaml # kubectl apply -f http://k8s-yaml.od.com/kafka-manager/svc.yaml # kubectl apply -f http://k8s-yaml.od.com/kafka-manager/ingress.yaml
等待容器起来以后,访问km.od.com:
配置kafka:
其他默认就可以。
以边车模式交付filebeat到k8s,绑定到dubbo-demo-web的pod上:
制作dockerfile:红色部门是官网对应版本的sha的值

# mkdir /data/dockerfile/filebeat # cd /data/dockerfile/filebeat # vi Dockerfile
FROM debian:jessie ENV FILEBEAT_VERSION=7.5.1 \ FILEBEAT_SHA1=daf1a5e905c415daf68a8192a069f913a1d48e2c79e270da118385ba12a93aaa91bda4953c3402a6f0abf1c177f7bcc916a70bcac41977f69a6566565a8fae9c RUN set -x && \ apt-get update && \ apt-get install -y wget && \ wget https://artifacts.elastic.co/downloads/beats/filebeat/filebeat-${FILEBEAT_VERSION}-linux-x86_64.tar.gz -O /opt/filebeat.tar.gz && \ cd /opt && \ echo "${FILEBEAT_SHA1} filebeat.tar.gz" | sha512sum -c - && \ tar xzvf filebeat.tar.gz && \ cd filebeat-* && \ cp filebeat /bin && \ cd /opt && \ rm -rf filebeat* && \ apt-get purge -y wget && \ apt-get autoremove -y && \ apt-get clean && rm -rf /var/lib/apt/lists/* /tmp/* /var/tmp/* COPY docker-entrypoint.sh / ENTRYPOINT ["/docker-entrypoint.sh"]
制作docker-entrypoint.sh:
#!/bin/bash ENV=${ENV:-"test"} #环境,默认是test PROJ_NAME=${PROJ_NAME:-"no-define"} MULTILINE=${MULTILINE:-"^\d{2}"} # 匹配日志中,两位数字开头的才算是新的一行,比如java报错后,会产生很多行,这个配置就是要求匹配到2位数字开头后,到下一个2位数字开头的行之间的日志都算一条记录。 cat > /etc/filebeat.yaml << EOF filebeat.inputs: - type: log fields_under_root: true fields: topic: logm-${PROJ_NAME} paths: - /logm/*.log #匹配的日志路径 - /logm/*/*.log - /logm/*/*/*.log - /logm/*/*/*/*.log - /logm/*/*/*/*/*.log scan_frequency: 120s max_bytes: 10485760 multiline.pattern: '$MULTILINE' #指定了logm这个路径下的日志,需要做多行匹配,指定了multiline multiline.negate: true multiline.match: after multiline.max_lines: 100 - type: log # 又定义一组日志收集规则,不做多行匹配,落盘一行,就是一行。 fields_under_root: true fields: topic: logu-${PROJ_NAME} paths: - /logu/*.log - /logu/*/*.log - /logu/*/*/*.log - /logu/*/*/*/*.log - /logu/*/*/*/*/*.log - /logu/*/*/*/*/*/*.log output.kafka: hosts: ["10.4.7.11:9092"] topic: k8s-fb-$ENV-%{[topic]} version: 2.0.0 required_acks: 0 max_message_bytes: 10485760 EOF set -xe # If user don't provide any command # Run filebeat if [[ "$1" == "" ]]; then exec filebeat -c /etc/filebeat.yaml else # Else allow the user to run arbitrarily commands like bash exec "$@" fi
# chmod u+x docker-entrypoint.sh
build镜像:
# docker build . -t harbor.od.com/infra/filebeat:v7.5.1
# docker push harbor.od.com/infra/filebeat:v7.5.1
修改test环境的dubbo-demo-consumer的dp.yaml
# vi /data/k8s-yaml/test/dubbo-demo-consumer/dp.yaml
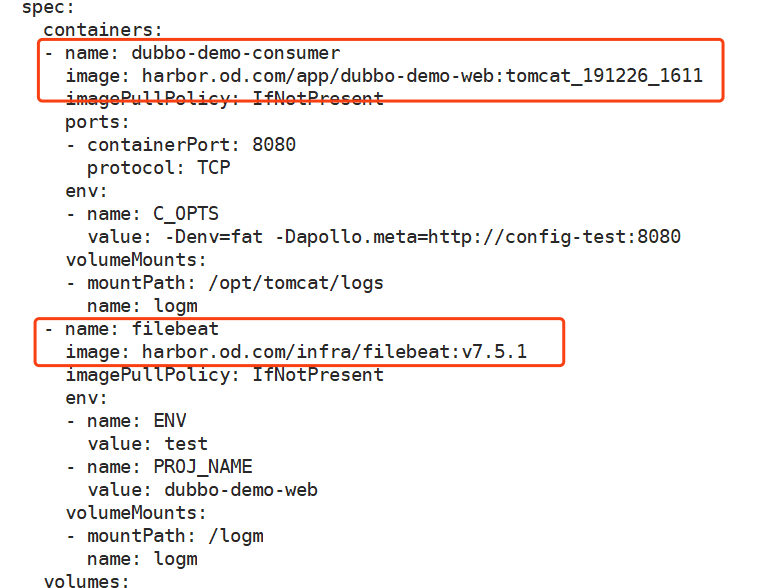
kind: Deployment apiVersion: extensions/v1beta1 metadata: name: dubbo-demo-consumer namespace: test labels: name: dubbo-demo-consumer spec: replicas: 1 selector: matchLabels: name: dubbo-demo-consumer template: metadata: labels: app: dubbo-demo-consumer name: dubbo-demo-consumer spec: containers: - name: dubbo-demo-consumer image: harbor.od.com/app/dubbo-demo-web:tomcat_191226_1611 imagePullPolicy: IfNotPresent ports: - containerPort: 8080 protocol: TCP env: - name: C_OPTS value: -Denv=fat -Dapollo.meta=http://apollo-configservice:8080 volumeMounts: - mountPath: /opt/tomcat/logs name: logm - name: filebeat image: harbor.od.com/infra/filebeat:v7.5.1 imagePullPolicy: IfNotPresent env: - name: ENV value: test - name: PROJ_NAME value: dubbo-demo-web volumeMounts: - mountPath: /logm name: logm volumes: - emptyDir: {} name: logm imagePullSecrets: - name: harbor restartPolicy: Always terminationGracePeriodSeconds: 30 securityContext: runAsUser: 0 schedulerName: default-scheduler strategy: type: RollingUpdate rollingUpdate: maxUnavailable: 1 maxSurge: 1 revisionHistoryLimit: 7 progressDeadlineSeconds: 600
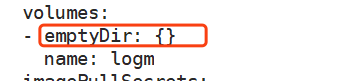
emptyDir是在宿主机上随机创建一个空目录,挂载到容器中的logm目录,随容器运行,随容器销毁。
这里设置了两个变量,传递到docker-entrypoint.sh里
下面这种运行方式,就是边车模式:
接下来看数据卷的挂载,首先声明了一个emptyDir的数据卷logm,
然后将这个logm挂载到了dubbo-demo-consumer的/opt/tomcat/logs目录下,并且在filebeat里,也挂载了这个logm到“/”目录下的logm
这样就解决了日志重复写两遍的问题,我们在filebeat容器里,能直接看到并收集tomcat/logs/logm/下面的日志了。
应用资源配置清单:
# kubectl apply -f http://k8s-yaml.od.com/test/dubbo-demo-consumer/dp.yaml

这里运行了两个容器,以边车模式在运行。
进入filebeat容器:

可以直接查看到tomcat的日志:

这样filebeat就可以直接收集tomcat日志。
边车模式下,两个容器会共享以下系统资源:
NET网络名称空间,UTS命名空间,USER

