【Flink系列二】构建实时计算平台——特别篇,用InfluxDb收集Flink Metrics
Influxdb 快速入门
从Docker启动 Influxdb
docker pull influxdb:LATEST
docker run -d --name influxdb -p 8086:8086 \
-v /opt/work/influxdb:/var/lib/influxdb \
influxdb
进入Influxdb的Client
# docker exec -it influxdb influx
Connected to http://localhost:8086 version 1.8.3
InfluxDB shell version: 1.8.3
>create database flink # 创建Flink数据库
>use flink #为FLink创建RETENTION_POLICY(1)
>CREATE RETENTION POLICY one_hour ON flink DURATION 1h REPLICATION 1 #为FLink创建RETENTION_POLICY(2)
配置Flink
修改FLINK_CONF
metrics.reporter.influxdb.class: org.apache.flink.metrics.influxdb.InfluxdbReporter
metrics.reporter.influxdb.host: <IP>
metrics.reporter.influxdb.port: 8086
metrics.reporter.influxdb.db: flink
metrics.reporter.influxdb.username:
metrics.reporter.influxdb.password:
metrics.reporter.influxdb.retentionPolicy: one_hour
以该配置启动的Flink作业,Flink会自动将指标写入Influxdb
【可选】安装Chronograf可视化界面
docker pull chronograf:LATEST
docker run --name chronograf -d -p 8888:8888 -v /opt/work/chronograf:/var/lib/chronograf chronograf
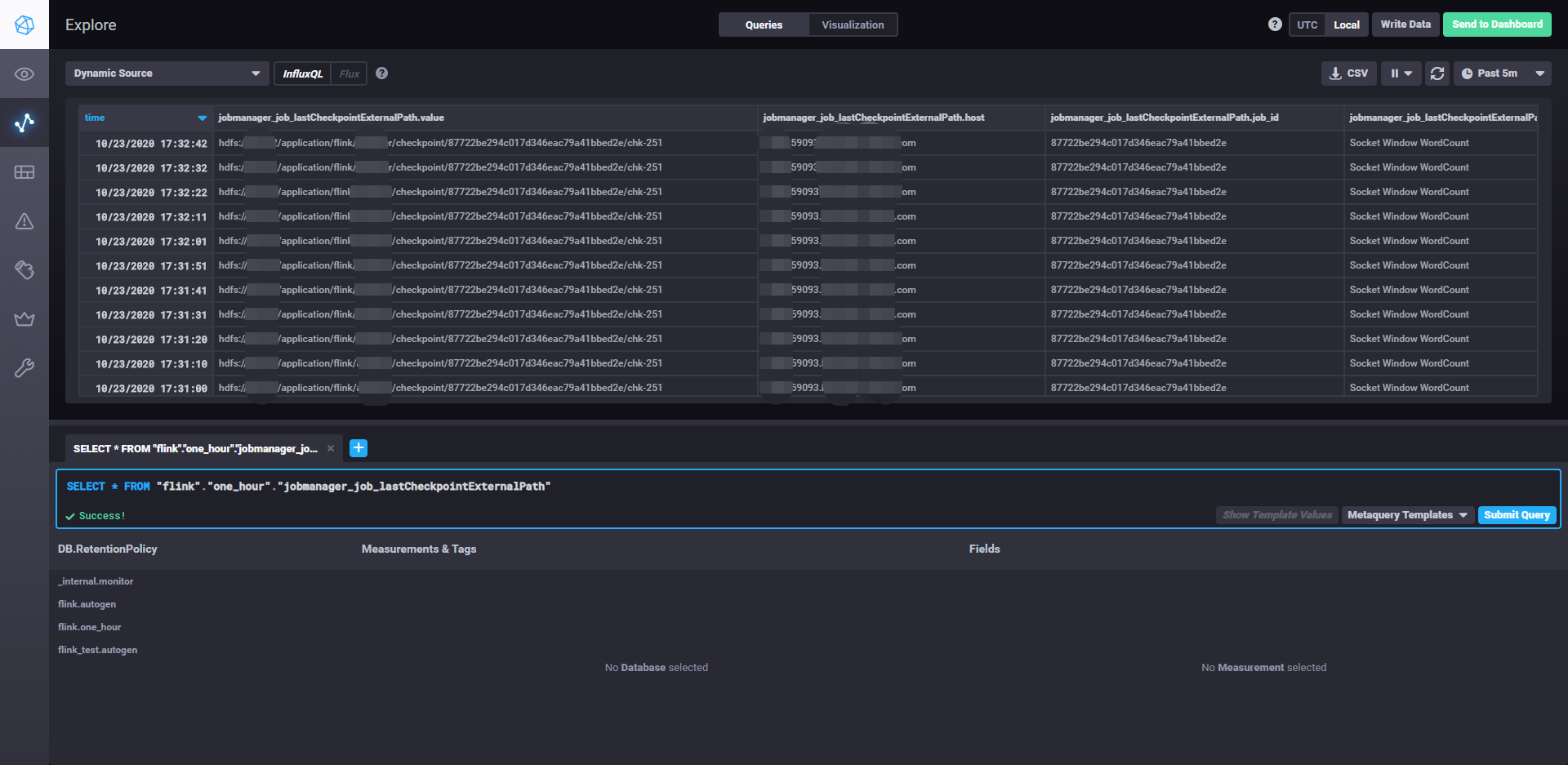
执行SQL可以查到CheckpointExternalPath
SELECT * FROM "flink"."one_hour"."jobmanager_job_lastCheckpointExternalPath"
效果图
优化
监控指标,一般使用Prometheus来做,而根据我的需求和实践来看,Influxdb仅用来接收lastCheckpointExternalPath这个指标。
经过大约半年多的观察,Influxdb 1.8,100个作业的情况下, 内存占用峰值会超过20GB,这个时候容器会自动重启,客户端无法上报。
因此需要对influxdb进行优化。这里记录一种最简单的优化,那就是直接减少指标数量:
package org.apache.flink.metrics.influxdb;
abstract class AbstractReporter<MetricInfo> implements MetricReporter {
protected final Logger log = LoggerFactory.getLogger(getClass());
protected final Map<Gauge<?>, MetricInfo> gauges = new HashMap<>();
protected final Map<Counter, MetricInfo> counters = new HashMap<>();
protected final Map<Histogram, MetricInfo> histograms = new HashMap<>();
protected final Map<Meter, MetricInfo> meters = new HashMap<>();
protected final MetricInfoProvider<MetricInfo> metricInfoProvider;
protected AbstractReporter(MetricInfoProvider<MetricInfo> metricInfoProvider) {
this.metricInfoProvider = metricInfoProvider;
}
@Override
public void notifyOfAddedMetric(Metric metric, String metricName, MetricGroup group) {
if (!metricName.equals("lastCheckpointExternalPath")) {
return;
}
经过验证,Flink 使用此Reporter,仅上报这一个指标。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号