
第一次个人编程作业
一、PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | ||
| Estimate | ·估计这个任务需要多少时间 | 1140 | 1690 |
| Development | 开发 | ||
| Analysis | ·需求分析 (包括学习新技术) | 20 | 50 |
| Design Spec | ·生成设计文档 | 20 | 30 |
| Design Review | ·设计复审 | 10 | 10 |
| Coding Standard | ·代码规范 (为目前的开发制定合适的规范) | 10 | 20 |
| Design | ·具体设计 | 60 | 150 |
| Coding | ·具体编码 | 600 | 1000 |
| Code Review | ·代码复审 | 120 | 100 |
| Test | ·测试(自我测试,修改代码,提交修改) | 180 | 200 |
| Reporting | 报告 | ||
| Test Repor | ·测试报告 | 20 | 30 |
| Size Measurement | ·计算工作量 | 30 | 40 |
| Postmortem & Process Improvement Plan | ·事后总结, 并提出过程改进计划 | 60 | 60 |
| ·合计 | 1140 | 1690 |
二、计算模块接口
计算模块接口的设计与实现过程
- 代码中有一个DFA类,建立词库和寻找敏感词的相关函数都定义在DFA类中;
- 代码中的函数,包括输入函数、输出函数以及定义在类中的敏感词添加函数、汉字转拼音函数、寻找匹配文本函数等等。
- 函数之间的关系:在程序运行之初,先把敏感词库建立完成,接着按行进行文本-敏感词匹配。
- 在中文敏感词检测中,有首字母替换、拼音替换等等,还需要考虑替换的字数等等问题,故用了排列组合相关函数。
- 使用了DFA算法
- 算法的关键部分是敏感词库的建立及其完整性
计算模块接口部分的性能分析
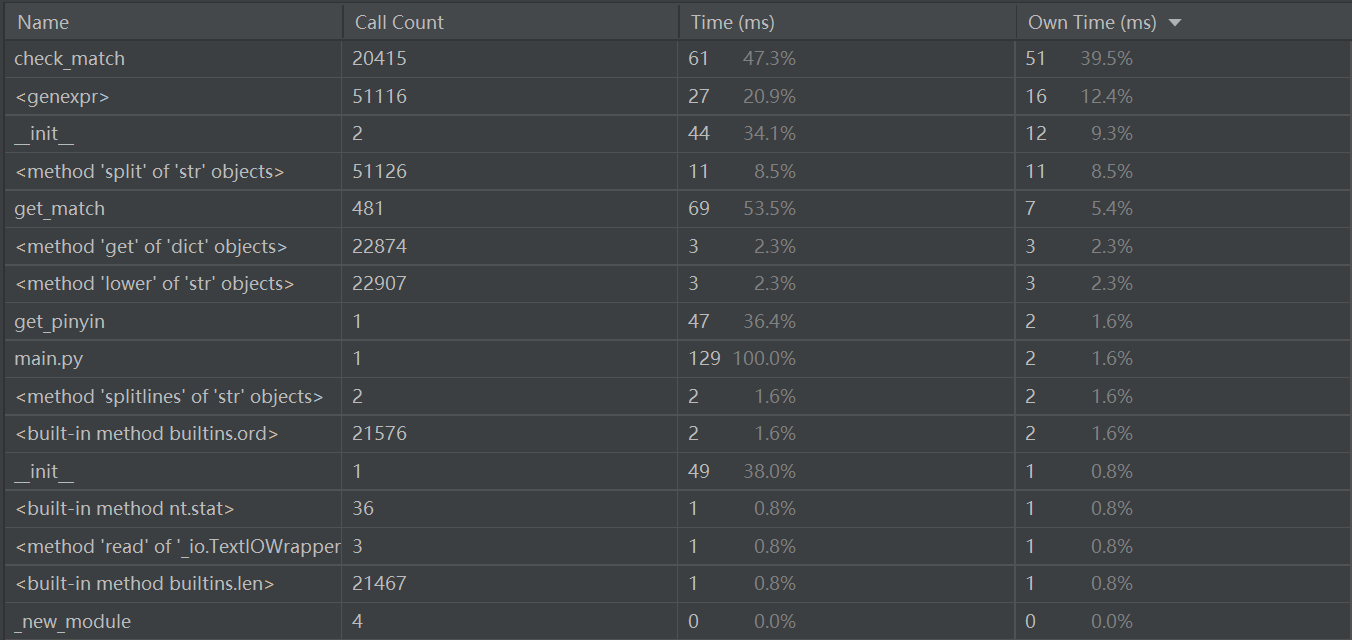
刚开始的时候为了能够尽快出结果,用了大量的循环,导致运行效率低,尽管后面有修改一些地方,但还是不够,导致在新增功能时会有运行超时的情况出现。(比如谐音字检测,该功能添加进去以后虽然能够运行出来,但是在检测示例时要花几分钟,想了很久都没有想到解决办法,就只能先不做了)
消耗最大的函数是check_match函数,用于检测一行中的片段是否有敏感词
def check_match(self, txt, begin_index):
# 检查是否包含敏感词
flag = False
# 敏感词库入口
now_map = self.root
# 匹配文本长度
matched_length = 0
# 原敏感词
ori_word = ''
# 可跳过字符
skip = self.skip
for i in range(begin_index, len(txt)):
# word为当前字符
word = txt[i]
if word in skip:
# 如果word为可跳过字符,且之前已有可匹配文本,则可匹配长度+1,否则跳过
if matched_length > 0:
matched_length += 1
continue
judge = ord(word.lower())
if judge in range(97, 123):
# 字母所对应的可跳过字符比汉字多了一类:数字
skip = self.skip+['0', '1', '2', '3',
'4', '5', '6', '7', '8', '9']
# 判断是否为字母,若是,则不区分大小写,统一转成小写
word = word.lower()
else:
skip = self.skip
now_map = now_map.get(word)
if now_map:
# 找得到对应key值
matched_length += 1
if now_map.get("is_end"):
# 找到一个匹配文本了
flag = True
ori_word += word
else:
break
if matched_length < 2 or not flag:
# 到了行末对应敏感词还没结束或者是找不到对应的敏感词,即无匹配文本
matched_length = 0
ret = dict()
ret['matched_length'] = matched_length
ret['ori_word'] = ori_word
return ret
计算模块部分单元测试展示。
- 部分单元测试
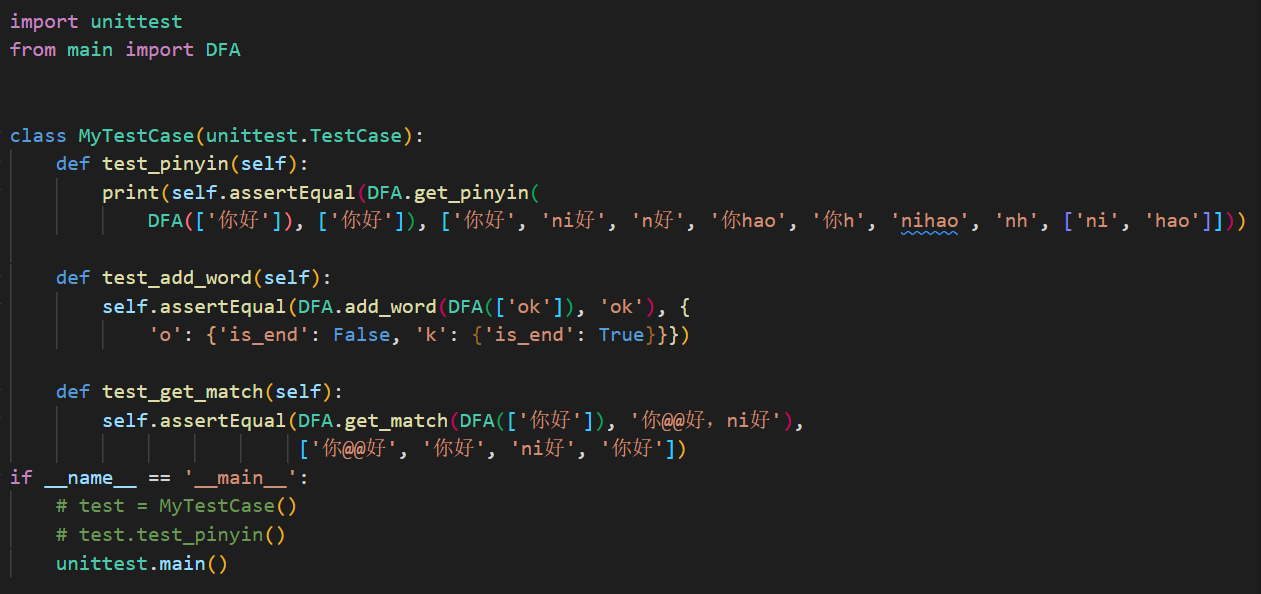
- 单元测试结果

以上测试了DFA类里面的get_pinyin、add_word以及get_match三个函数,因为使用了assertEqual,因此就选择了一些较为简单,能手动得到结果的测试数据。
- get_pinyin函数就是获取汉字拼音替换、首字母替换所有组合并将其加入敏感词库的函数,其返回值为整个敏感词数组。
- add_word函数就是往字典中添加单个词的函数,这个因为中文的过于复杂,会产生循环,故使用了一个英文单词组成的数组作为测试数据,结果返回为添加该词后的整个字典
- get_match函数就是获取单句中匹配文本和对应敏感词的函数,为了不产生循环,故采用检测文本为单字符串的数据,返回值为一个数组,总共有偶数项
计算模块部分异常处理说明

在寻找经拼音替换后的变形敏感词有时候会找不到其原来的敏感词,要添加判断语句,否则程序无法运行
三、心得
这次作业花了很多时间,但是还是做得很糟糕,刚开始的时候连需要学什么都不清楚。做这次作业我先去大致过了一遍python的中文手册,然后通过百度上找敏感词检测相关的算法,最后确定要学习DFA算法,根据网上的一些相似的代码来进行修改以满足基本需求,再继续寻找python的其他一些插件来扩展其他的功能,最后终于算是完成了一半。写代码这部分结束后,还不是真正的结束。一些对代码进行性能分析、单元测试之类的名词是我之前都很少听过的,连要使用什么工具都不是很清楚,这就导致了作业的完成过程更加磕磕绊绊了。通过这次实验,我更加直观地意识到自己在编程方面的不足以及对一些工具使用的不顺畅,觉得写这份作业的过程挺痛苦的吧,还是需要花更多的时间在这门课上。
