吴恩达机器学习笔记61-应用实例:图片文字识别(Application Example: Photo OCR)【完结】
最后一章内容,主要是OCR的实例,很多都是和经验或者实际应用有关;看完了,总之,善始善终,继续加油!!
一、图像识别(店名识别)的步骤:
图像文字识别应用所作的事是,从一张给定的图片中识别文字。这比从一份扫描文档中
识别文字要复杂的多。
为了完成这样的工作,需要采取如下步骤:
1.文字侦测(Text detection)——将图片上的文字与其他环境对象分离开来
2.字符切分(Character segmentation)——将文字分割成一个个单一的字符
3.字符分类(Character classification)——确定每一个字符是什么
可以用任务流程图来表达这个问题,每一项任务可以由一个单独的小队来负责解决:

二、滑动窗口
滑动窗口是一项用来从图像中抽取对象的技术。假使我们需要在一张图片中识别行人,
首先要做的是用许多固定尺寸的图片来训练一个能够准确识别行人的模型。然后我们用之前
训练识别行人的模型时所采用的图片尺寸在我们要进行行人识别的图片上进行剪裁,然后将
剪裁得到的切片交给模型,让模型判断是否为行人,然后在图片上滑动剪裁区域重新进行剪
裁,将新剪裁的切片也交给模型进行判断,如此循环直至将图片全部检测完。
一旦完成后,我们按比例放大剪裁的区域,再以新的尺寸对图片进行剪裁,将新剪裁的
切片按比例缩小至模型所采纳的尺寸,交给模型进行判断,如此循环。

滑动窗口技术也被用于文字识别,首先训练模型能够区分字符与非字符,然后,运用滑
动窗口技术识别字符,一旦完成了字符的识别,我们将识别得出的区域进行一些扩展,然后
将重叠的区域进行合并。接着我们以宽高比作为过滤条件,过滤掉高度比宽度更大的区域
(认为单词的长度通常比高度要大)。下图中绿色的区域是经过这些步骤后被认为是文字的区域,而红色的区域是被忽略的。
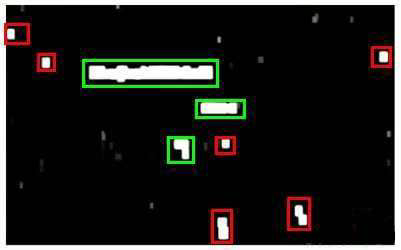
以上便是文字侦测阶段。 下一步是训练一个模型来完成将文字分割成一个个字符的任
务,需要的训练集由单个字符的图片和两个相连字符之间的图片来训练模型。


模型训练完后,我们仍然是使用滑动窗口技术来进行字符识别。
以上便是字符切分阶段。 最后一个阶段是字符分类阶段,利用神经网络、支持向量机
或者逻辑回归算法训练一个分类器即可。
三、获取大量数据和人工合成数据集(这里主要指字母识别中的数据集)的两种方法:
1、没有已有样本:通常有很多字体库,我们可以采集同一个字符的不同种类字体,然后将这些字符加上不同的随机背景。
2、少量已有样本:使用已有的样本,选取一个真实的样本,然后添加将此样本扭曲、旋转(人工变形)的数据,以此来扩大数据集。
注:在决定扩大数据集之前需要考虑的问题:
① 需要先有一个低偏差的分类器,如果没有,可以通过增大特征数或者在神经网络中增大隐藏层单元数来解决
② 首先估计增加样本需要的工作量
有关获得更多数据的几种方法:
1.人工数据合成
2.手动收集、标记数据
3.众包
四、上限分析
回到我们的文字识别应用中,我们的流程图如下:

流程图中每一部分的输出都是下一部分的输入,上限分析中,我们选取一部分,手工提
供100%正确的输出结果,然后看应用的整体效果提升了多少。
总结一下上面的意思,即通过人工干预,使某一个component的准确率人工达到100%,再使用这些数据训练,如果这一component的变化导致整体系统的系统变得很好,那么说明这个component值得花时间优化。
反之,我们将某一component达到100%,系统性能仍没有提升很多,则说明这一component不值得我们花费精力改进。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号