吴恩达机器学习笔记55-异常检测算法的特征选择(Choosing What Features to Use of Anomaly Detection)
对于异常检测算法,使用特征是至关重要的,下面谈谈如何选择特征:
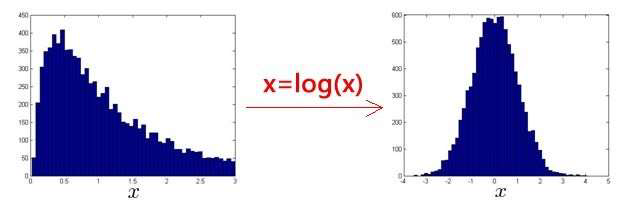
异常检测假设特征符合高斯分布,如果数据的分布不是高斯分布,异常检测算法也能够
工作,但是最好还是将数据转换成高斯分布,例如使用对数函数:𝑥 = 𝑙𝑜𝑔(𝑥 + 𝑐),其中 𝑐
为非负常数; 或者 𝑥 = 𝑥^𝑐,𝑐为 0-1 之间的一个分数,等方法。
(注:在python 中,通常用np.log1p()函数,𝑙𝑜𝑔1𝑝就是 𝑙𝑜𝑔(𝑥 + 1),可以避免
出现负数结果,反向函数就是np.expm1())
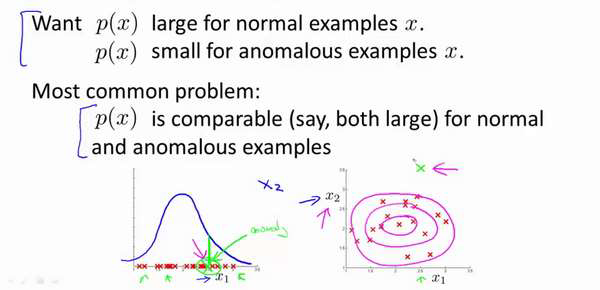
误差分析:
一个常见的问题是一些异常的数据可能也会有较高的𝑝(𝑥)值,因而被算法认为是正常的。
这种情况下误差分析能够帮助我们,我们可以分析那些被算法错误预测为正常的数据,观察
能否找出一些问题。我们可能能从问题中发现我们需要增加一些新的特征,增加这些新特征
后获得的新算法能够帮助我们更好地进行异常检测。
异常检测误差分析:
我们也可以通过将一些相关的特征进行组合,来获得一些新的更好的特征(异常数据
的该特征值异常地大或小),例如,在检测数据中心的计算机状况的例子中,我们可以用CPU
负载与网络通信量的比例作为一个新的特征,如果该值异常地大,便有可能意味着该服务器
是陷入了一些问题中。
总结:
上面介绍了
1.如何选择特征,以及对特征进行一些小小的转换,让数据更
像正态分布,然后再把数据输入异常检测算法;
2.建立特征时,进行的误差分析的方法,来捕捉各种异常的可能。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号