吴恩达机器学习笔记54-开发与评价一个异常检测系统及其与监督学习的对比(Developing and Evaluating an Anomaly Detection System and the Comparison to Supervised Learning)
一、开发与评价一个异常检测系统
异常检测算法是一个非监督学习算法,意味着我们无法根据结果变量 𝑦 的值来告诉我
们数据是否真的是异常的。我们需要另一种方法来帮助检验算法是否有效。当我们开发一个
异常检测系统时,我们从带标记(异常或正常)的数据着手,我们从其中选择一部分正常数
据用于构建训练集,然后用剩下的正常数据和异常数据混合的数据构成交叉检验集和测试
集。
例如:我们有10000 台正常引擎的数据,有20 台异常引擎的数据。 我们这样分配数
据:
6000 台正常引擎的数据作为训练集
2000 台正常引擎和10 台异常引擎的数据作为交叉检验集
2000 台正常引擎和10 台异常引擎的数据作为测试集
具体的评价方法如下:
1. 根据测试集数据,我们估计特征的平均值和方差并构建𝑝(𝑥)函数
2. 对交叉检验集,我们尝试使用不同的𝜀值作为阀值,并预测数据是否异常,根据F1 值
或者查准率与查全率的比例来选择 𝜀
3. 选出 𝜀 后,针对测试集进行预测,计算异常检验系统的𝐹1值,或者查准率与查全率
之比。
二、异常检测与监督学习对比
之前我们构建的异常检测系统也使用了带标记的数据,与监督学习有些相似,下面的对
比有助于选择采用监督学习还是异常检测:
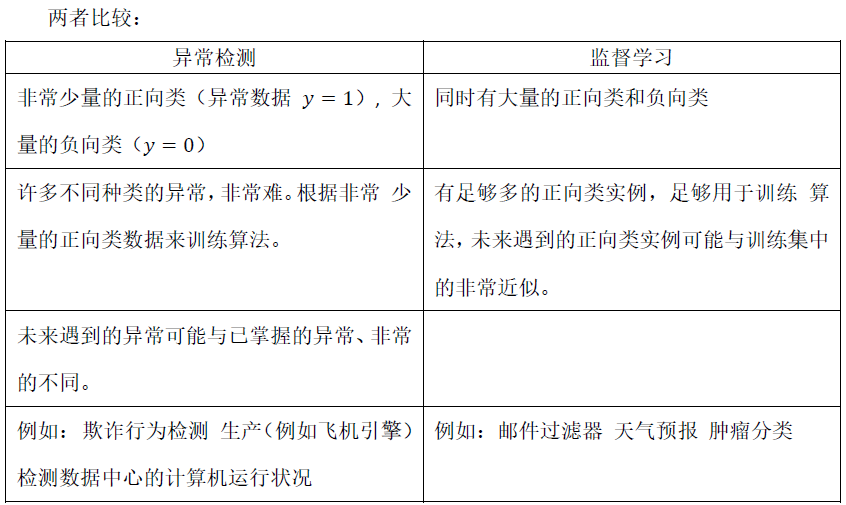
对于很多技术公司可能会遇到这样一些问题,正样本的数量很少,甚至有时候是0,也就是说,出现了太多没见过的不同的异常
类型,那么对于这些问题,通常应该使用的算法就是异常检测算法。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号