吴恩达机器学习笔记52-异常检测的问题动机与高斯分布(Problem Motivation of Anomaly Detection& Gaussian Distribution)
一、问题动机
异常检测(Anomaly detection)问题是机器学习算法的一个常见应用。这种算法的一个有趣之处在于:它虽然主要用于非监督学习问题,但从某些角度看,它又类似于一些监督学习问题。
给定数据集 𝑥(1), 𝑥(2), . . , 𝑥(𝑚),我们假使数据集是正常的,我们希望知道新的数据 𝑥𝑡𝑒𝑠𝑡
是不是异常的,即这个测试数据不属于该组数据的几率如何。我们所构建的模型应该能根据
该测试数据的位置告诉我们其属于一组数据的可能性 𝑝(𝑥)。
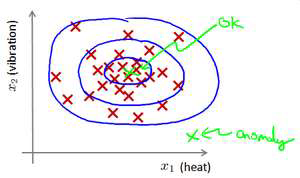
上图中,在蓝色圈内的数据属于该组数据的可能性较高,而越是偏远的数据,其属于该
组数据的可能性就越低。
这种方法称为密度估计,表达如下:
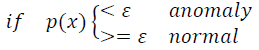
欺诈检测:𝑥(𝑖) = 用户的第 𝑖个活动特征
模型𝑝(𝑥) 为我们其属于一组数据的可能性,通过𝑝(𝑥) < 𝜀检测非正常用户。
异常检测主要用来识别欺骗。例如在线采集而来的有关用户的数据,一个特征向量中可
能会包含如:用户多久登录一次,访问过的页面,在论坛发布的帖子数量,甚至是打字速度
等。尝试根据这些特征构建一个模型,可以用这个模型来识别那些不符合该模式的用户。
二、高斯分布
高斯分布,也称为正态分布。
通常如果我们认为变量 𝑥 符合高斯分布 𝑥 ∼ 𝑁(𝜇, 𝜎2) 则其概率密度函数为:
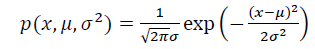
我们可以利用已有的数据来预测总体中的𝜇和𝜎2的计算方
法如下:
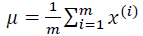
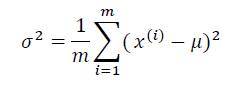
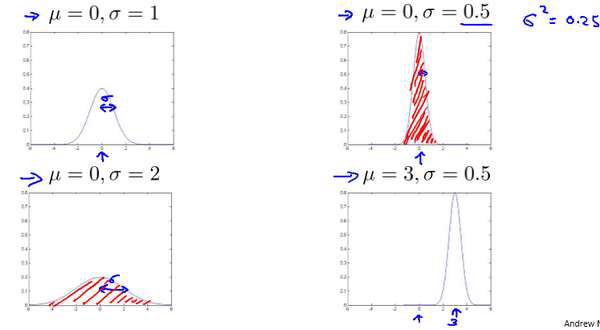
高斯分布样例:
注:机器学习中对于方差我们通常只除以𝑚而非统计学中的(𝑚 − 1)。这里顺便提一下,
在实际使用中,到底是选择使用1/𝑚还是1/(𝑚 − 1)其实区别很小,只要你有一个还算大的
训练集,在机器学习领域大部分人更习惯使用1/𝑚这个版本的公式。这两个版本的公式在理
论特性和数学特性上稍有不同,但是在实际使用中,他们的区别甚小,几乎可以忽略不计。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号