吴恩达机器学习笔记51-初始值重建的压缩表示与选择主成分的数量K(Reconstruction from Compressed Representation & Choosing The Number K Of Principal Components)
一、初始值重建的压缩表示
在PCA算法里我们可能需要把1000 维的数据压缩100 维特征,或具有三维数据压缩到一二维表示。所以,如果这是一个压缩算法,应该能回到这个压缩表示,回到原有的高维数据的一种近似。
所以,给定的𝑧(𝑖),这可能100 维,怎么回到你原来的表示𝑥(𝑖),这可能是1000 维的数组?

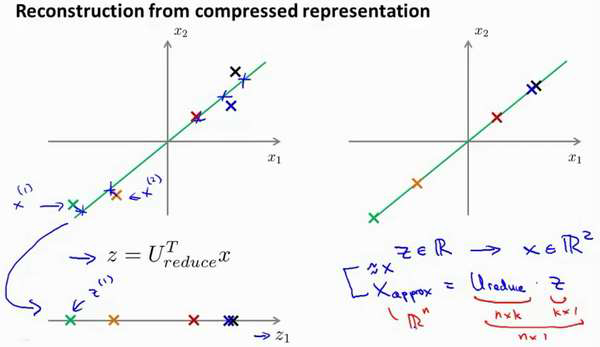
PCA 算法,我们可能有一个这样的样本。如图中样本𝑥(1),𝑥(2)。我们做的是,我们把这
些样本投射到图中这个一维平面。然后现在我们需要只使用一个实数,比如𝑧(1),指定这些
点的位置后他们被投射到这一个三维曲面。给定一个点𝑧(1),我们怎么能回去这个原始的二
维空间呢?𝑥为2 维,z 为1 维,𝑧 = 𝑈𝑟𝑒𝑑𝑢𝑐𝑒𝑇 𝑥,相反的方程为:
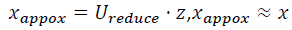
如你所知,这是一个漂亮的与原始数据相当相似。所以,这就是你从低维表示𝑧回到未
压缩的表示。我们得到的数据的一个之间你的原始数据 𝑥,我们也把这个过程称为重建原始
数据。
二、选择主成分的数量K
主成分分析是减少投射的平均均方误差:
训练集的方差为:
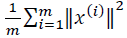
我们希望在平均均方误差与训练集方差的比例尽可能小的情况下选择尽可能小的𝑘值。
如果我们希望这个比例小于1%,就意味着原本数据的偏差有99%都保留下来了,如果
我们选择保留95%的偏差,便能非常显著地降低模型中特征的维度了。
我们可以先令𝑘 = 1,然后进行主要成分分析,获得𝑈𝑟𝑒𝑑𝑢𝑐𝑒和𝑧,然后计算比例是否小于
1%。如果不是的话再令𝑘 = 2,如此类推,直到找到可以使得比例小于1%的最小𝑘 值(原因
是各个特征之间通常情况存在某种相关性)。
还有一些更好的方式来选择𝑘,当我们在Octave 中调用“svd”函数的时候,我们获得三
个参数:[U, S, V] = svd(sigma)。
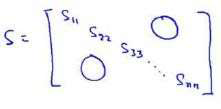
其中的𝑆是一个𝑛 × 𝑛的矩阵,只有对角线上有值,而其它单元都是0,我们可以使用这
个矩阵来计算平均均方误差与训练集方差的比例:
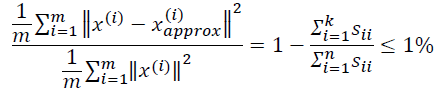
也就是:
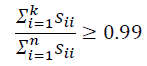
在压缩数据后,我们可以采用如下方法近似地获得原始数据特征:
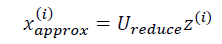

 浙公网安备 33010602011771号
浙公网安备 33010602011771号