吴恩达机器学习笔记48-降维目标:数据压缩与可视化(Motivation of Dimensionality Reduction : Data Compression & Visualization)
目标一:数据压缩
除了聚类,还有第二种类型的无监督学习问题称为降维。有几个不同的的原
因使你可能想要做降维。一是数据压缩,数据压缩不仅允许我们压缩数据,因而使用较少的计算机内存或磁盘空间,而且它也让我们加快我们的学习算法。
我们收集的数据集,有许多,许多特征,我绘制两个在这里。
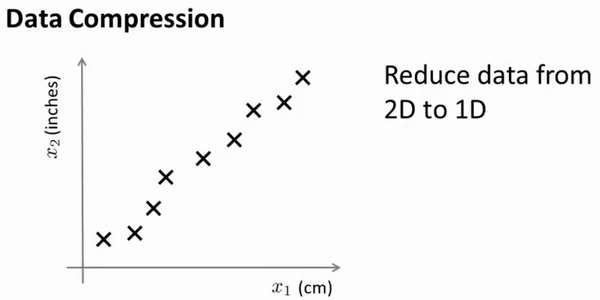
假设我们未知两个的特征:𝑥1:长度:用厘米表示;𝑥2:是用英寸表示同一物体的长度。
所以,这给了我们高度冗余表示,也许不是两个分开的特征𝑥1和𝑥2,这两个基本的长度
度量,也许我们想要做的是减少数据到一维,只有一个数测量这个长度。这个例子似乎有点
做作,这里厘米英寸的例子实际上不是那么不切实际的,两者并没有什么不同。
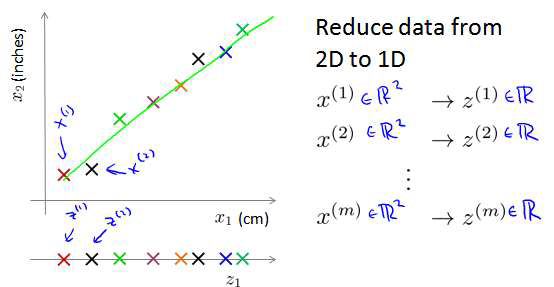
将数据从二维降至一维: 假使我们要采用两种不同的仪器来测量一些东西的尺寸,其
中一个仪器测量结果的单位是英寸,另一个仪器测量的结果是厘米,我们希望将测量的结果
作为我们机器学习的特征。现在的问题的是,两种仪器对同一个东西测量的结果不完全相等
(由于误差、精度等),而将两者都作为特征有些重复,因而,我们希望将这个二维的数据
降至一维。
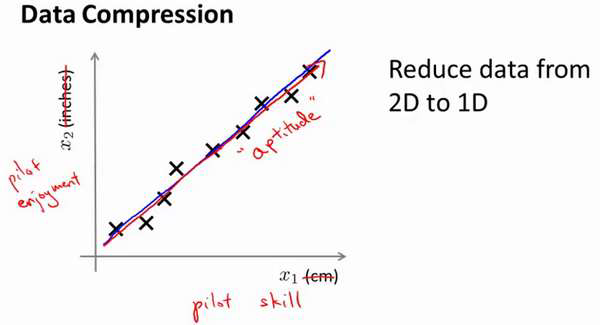
如果你想测量——如果你想做,你知
道,做一个调查或做这些不同飞行员的测试——你可能有一个特征:𝑥1,这也许是他们的技
能(直升机飞行员),也许𝑥2可能是飞行员的爱好。这是表示他们是否喜欢飞行,也许这两
个特征将高度相关。你真正关心的可能是这条红线的方向,不同的特征,决定飞行员的能力。
将数据从三维降至二维: 这个例子中我们要将一个三维的特征向量降至一个二维的特
征向量。过程是与上面类似的,我们将三维向量投射到一个二维的平面上,强迫使得所有的
数据都在同一个平面上,降至二维的特征向量。
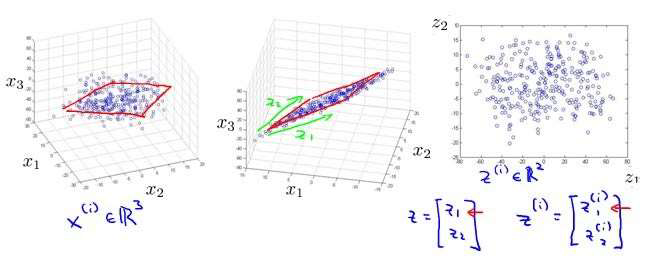
这样的处理过程可以被用于把任何维度的数据降到任何想要的维度,例如将1000 维的
特征降至100 维。
正如我们所看到的,最后,这将使我们能够使我们的一些学习算法运行也较快,我们
会在以后提到它。
目标二:可视化
在许多及其学习问题中,如果我们能将数据可视化,我们便能寻找到一个更好的解决方
案,降维可以帮助我们。
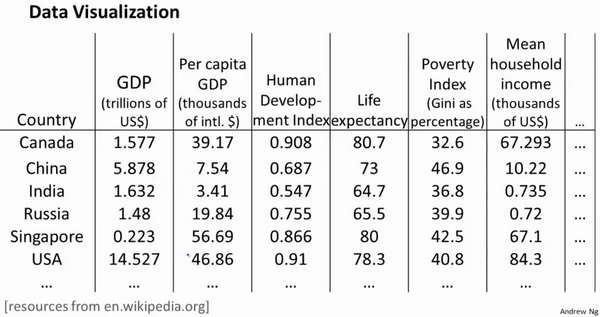
假使我们有有关于许多不同国家的数据,每一个特征向量都有50 个特征(如GDP,人
均GDP,平均寿命等)。如果要将这个50 维的数据可视化是不可能的。使用降维的方法将
其降至2 维,我们便可以将其可视化了。
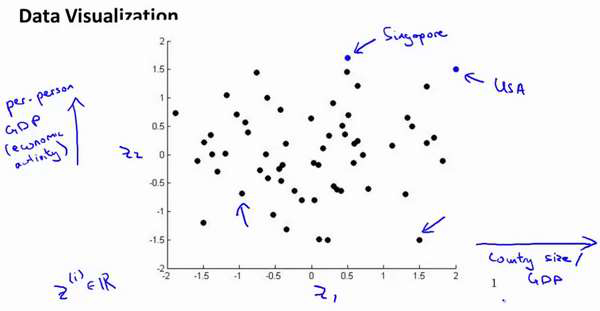
这样做的问题在于,降维的算法只负责减少维数,新产生的特征的意义就必须由我们自
己去发现了。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号