吴恩达机器学习笔记33-评估一个假设输出(Evaluating a Hypothesis Outpute)
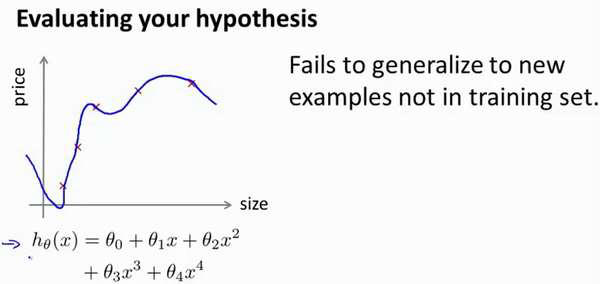
当我们确定学习算法的参数的时候,我们考虑的是选择参量来使训练误差最小化,有人
认为得到一个非常小的训练误差一定是一件好事,但我们已经知道,仅仅是因为这个假设具
有很小的训练误差,并不能说明它就一定是一个好的假设函数。而且我们也学习了过拟合假
设函数的例子,所以这推广到新的训练集上是不适用的。
那么,你该如何判断一个假设函数是过拟合的呢?对于这个简单的例子,我们可以对
假设函数ℎ(𝑥)进行画图,然后观察图形趋势,但对于特征变量不止一个的这种一般情况,还
有像有很多特征变量的问题,想要通过画出假设函数来进行观察,就会变得很难甚至是不可
能实现。
为了检验算法是否过拟合,我们将数据分成训练集和测试集,通常用70%的数据作为
训练集,用剩下30%的数据作为测试集。很重要的一点是训练集和测试集均要含有各种类型
的数据,通常我们要对数据进行“洗牌”,然后再分成训练集和测试集。
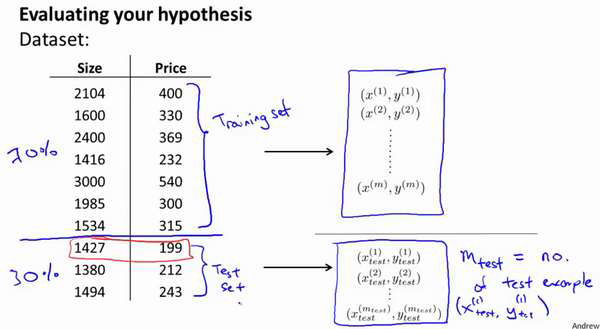
测试集评估在通过训练集让我们的模型学习得出其参数后,对测试集运用该模型,我
们有两种方式计算误差:
1.对于线性回归模型,我们利用测试集数据计算代价函数𝐽
2.对于逻辑回归模型,我们除了可以利用测试数据集来计算代价函数外:
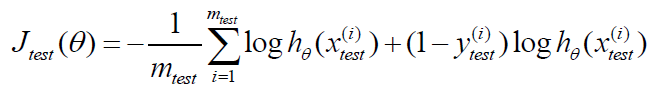
误分类的比率,对于每一个测试集实例,计算:
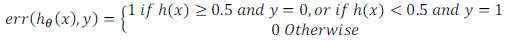
然后对计算结果求平均。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号