吴恩达机器学习笔记20-正则化代价函数
上面的回归问题中如果我们的模型是:
我们可以从之前的事例中看出,正是那些高次项导致了过拟合的产生,所以如果我们能
让这些高次项的系数接近于0 的话,我们就能很好的拟合了。
所以我们要做的就是在一定程度上减小这些参数𝜃 的值,这就是正则化的基本方法。我
们决定要减少𝜃3和𝜃4的大小,我们要做的便是修改代价函数,在其中𝜃3和𝜃4 设置一点惩罚。
这样做的话,我们在尝试最小化代价时也需要将这个惩罚纳入考虑中,并最终导致选择较小
一些的𝜃3和𝜃4。
修改后的代价函数如下:
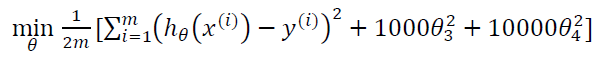
通过这样的代价函数选择出的𝜃3和𝜃4 对预测结果的影响就比之前要小许多。假如我们
有非常多的特征,我们并不知道其中哪些特征我们要惩罚,我们将对所有的特征进行惩罚,
并且让代价函数最优化的软件来选择这些惩罚的程度。这样的结果是得到了一个较为简单的
能防止过拟合问题的假设:
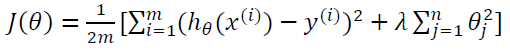
其中𝜆又称为正则化参数(Regularization Parameter)。 注:根据惯例,我们不对𝜃0 进
行惩罚。经过正则化处理的模型与原模型的可能对比如下图所示: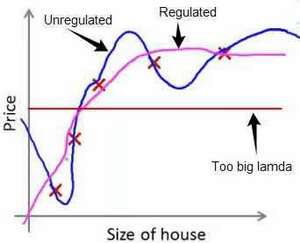
如果选择的正则化参数λ 过大,则会把所有的参数都最小化了,导致模型变成 ℎ𝜃(𝑥) =
𝜃0,也就是上图中红色直线所示的情况,造成欠拟合。
那为什么增加的一项
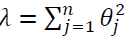
可以使𝜃的值减小呢?
因为如果我们令 𝜆 的值很大的话,为了使Cost Function 尽可能的小,所有的 𝜃 的值
(不包括𝜃0)都会在一定程度上减小。
但若λ 的值太大了,那么𝜃(不包括𝜃0)都会趋近于0,这样我们所得到的只能是一条
平行于𝑥轴的直线。
所以对于正则化,我们要取一个合理的 𝜆 的值,这样才能更好的应用正则化。
回顾一下代价函数,为了使用正则化,让我们把这些概念应用到到线性回归和逻辑回归
中去,那么我们就可以让他们避免过度拟合了。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号