UThash & UTlist基本使用
一、UThash
1.介绍:
在C语言中,语言本身没有提供对hash的支持。uthash则为C语言结构体提供了一种hash table实现方法。uthash是不是库,它只是一个头文件:uthash.h。所有你需要做的只是把这个头文件(源码)拷贝到工程里,并且:#include “uthash.h”。因为uthash只是一个头文件,所以使用它并不需要进行任何链接库的操作。uthash的目标是小型和高效,总共大概1000行C代码。由于全部采用了宏定义来实现,代码会在编译阶段由编译器自动进行嵌入处理。如果选用的hash函数适合对你提供的key进行计算,uthash将是很快的。
uthash支持对hash table中元素进行下列操作:
-
添加/替换 (add/replace)
-
查找(find)
-
删除 (delete)
-
-
迭代 (iterate)
-
排序(sort)
2.使用示例:
测试代码——只需要在任意结构体中定义UT_hash_handle变量,即可使用UThash。下面代码中主要使用了UThash的新增、迭代和查找功能,验证了多线程情况下UThash是分离的,即线程自己创建的hash table在线程间不是共用的(这一点在uthash.h源码中也能看出来,每创建一个uthash,就会新申请一块内存)。另外,使用时必须将哈希表的头指针初始化为NULL。
uthash_test.h
#ifndef UT_HASH_TEST #define UT_HASH_TEST #include "uthash.h" #include <pthread.h> struct uthash_table { int id; char sock[10]; UT_hash_handle hh_id; UT_hash_handle hh_sock; }; struct uthash_test { int tmp_id; pthread_t thread_id; struct uthash_table *uthash_by_id; struct uthash_table *uthash_by_sock; }; struct uthash_test *uthash_init(int id); void *write_loop(void *obj); #endif
uthash_test.c
#include "uthash_test.h" #include <pthread.h> #include <stdio.h> #include <string.h> #include <stddef.h> int main() { struct uthash_test *utests[2]; memset(utests, 0, sizeof(utests)); struct uthash_test *ut = (struct uthash_test *)malloc(sizeof(struct uthash_test)); memset(ut, 0, sizeof(struct uthash_test)); for (int i = 0; i < 2; i++) { ut = uthash_init(i); if(!ut) { return 1; } utests[i] = ut; } // for循环打印两个线程的uthash内容 struct uthash_table *cc, *cc_tmp; int tmp_i = 1; for (int i = 0; i < 2; i++) { printf("i = %d\n", i); HASH_ITER(hh_id, utests[i]->uthash_by_id, cc, cc_tmp){ printf("%d\n", cc->id); printf("%s\n", cc->sock); } // 与上段代码作用相同 // HASH_ITER(hh_sock, utests[i]->uthash_by_sock, cc, cc_tmp){ // printf("%d\n", cc->id); // printf("%s\n", cc->sock); // } /* 在两个hashtable中寻找 key为 (id = 0) 的item,如果一个返回地址为空,一个不为空,则证明两个线程的hashtable是独立的! */ HASH_FIND(hh_id, utests[i]->uthash_by_id, &tmp_i, sizeof(int), cc); if (cc) { printf("找到了!\n"); } else { printf("没找到!\n"); } puts("\n********************************\n"); } free(ut); printf("hello wolrd!"); return 0; } struct uthash_test *uthash_init(int id) { struct uthash_test *utest = (struct uthash_test *)malloc(sizeof(struct uthash_test)); memset(utest, 0, sizeof(struct uthash_test)); utest->tmp_id = id; // uthash必须初始化为NULL utest->uthash_by_id = NULL; utest->uthash_by_sock = NULL; if(!pthread_create(&utest->thread_id, NULL, write_loop, utest)) { // 主线程等待子线程结束 pthread_join(utest->thread_id, NULL); } else { printf("worker:%d创建线程失败!", utest->tmp_id); return NULL; } return utest; } void *write_loop(void *obj) { struct uthash_test *utest = (struct uthash_test *)obj; struct uthash_table *utable = (struct uthash_table *)malloc(sizeof(struct uthash_table)); memset(utable, 0, sizeof(struct uthash_table)); utable->id = utest->tmp_id; char sock_name[10] = "sock-"; char sock_id[10]; sprintf(sock_id, "%d", utest->tmp_id); strcat(sock_name, sock_id); strcpy(utable->sock, sock_name); HASH_ADD(hh_id, utest->uthash_by_id, id, sizeof(utable->id), utable); HASH_ADD(hh_sock, utest->uthash_by_sock, sock, strlen(utable->sock), utable); }
运行结果:
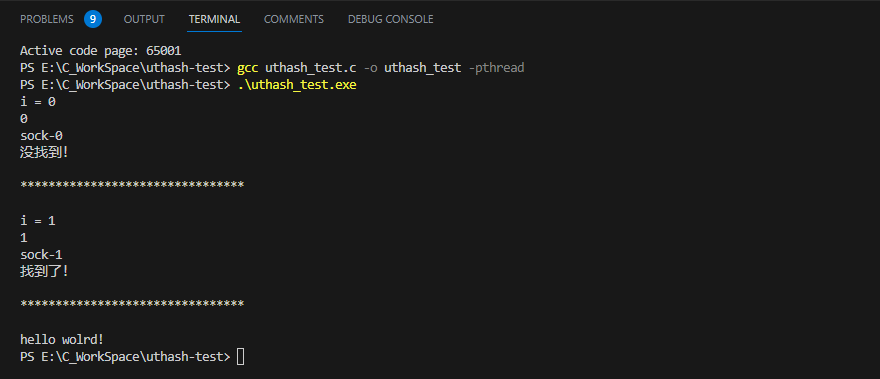
在数据结构中定义UT_hash_handle变量,使得数据结构成为hash table。可以定义多个UT_hash_handle,但当只定义一个时,建议命名为'hh',因为这样可以使用UThash提供的便捷宏。
3.宏定义参考:
便捷宏定义和一般宏定义功能相同,只是参数更少。 二者的最大的区别在于:便捷宏仅在UT_hash_handle变量名为'hh',且key的类型为 int或char[ ] 时使用;如果不是'hh',或者key的类型不是 int或char[ ] 就得用一般宏。
3.1 便捷宏定义
| macro | arguments |
|---|---|
HASH_ADD_INT |
(head, keyfield_name, item_ptr) |
HASH_REPLACE_INT |
(head, keyfiled_name, item_ptr,replaced_item_ptr) |
HASH_FIND_INT |
(head, key_ptr, item_ptr) |
HASH_ADD_STR |
(head, keyfield_name, item_ptr) |
HASH_REPLACE_STR |
(head,keyfield_name, item_ptr, replaced_item_ptr) |
HASH_FIND_STR |
(head, key_ptr, item_ptr) |
HASH_ADD_PTR |
(head, keyfield_name, item_ptr) |
HASH_REPLACE_PTR |
(head, keyfield_name, item_ptr, replaced_item_ptr) |
HASH_FIND_PTR |
(head, key_ptr, item_ptr) |
HASH_DEL |
(head, item_ptr) |
HASH_SORT |
(head, cmp) |
HASH_COUNT |
(head) |
3.2 一般宏定义
| macro | arguments |
|---|---|
HASH_ADD |
(hh_name, head, keyfield_name, key_len, item_ptr) |
HASH_ADD_BYHASHVALUE |
(hh_name, head, keyfield_name, key_len, key_hash, item_ptr) |
HASH_ADD_KEYPTR |
(hh_name, head, key_ptr, key_len, item_ptr) |
HASH_ADD_KEYPTR_BYHASHVALUE |
(hh_name, head, key_ptr, key_len, key_hash, item_ptr) |
HASH_ADD_INORDER |
(hh_name, head, keyfield_name, key_len, item_ptr, cmp) |
HASH_ADD_BYHASHVALUE_INORDER |
(hh_name, head, keyfield_name, key_len, key_hash, item_ptr, cmp) |
HASH_ADD_KEYPTR_INORDER |
(hh_name, head, key_ptr, key_len, item_ptr, cmp) |
HASH_ADD_KEYPTR_BYHASHVALUE_INORDER |
(hh_name, head, key_ptr, key_len, key_hash, item_ptr, cmp) |
HASH_REPLACE |
(hh_name, head, keyfield_name, key_len, item_ptr, replaced_item_ptr) |
HASH_REPLACE_BYHASHVALUE |
(hh_name, head, keyfield_name, key_len, key_hash, item_ptr, replaced_item_ptr) |
HASH_REPLACE_INORDER |
(hh_name, head, keyfield_name, key_len, item_ptr, replaced_item_ptr, cmp) |
HASH_REPLACE_BYHASHVALUE_INORDER |
(hh_name, head, keyfield_name, key_len, key_hash, item_ptr, replaced_item_ptr, cmp) |
HASH_FIND |
(hh_name, head, key_ptr, key_len, item_ptr) |
HASH_FIND_BYHASHVALUE |
(hh_name, head, key_ptr, key_len, key_hash, item_ptr) |
HASH_DELETE |
(hh_name, head, item_ptr) |
HASH_VALUE |
(key_ptr, key_len, key_hash) |
HASH_SRT |
(hh_name, head, cmp) |
HASH_CNT |
(hh_name, head) |
HASH_CLEAR |
(hh_name, head) |
HASH_SELECT |
(dst_hh_name, dst_head, src_hh_name, src_head, condition) |
HASH_ITER |
(hh_name, head, item_ptr, tmp_item_ptr) |
HASH_OVERHEAD |
(hh_name, head) |
HASH_ADD_KEYPTR是用于结构体里包含指向key的指针,而不是指针本身是key时使用。
参数说明
| 参数名 | 参数含义 |
|---|---|
| hh_name | 结构体中UT_hash_handle 成员名称. 使用快捷宏,需为hh. |
| head | 指向hash表头的指针. |
| keyfield_name | key成员名称. (复合key情况下,是复合key中第一个成员名称). |
| key_len | key长度(字节数).比如整型就是sizeof(int), 字符串类型strlen(key). |
| key_ptr | 对于HASH_FIND, 这是指向需要查找元素的key (因为这是个zhie指针,所以你不能使用字面量 ). 对于 HASH_ADD_KEYPTR, 这是要添加元素key的地址. |
| key_hash | key的hash值. 这是 ..._BYHASHVALUE 宏的输入,HASH_VALUE的输出. |
| item_ptr | 指针,指向要添加,删除,替换,查找的元素,在迭代过程中指向当前元素. HASH_ADD, HASH_DELETE,和 HASH_REPLACE的输入, HASH_FIND 和 HASH_ITER的输出. (当使用 HASH_ITER进行迭代时, tmp_item_ptr是和``item_ptr同类型的另外一个指针,供内部使用). |
| replaced_item_ptr | 在HASH_REPLACE 中使用,是输出参数,指向被替换的那个元素 (如果没有元素被替换,将设置为NULL). |
| cmp | 指向比较函数,函数对两个输入参数进行比较,返回比较结果(就像strcmp). |
| condition | 指向条件函数,函数接收一个参数(void*类型,需要强制转换),如果条件满足返回非0值,元素将会被选中并添加到目标hash表中. |
二、UTlist
1.介绍:
utlist.h中包含了一组用于C结构体的通用链表宏。使用起来非常简单,只需要将utlist.h(源码)拷贝到你的项目,并 #include "utlist.h"即可。 utlist.h宏提供了基本的链表操作:添加、删除、排序、遍历、合并。
1.1 链表类型
utlist.h支持下面三种类型的链表:
单向链表 双向链表 环形双向链表
1.4 使用效率
头部添加:对所有的链表类型都是常量; 尾部添加:单向链表O(n);双向链表是常量; 删除:单向链表O(n);双向链表是常量; 排序:对所有链表类型都是O(n log(n)); 有序链表遍历:对所有链表类型都是O(n); 无序链表遍历:对所有链表类型都是O(n);
2.使用示例:
只需要在结构体中定义一个next指针即可使用单向链表,再定义一个prev即可使用双向链表。 链表头是一个简单的指针,可以任意命名,但定义时必须初始化为NULL。
utlist_test.h
#ifndef UT_LIST_TEST #define UT_LIST_TEST #include "utlist.h" typedef struct myList{ int data; struct myList *prev; struct myList *next; } ml; #endif
utlist_test.c
#include "utlist_test.h" #include <stdio.h> #include <string.h> #include <stddef.h> #include <stdlib.h> int main() { ml *my_list = NULL; ml *tmp = (ml *)malloc(sizeof(ml)); memset(tmp, 0, sizeof(ml)); tmp->data = 1; DL_APPEND(my_list, tmp); ml *tmp_1 = (ml *)malloc(sizeof(ml)); memset(tmp_1, 0, sizeof(ml)); tmp_1->data = 2; DL_APPEND(my_list, tmp_1); int my_count = 0; DL_COUNT(my_list, tmp, my_count); printf("my_count: %d\n", my_count); // -------------------------------------------- ml *your_list = NULL; ml *tmp_2 = (ml *)malloc(sizeof(ml)); memset(tmp_2, 0, sizeof(ml)); tmp_2->data = 3; DL_APPEND(your_list, tmp_2); ml *tmp_3 = (ml *)malloc(sizeof(ml)); memset(tmp_3, 0, sizeof(ml)); tmp_3->data = 4; DL_APPEND(your_list, tmp_3); DL_CONCAT(my_list, your_list); my_count = 0; DL_COUNT(my_list, tmp, my_count); printf("my_count: %d\n", my_count); DL_FOREACH_SAFE(my_list, tmp, tmp_2) { printf("%d\n", tmp->data); } printf("Hello World!\n"); return 0; }
运行结果:
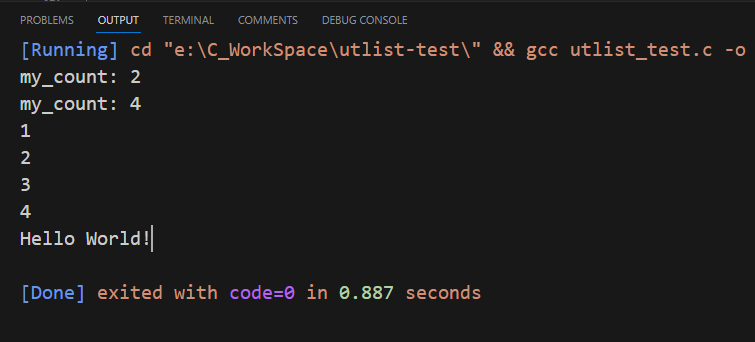
3.宏定义参考:
当结构体中定义的prev和next名字是标准的prev与next时,可以使用便捷宏,否则使用一般宏 。
3.1 便捷宏定义
| 单向链表 | 双向链表 | 双向循环链表 |
|---|---|---|
| LL_PREPEND(head,add); | DL_PREPEND(head,add); | CDL_PREPEND(head,add); |
| LL_PREPEND_ELEM(head,ref,add); | DL_PREPEND_ELEM(head,ref,add); | CDL_PREPEND_ELEM(head,ref,add); |
| LL_APPEND_ELEM(head,ref,add); | DL_APPEND_ELEM(head,ref,add); | CDL_APPEND_ELEM(head,ref,add); |
| LL_REPLACE_ELEM(head,del,add); | DL_REPLACE_ELEM(head,del,add); | CDL_REPLACE_ELEM(head,del,add); |
| LL_APPEND(head,add); | DL_APPEND(head,add); | CDL_APPEND(head,add); |
| LL_INSERT_INORDER(head,add,cmp); | DL_INSERT_INORDER(head,add,cmp); | CDL_INSERT_INORDER(head,add,cmp); |
| LL_CONCAT(head1,head2); | DL_CONCAT(head1,head2); | |
| LL_DELETE(head,del); | DL_DELETE(head,del); | CDL_DELETE(head,del); |
| LL_SORT(head,cmp); | DL_SORT(head,cmp); | CDL_SORT(head,cmp); |
| LL_FOREACH(head,elt) {…} | DL_FOREACH(head,elt) {…} | CDL_FOREACH(head,elt) {…} |
| LL_FOREACH_SAFE(head,elt,tmp) {…} | DL_FOREACH_SAFE(head,elt,tmp) {…} | CDL_FOREACH_SAFE(head,elt,tmp1,tmp2) {…} |
| LL_SEARCH_SCALAR(head,elt,mbr,val); | DL_SEARCH_SCALAR(head,elt,mbr,val); | CDL_SEARCH_SCALAR(head,elt,mbr,val); |
| LL_SEARCH(head,elt,like,cmp); | DL_SEARCH(head,elt,like,cmp); | CDL_SEARCH(head,elt,like,cmp); |
| LL_LOWER_BOUND(head,elt,like,cmp); | DL_LOWER_BOUND(head,elt,like,cmp); | CDL_LOWER_BOUND(head,elt,like,cmp); |
| LL_COUNT(head,elt,count); | DL_COUNT(head,elt,count); | CDL_COUNT(head,elt,count); |
3.1.1 宏使用说明
-
PREPEND是向链表头插入一个元素,然后修改链表头指向刚插入的元素;
-
APPEND是向链表尾插入一个元素,新插入的元素变成链表的尾;
-
CONCAT用于连接两个链表,将第二个链表连接到第一个链表尾;
-
若想在任意元素位置(而不是链表头部)前面进行插入,请使用PREPEND_ELEM宏家族;
-
若想在任意元素位置(而不是列表尾部)后面进行追加,请使用APPEND_ELEM宏家族;
-
若想用另一个元素替换任意表元素,请使用REPLACE_ELEM宏家族;
-
SORT排序操作从不会移动元素在内存的位置,而仅仅是调整元素的prev和next指针。因此也可能会修改链表头指向另一个链表中的元素;
-
FOREACH是一个简单的遍历链表的方法,可以通过prev和next来遍历链表,不过如果在遍历时删除元素,建议你使用FOREACH_SAFE;
-
SEARCH是在搜索特定元素的快捷方法(相对FOREACH而言,并不是更快,而是更好用而已)。
-
SEARCH_SCALAR版本使用简单的比较函数来搜索;SEARCH则使用用户指定的cmp函数进行比较;
-
LOWER_BOUND从链表中寻找第一个不大于like的元素,比较方法使用用户提供的cmp函数;
-
COUNT操作遍历链表,并将计数统计到count中。
3.1.2 参数说明
| 参数名 | 参数含义 |
|---|---|
| head | 链表头(指向链表元素结构的指针). |
| add | 指向要添加到链表中的元素的指针. |
| del | 指向要从链表中替换或删除的链表元素的指针. |
| elt | 在迭代宏的情况下,将连续被赋值为每个链表元素的指针(参见示例);或者搜索宏的输出指针. |
| ref | 前置和追加操作的引用元素,该操作将在之前或之后进行添加。如果ref是一个值为NULL的指针,则新元素将被追加到PREPEND_ELEM()操作的列表中,并前置到APPEND_ELEM()操作的列表中。ref必须是指针变量的名称,不能写成NULL,使用PREPEND()和_APPEND()宏族代替。 |
| like | 与elt类型相同的元素指针,搜索宏将为其寻找匹配项(如果找到,则将匹配项存储在elt中). 是否匹配由给定的cmp函数确定. |
| cmp | 指向一个接受两个参数的比较函数的指针——这两个参数是指向两个要进行比较的元素的指针。比较函数必须返回一个int值,该值为负、零或正,分别代表第一项应该排在第二项之前、等于第二项还是之后。(换句话说,与strcmp使用的约定相同)。注意,在Visual Studio 2008中,您可能需要将这两个参数声明为void *,然后将它们转换回实际类型。 |
| tmp | 与elt相同类型的指针,在内部使用,不需要初始化. |
| mbr | 在SEARCH_SCALAR宏中,elt结构中将测试(使用==)与值val是否相等的成员的名称. |
| val | 在SEARCH_SCALAR宏中,指定正在搜索的元素的(结构成员字段)的值. |
| count | 整型,表示链表长度. |
3.2 一般宏定义
| 单向链表 | 双向链表 | 双向循环链表 |
|---|---|---|
| LL_PREPEND2(head,add,next); | DL_PREPEND2(head,add,prev,next); | CDL_PREPEND2(head,add,prev,next); |
| LL_PREPEND_ELEM2(head,ref,add,next); | DL_PREPEND_ELEM2(head,ref,add,prev,next); | CDL_PREPEND_ELEM2(head,ref,add,prev,next); |
| LL_APPEND_ELEM2(head,ref,add,next); | DL_APPEND_ELEM2(head,ref,add,prev,next); | CDL_APPEND_ELEM2(head,ref,add,prev,next); |
| LL_REPLACE_ELEM2(head,del,add,next); | DL_REPLACE_ELEM2(head,del,add,prev,next); | CDL_REPLACE_ELEM2(head,del,add,prev,next); |
| LL_APPEND2(head,add,next); | DL_APPEND2(head,add,prev,next); | CDL_APPEND2(head,add,prev,next); |
| LL_INSERT_INORDER2(head,add,cmp,next); | DL_INSERT_INORDER2(head,add,cmp,prev,next); | CDL_INSERT_INORDER2(head,add,cmp,prev,next); |
| LL_CONCAT2(head1,head2,next); | DL_CONCAT2(head1,head2,prev,next); | |
| LL_DELETE2(head,del,next); | DL_DELETE2(head,del,prev,next); | CDL_DELETE2(head,del,prev,next); |
| LL_SORT2(head,cmp,next); | DL_SORT2(head,cmp,prev,next); | CDL_SORT2(head,cmp,prev,next); |
| LL_FOREACH2(head,elt,next) {…} | DL_FOREACH2(head,elt,next) {…} | CDL_FOREACH2(head,elt,next) {…} |
| LL_FOREACH_SAFE2(head,elt,tmp,next) {…} | DL_FOREACH_SAFE2(head,elt,tmp,next) {…} | CDL_FOREACH_SAFE2(head,elt,tmp1,tmp2,prev,next) {…} |
| LL_SEARCH_SCALAR2(head,elt,mbr,val,next); | DL_SEARCH_SCALAR2(head,elt,mbr,val,next); | CDL_SEARCH_SCALAR2(head,elt,mbr,val,next); |
| LL_SEARCH2(head,elt,like,cmp,next); | DL_SEARCH2(head,elt,like,cmp,next); | CDL_SEARCH2(head,elt,like,cmp,next); |
| LL_LOWER_BOUND2(head,elt,like,cmp,next); | DL_LOWER_BOUND2(head,elt,like,cmp,next); | CDL_LOWER_BOUND2(head,elt,like,cmp,next); |
| LL_COUNT2(head,elt,count,next); | DL_COUNT2(head,elt,count,next); | CDL_COUNT2(head,elt,count,next); |

 浙公网安备 33010602011771号
浙公网安备 33010602011771号