
第一次个人编程作业
| 这个作业属于哪个课程 | 计科22级12班 |
|---|---|
| 这个作业的要求在哪里 | 个人项目 |
| 这个作业的目标 | 设计一个论文查重算法,利用PSP进行项目管理,学会版本控制,异常处理,单元测试,性能分析 |
Github地址
PSP表格
| PSP2.1 | Personal Software Process Stages |
预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 40 | 30 |
| · Estimate | · 估计这个任务需要多少时间 | 20 | 20 |
| Development | 开发 | 480 | 600 |
| · Analysis | · 需求分析 (包括学习新技术) | 150 | 150 |
| · Design Spec | · 生成设计文档 | 90 | 60 |
| · Design Review | · 设计复审 | 30 | 30 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 30 | 30 |
| · Design | · 具体设计 | 60 | 90 |
| · Coding | · 具体编码 | 180 | 210 |
| · Code Review | · 代码复审 | 30 | 30 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 60 | 120 |
| Reporting | 报告 | 30 | 60 |
| ·Test Report | · 测试报告 | 30 | 30 |
| · Size Measurement | · 计算工作量 | 30 | 20 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 30 | 30 |
| · 合计 | 1290 | 1510 |
计算模块接口的设计与实现过程
函数的设计
SimHash 类:包含了用于计算 SimHash 值的方法。SimHash 类中包含了以下函数:
simHash(self, content):用于计算输入内容的 SimHash 值。
string_hash(self, source):用于将输入的字符串转换为哈希值。
getDistance(self, hashstr1, hashstr2):用于计算两个哈希字符串之间的汉明距离。
其他函数:
read_file(file_path): 用于读取文本文件中的内容。
calculate_similarity(original_text, plagiarized_text):用于计算文本相似度。
write_file(output_file, similarity):用于将相似度写入指定的输出文件中。
算法的关键
SimHash算法
simhash包含分词、hash、加权、合并、降维五大步骤
-
分词:首先对输入的文本进行分词,将文本分割成一个个词语或者短语。
关键点:使用分词工具jieba来进行分词操作,快速高效地对中文文本进行分词处理,并且在准确性上表现优秀。 -
哈希:将分词得到的词语或短语转换为哈希值,通常是将词语或短语进行哈希计算得到一个固定长度的二进制字符串。
关键点:哈希算法的选择和实现对SimHash算法的效果有很大影响,需要保证哈希算法的均匀性和唯一性,以确保不同词语的哈希值具有一定的区分度。 -
加权:根据词语的重要性(如TF-IDF权重)对哈希值进行加权,通常是根据词语的权重值,将哈希值进行加权处理。
关键点:加权操作可以提高关键词的重要性,使得SimHash值更能够反映文本的关键信息。合理的加权策略可以提高SimHash算法的准确性。 -
合并:将各个词语或短语的加权哈希值进行合并,通常是将各个哈希值按位相加或相减得到最终的SimHash值。
关键点:将不同词语的哈希值正确地融合在一起,同时保留各个词语的权重信息,以确保SimHash值能够准确地反映文本的特征。 -
降维:对得到的SimHash值进行降维处理,通常是将SimHash值进行降维压缩,得到一个固定长度的SimHash签名。
关键点:降维操作可以减少SimHash值的长度,降低存储和计算的复杂度,同时保留足够的信息以确保SimHash签名的唯一性和区分度。
独到之处
- 多线程并行处理:在优化部分中,引入了多线程并行处理的方法,通过并行处理文本分词和关键词提取过程,提高了处理速度和效率。
- 文本预处理:在计算SimHash值之前,对文本进行了清洗和分词处理,去除了标点符号和停用词,只保留关键词进行计算。
- 汉明距离计算:通过计算SimHash值之间的汉明距离来衡量文本之间的相似度,这是一种简单而有效的方法,能够快速判断文本的相似程度。
计算模块接口部分的性能改进
优化前的性能分析


分析
最耗时的函数是jieba.cut和jieba.analyse.extract_tags这两个函数,分别占据了大部分的运行时间。这是因为在计算文本相似度时,需要对文本进行分词和提取关键词,这两个过程是比较耗时的。
改进思路
使用多线程并行处理文本分词和关键词提取的过程,从而加快处理速度。
具体实现
with concurrent.futures.ThreadPoolExecutor() as executor:
future = executor.submit(jieba.analyse.extract_tags, "|".join(seg), topK=10, withWeight=True)
keyWords = future.result()
优化后的性能分析


单元测试展示
部分单元测试代码
import unittest
from main import SimHash, read_file, calculate_similarity, write_file, main
class TestSimHash(unittest.TestCase):
def setUp(self):
# 创建 SimHash 实例
self.simhash_instance = SimHash()
def test_empty_string(self):
# 测试空字符串的情况 期望返回 '00'
self.assertEqual(self.simhash_instance.simHash(""), '00')
self.assertEqual(self.simhash_instance.string_hash(""), 0)
def test_single_word(self):
# 测试单个单词的哈希值 期望返回特定的二进制字符串
self.assertEqual(self.simhash_instance.simHash("hello"),
'0000101110101010100110000011110110110100011101101001011111111101')
def test_identical_strings(self):
# 测试两个相同字符串的哈希值 期望汉明距离为 0
hash1 = self.simhash_instance.simHash("This is a test.")
hash2 = self.simhash_instance.simHash("This is a test.")
self.assertEqual(self.simhash_instance.getDistance(hash1, hash2), 0)
def test_different_strings(self):
# 测试两个不同字符串的哈希值 期望汉明距离大于 0
hash1 = self.simhash_instance.simHash("This is a test.")
hash2 = self.simhash_instance.simHash("This is another test.")
distance = self.simhash_instance.getDistance(hash1, hash2)
self.assertGreater(distance, 0)
def test_hamming_distance(self):
# 测试汉明距离的计算 期望返回整数
hash1 = self.simhash_instance.simHash("hello world")
hash2 = self.simhash_instance.simHash("hello there")
distance = self.simhash_instance.getDistance(hash1, hash2)
self.assertIsInstance(distance, int)
def test_similarity(self):
# 测试相同文本的相似度 期望返回 1.0
original_text = "This is a simple test."
plagiarized_text = "This is a simple test."
similarity = calculate_similarity(original_text, plagiarized_text)
self.assertAlmostEqual(similarity, 1.0)
def test_two_empty_similarity(self):
# 测试两个空文本的相似度 期望返回 1.0
original_text = ""
plagiarized_text = ""
similarity = calculate_similarity(original_text, plagiarized_text)
self.assertAlmostEqual(similarity, 1.0)
def test_one_empty_similarity(self):
# 测试两个空文本的相似度 期望返回 1.0
original_text = "a"
plagiarized_text = ""
similarity = calculate_similarity(original_text, plagiarized_text)
self.assertAlmostEqual(similarity, 0)
def test_similarity_different_texts(self):
# 测试不同文本的相似度 期望返回小于 1.0
original_text = "This is a simple test."
plagiarized_text = "This is a completely different text."
similarity = calculate_similarity(original_text, plagiarized_text)
self.assertLess(similarity, 1.0)
def test_file_reading(self):
# 测试文件读取功能 确保读取的内容与写入的内容一致
with open("test_file.txt", "w", encoding='utf-8') as f:
f.write("This is a test file.")
content = read_file("test_file.txt")
self.assertEqual(content, "This is a test file.")
def test_file_writing(self):
# 测试文件写入功能 确保写入的相似度格式正确
output_file = "output.txt"
calculate_similarity("This is a test.", "This is a test.") # 计算相似度
write_file(output_file, 1.0) # 写入相似度
with open(output_file, "r", encoding='utf-8') as f:
content = f.read()
self.assertEqual(content, "1.00")
def test_invalid_file(self):
# 测试读取不存在的文件 期望抛出 FileNotFoundError
with self.assertRaises(FileNotFoundError):
read_file("non_existent_file.txt")
def test_write_to_non_existent_path(self):
# 测试写入不存在的路径,期望抛出 FileNotFoundError
with self.assertRaises(FileNotFoundError):
write_file("non_existent_directory/output.txt", 0.95)
def test_main_function_write_file_call(self):
# 准备测试数据
original_text = "This is the original text."
plagiarized_text = "This is the plagiarized text."
original_file = "original.txt"
plagiarized_file = "plagiarized.txt"
output_file = "output.txt"
# 写入原始文本和抄袭文本到临时文件
with open(original_file, 'w', encoding='utf-8') as f:
f.write(original_text)
with open(plagiarized_file, 'w', encoding='utf-8') as f:
f.write(plagiarized_text)
# 调用被测试的main函数
main(original_file, plagiarized_file, output_file)
# 读取输出文件内容
with open(output_file, 'r', encoding='utf-8') as f:
output_content = f.read()
# write_file函数正确写入了相似度到输出文件
self.assertGreater(output_content, "0.5")
测试的函数
simHash(self, content):用于计算输入内容的 SimHash 值。
string_hash(self, source):用于将输入的字符串转换为哈希值。
getDistance(self, hashstr1, hashstr2):用于计算两个哈希字符串之间的汉明距离。
read_file(file_path): 用于读取文本文件中的内容。
calculate_similarity(original_text, plagiarized_text):用于计算文本相似度。
write_file(output_file, similarity):用于将相似度写入指定的输出文件中。
测试思路
test_empty_string():测试空字符串的情况 期望返回 '00'
test_single_word(): 测试单个单词的哈希值 期望返回特定的二进制字符串
test_identical_strings(): 测试两个相同字符串的哈希值 期望汉明距离为 0
test_different_strings(): 测试两个不同字符串的哈希值 期望汉明距离大于 0
test_hamming_distance(): 测试汉明距离的计算 期望返回整数
test_similarity(): 测试相同文本的相似度 期望返回 1.0
test_two_empty_similarity(): 测试两个空文本的相似度 期望返回 1.0
test_one_empty_similarity(): 测试一个空文本和一个非空文本的相似度 期望返回 0
test_similarity_different_texts(): 测试不同文本的相似度 期望返回小于 1.0
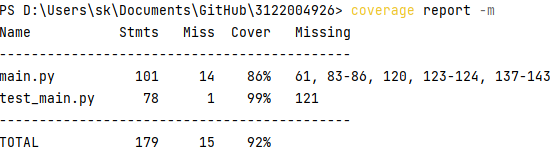
测试覆盖率截图
计算模块部分异常处理说明
- 当有一个文本为空时,返回'00'
if not keyList:
return '00'
simhash = ''
- 当文本的hash值为-1时,返回'-2',避免返回-1
if x == -1:
x = -2 # 避免返回-1
- 读取文件异常时的处理
def read_file(file_path):
try:
with open(file_path, 'r', encoding='utf-8') as f:
text = f.read()
return text
except FileNotFoundError:
raise FileNotFoundError(f"错误: 文件 '{file_path}' 未找到。")
except PermissionError:
raise PermissionError(f"错误: 没有权限读取文件 '{file_path}'。")
except Exception as e:
raise Exception(f"发生了一个错误: {e}")
- 写入文件异常时的处理
def write_file(output_file, similarity):
try:
with open(output_file, 'w', encoding='utf-8') as f:
f.write("{:.2f}".format(similarity))
except PermissionError:
raise PermissionError(f"没有权限写入文件: {output_file}")
except FileNotFoundError:
raise FileNotFoundError(f"文件路径不存在: {output_file}")
except Exception as e:
raise Exception(f"写入文件时发生错误: {e}")

