基于TCP协议的粘包问题与解决办法、struct模块、struct解决粘包问题,实现文件上传与下载
基于TCP协议的粘包问题
让我们基于tcp先制作一个远程执行命令的程序(1:执行错误命令、2:执行ls、3:执行ifconfig/ps -ef)
注意注意注意:
import subprocess # 提交系统命令模块
res=subprocess.Popen(cmd.decode('utf8'),
shell=True,
stderr=subprocess.PIPE,
stdout=subprocess.PIPE)
上面结果的编码是以当前所在的系统为准的,如果是windows,那么res.stdout.read()读出的就是GBK编码的,在接收端需要用GBK解码,且只能从管道里读一次结果
编写远程执行命令的程序
## 服务端.py文件
import socket
import subprocess # 提交系统命令模块
server = socket.socket()
server.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1)
server.bind(('127.0.0.1', 8080))
server.listen(5)
while True: # 链接循环
conn, address = server.accept()
while True: # 通信循环
try:
data = conn.recv(1024)
if len(data) == 0:
continue
cmd = data.decode('utf8') # bytes类型解码成字符串
sub = subprocess.Popen(cmd, shell=True, # 等同于调用命令解释器
stdout=subprocess.PIPE,
stderr=subprocess.PIPE
)
res1 = sub.stdout.read() # 管道内存正确输出结果
res2 = sub.stderr.read() # 管道内存错误输出结果
conn.send(res1 + res2) # 命令运行的结果
except ConnectionResetError as e:
print(e)
break
conn.close()
## 客户端.py文件
import socket
client = socket.socket()
client.connect(('127.0.0.1',8080))
while True:
choice_cmd = input('请输入cmd命令>>>:').strip()
if len(choice_cmd) == 0:
continue
client.send(choice_cmd.encode('utf8')) # 输入命令由服务端的data接收
data = client.recv(1024)
# subprocess使用当前系统默认编码,得到结果为bytes类型,在windows下需要用gbk解码
print(data.decode('utf8'))
client.close()
上述是基于tcp的套接字编写的远程命令程序,同时执行多条命令之后,得到的结果很可能只有一部分,在执行其它命令的时候又接收到之前执行的另外一部分结果,这样两次的结果粘到一起了,这个现象就叫粘包。
两种情况下会发生粘包
- 发送端需要等缓冲区满才发送出去,造成粘包(发送数据时间间隔很短,数据了很小,会合到一起,产生粘包)
- 接收方不及时接收缓冲区的包,造成多个包接收(客户端发送了一段数据,服务端只收了一小部分,服务端下次再收的时候还是从缓冲区拿上次遗留的数据,产生粘包)
须知:只有TCP有粘包现象,UDP永远不会粘包,为什么TCP会产生 粘包现象呢?这跟TCP流式协议的特点有关
-
发送端可以是1K、1K地发送数据,而接收端的应用程序可以2K、2K地提走数据,也有可能一次提走3K或6K数据,或者一次只提走几个字节的数据,也就是说,应用程序所看到的数据是一个整体,或说是一个流(stream),一条消息有多少字节对应用程序是不可见的,因此TCP协议是面向流的协议,这也是容易出现粘包问题的原因。而UDP是面向消息的协议,每个UDP段都是一条消息,应用程序必须以消息为单位提取数据,不能一次提取任意字节的数据,这一点和TCP是很不同的。怎样定义消息呢?可以认为对方一次write/send的数据为一个消息,需要明白的是当对方send一条信息的时候,无论底层怎样分段分片,TCP协议层会把构成整条消息的数据段排序完成后才呈现在内核缓冲区。
-
例如基于tcp的套接字客户端往服务端上传文件,发送时文件内容是按照一段一段的字节流发送的,在接收方看了,根本不知道该文件的字节流从何处开始,在何处结束,所谓粘包问题主要是因为接收方不知道消息之间的界限,不知道一次性提取多少字节的数据所造成的。
-
此外,发送方引起的粘包是由TCP协议本身造成的,TCP为提高传输效率,发送方往往要收集到足够多的数据后才发送一个TCP段。若连续几次需要send的数据都很少,通常TCP会根据优化算法把这些数据合成一个TCP段后一次发送出去,这样接收方就收到了粘包数据。
粘包的解决办法
问题的根源在于,接收端不知道发送端将要传送的字节流的长度,所以解决粘包的方法就是围绕,如何让发送端在发送数据前,把自己将要发送的字节流总大小让接收端知晓,然后接收端来一个死循环接收完所有数据
为字节流加上自定义固定长度报头,报头中包含字节流长度,然后一次send到对端,对端在接收时,先从缓存中取出定长的报头,然后再取真实数据,这个时候我们就需要用到struct模块
-
我们可以把报头做成字典,字典里包含将要发送的真实数据的详细信息,然后json序列化,然后用struct将序列化后的数据长度打包成4个字节(4个自己足够用了)
-
发送时:先发报头长度-->再编码报头内容然后发送-->最后发真实内容
-
接收时:先收报头长度,用struct取出来--->根据取出的长度收取报头内容--->然后解码,反序列化从反序列化的结果中取出待取数据的详细信息--->然后去取真实的数据内容
struct模块
python strtuct模块主要在Python中的值于C语言结构之间的转换。可用于处理存储在文件或网络连接(或其它来源)中的二进制数据。
struct模块可以把一个类型,如数字,转成固定长度的bytes
import struct
import json
d = {
'desc': '这是非常重要的数据',
'size': 1231283912834234234234324324912,
'info': '数据很重要的哦!!!'
}
d = json.dumps(d)
res = struct.pack('i',len(d)) # 报头
print(len(res)) # 4
res1 = struct.unpack('i',res)[0] # 真实内容
print(res1) # 164
struct模块格式化对照表
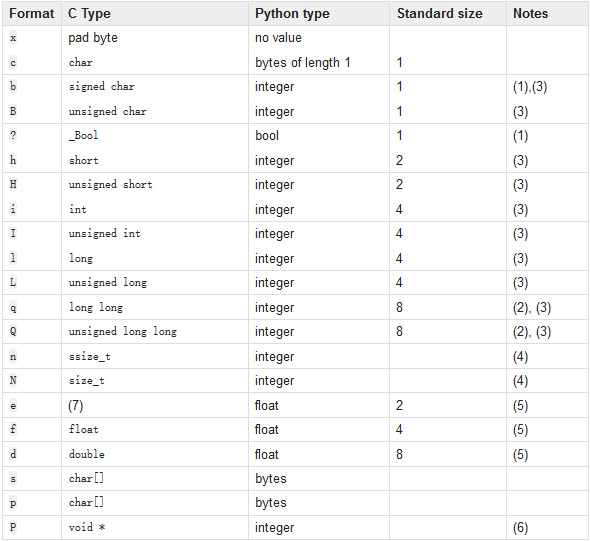
简易版报头
借助第三方模块struct,解决粘包,把每一次命令发出的结果全部收完,实现方式如下:
# 服务端简版.py文件
import socket
import subprocess
import struct # 导入struct模块
server = socket.socket()
server.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1)
server.bind(('127.0.0.1', 8080))
server.listen(5)
while True: # 链接循环
conn, address = server.accept()
while True: # 通信循环
try:
data = conn.recv(1024) # 接收cmd命令
if len(data) == 0:
continue
cmd = data.decode('utf8') # bytes类型解码成字符串
print("客户端发送的命令:%s" % cmd)
sub = subprocess.Popen(cmd, shell=True, # 等同于调用命令解释器
stdout=subprocess.PIPE,
stderr=subprocess.PIPE
)
res1 = sub.stdout.read() # 管道内存正确输出结果
res2 = sub.stderr.read() # 管道内存错误输出结果
res = res1 + res2 # 命令运行的结果,可能很大
# 1.制作报头
header = struct.pack('i', len(res))
# 2.发送报头
conn.send(header)
# 3.发送真实数据
resp = conn.send(res)
print("服务端发送数据大小:%s" % resp)
except ConnectionResetError as e:
print(e)
break
conn.close()
# 客户端简版.py文件
import socket
import struct
client = socket.socket()
client.connect(('127.0.0.1', 8080))
while True:
choice_cmd = input('请输入cmd命令>>>:').strip()
if len(choice_cmd) == 0:
continue
client.send(choice_cmd.encode('utf8')) # 输入命令由服务端的data接收
# 1.先接收固定长度为4的报头数据
header = client.recv(4)
# 2.解析报头
header_length = struct.unpack('i', header)[0] # unpack拆包,解出报头的长度
# 3.在接收真正的数据
real_data = client.recv(header_length)
# subprocess使用当前系统默认编码,得到结果为bytes类型,在windows下需要用gbk解码
print(real_data.decode('utf8')) # Windows默认gbk编码
client.close()
"""
ps:这就是自定义协议,数据组织的规格:先造了一个4个字节的报头发送,再接着发送了真正
的数据,接收端在解析数据规格的时候,先解析出4个字节的报头,接着接收了真正的数据
"""
升级版报头
借助第三方模块struct,自定义协议解决粘包问题,升级版本实现方式如下:
## 服务端升级版.py文件
import socket
import subprocess
import struct # 导入struct模块
import json
server = socket.socket()
server.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1)
server.bind(('127.0.0.1', 8080))
server.listen(5)
while True: # 链接循环
conn, address = server.accept()
while True: # 通信循环
try:
data = conn.recv(1024) # 接收cmd命令
if len(data) == 0:
continue
cmd = data.decode('utf8') # bytes类型解码成字符串
sub = subprocess.Popen(cmd, shell=True, # 等同于调用命令解释器
stdout=subprocess.PIPE,
stderr=subprocess.PIPE
)
res1 = sub.stdout.read() # 管道内存正确输出结果
res2 = sub.stderr.read() # 管道内存错误输出结果
res = res1 + res2 # 命令运行的结果,可能很大
# 1.定义一个字典数据(为避免粘包,必须自定制报头)
data_dict = {
'desc': '这是非常重要的数据',
'size': len(res),
'info': '数据很重要的哦!!!'
}
# 2.为了该报头能传送,需要序列化并且转为bytes
data_json = json.dumps(data_dict)
# 3.制作字典报头(用struck将报头长度这个数字转成固定长度:4个字节)
dict_header = struct.pack('i', len(data_json)) # 这4个字节里只包含了报头的长度
# 4.发送字典报头
conn.send(dict_header)
# 5.发送字典
conn.send(data_json.encode('utf8'))
# 3.发送真实数据
conn.send(res)
except ConnectionResetError as e:
print(e)
break
conn.close()
## 客户端升级版.py文件
import json
import socket
import struct
client = socket.socket()
client.connect(('127.0.0.1', 8080))
while True:
choice_cmd = input('请输入cmd命令>>>:').strip()
if len(choice_cmd) == 0:
continue
client.send(choice_cmd.encode('utf8')) # 输入命令由服务端的data接收
# 1.先接收固定长度为4的报头数据
header = client.recv(4)
# 2.解析字典报头
dict_length = struct.unpack('i', header)[0] # unpack拆包,解出报头的长度
# 3.接收字典数据
real_data = client.recv(dict_length)
# 4.解析字典(json格式的bytes数据,loads方法会自动解码然后反序列化)
real_dict = json.loads(real_data)
print(real_dict)
# 5.获取字典中的各项数据
# 获取数据大小
data_length = real_dict.get('size')
# 获取真正的数据
data_bytes = client.recv(data_length)
print(data_bytes.decode('utf8'))
client.close()
"""
请输入cmd命令>>>:ps -ef
{'desc': '这是非常重要的数据', 'size': 71002, 'info': '数据很重要的哦!!!'}
请输入cmd命令>>>:ls
{'desc': '这是非常重要的数据', 'size': 26, 'info': '数据很重要的哦!!!'}
客户端.py
服务端.py
"""
上传文件数据
## 客户端.py
import socket
import struct
import json
import os
client = socket.socket()
client.connect(('127.0.0.1', 8080))
while True:
data_path = r'/Users/gengfeng/Desktop/音乐'
# print(os.listdir(data_path)) # [文件名称1 文件名称2 ]
music_name_list = os.listdir(data_path)
for i, j in enumerate(music_name_list, 1):
print(i, j)
choice = input('请选择您想要上传的电影编号>>>:').strip()
if choice.isdigit():
choice = int(choice)
if choice in range(1, len(music_name_list) + 1):
# 获取文件名称
music_name = music_name_list[choice - 1]
# 拼接文件绝对路径
music_path = os.path.join(data_path, music_name)
# 1.定义一个字典数据(为避免粘包,必须自定制报头)
new_name = input('请输入重命名>>>:').strip()
data_dict = {
'file_name': f'{new_name}.mp3',
'desc': '这是非常好听的歌曲',
'size': os.path.getsize(music_path),
'info': '下午挺困的,可以提神醒脑'
}
# 2.为了该报头能传送,需要序列化并且转为bytes
data_json = json.dumps(data_dict)
# 3.制作字典报头
data_first = struct.pack('i', len(data_json))
# 4.发送字典报头
client.send(data_first) # 先发报头的长度,4个bytes
# 5.发送字典
client.send(data_json.encode('utf8')) # 再发报头的字节格式
# 6.发送真实数据
with open(music_path, 'rb') as f:
for line in f:
client.send(line)
## 服务端.py
import socket
import struct # 导入struct模块
import json
server = socket.socket()
server.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1)
server.bind(('127.0.0.1', 8080))
server.listen(5)
while True: # 链接循环
conn, address = server.accept()
while True: # 通信循环
# 1.先接收固定长度为4的字典报头数据,得到报头长度的字节格式
recv_first = conn.recv(4)
# 2.解析字典报头,提取报头的长度
dict_length = struct.unpack('i', recv_first)[0]
# 3.接收字典数据,收取报头的bytes格式
real_data = conn.recv(dict_length)
# 4.解析字典(json格式的bytes数据 loads方法会自动先解码 后反序列化)
real_dict = json.loads(real_data)
# 5.获取字典中的各项数据
data_length = real_dict.get('size')
file_name = real_dict.get("file_name")
# 6.循环接收客户端上传的数据
recv_size = 0
with open(file_name, 'wb') as f:
while recv_size < data_length:
data = conn.recv(1024)
recv_size += len(data)
f.write(data)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号