【MindSpore:跟着小Mi一起机器学习吧!】介绍篇
最近小Mi发现一个问题!为什么某听歌软件给我推荐的绝大多数都是我的style?为什么某橙色购物软件给我推荐的也有不少就能直接给我种草?小Mi灵机一动,掏出手机开始求助百度大哥,经过一通搜索,才发现这就是如今非常火热的人工智能技术!不仅如此,人工智能技术原来已经真真切切地存在于我们生活中了,比如我们每天收到的广告邮件会被自动识别为垃圾邮件,手机的相册会可以通过不同人脸进行分组,还有我们现在常见的各种语音助手等等这些都是与之相关的小技术。小Mi顿时来了兴趣,心想,可以啊!要不把这个东西研究研究了解下?!一不做二不休,既然要研究,就索性研究它个底朝天!首先,小Mi准备先从基础的机器学习开始,如果大家也有兴趣,就跟小Mi一起学起来吧~
1 什么是机器学习
什么是机器学习,什么是机器学习(不好意思,小Mi脑子里突然冒出了什么是快乐星球这个梗),那么机器学习到底是什么呢?小Mi追其本源,搜到了出自机器学习教父Tom Mitchell给出的这样一个定义:对于某类任务T和性能度量P,如果一个计算机程序在T上以P衡量的性能随着经验E而自我完善,那么就可以称这个计算机程序在从经验E学习。果然教父就是教父,说话就是跟别人不一样,小Mi看得脑子转的晕乎乎的,不过这可难不倒小Mi!小Mi查找了各种资料,最后发现通过案例来理解这段话会更加深刻!废话不多说,上例子!
就拿邮箱识别垃圾邮件来举例,假设电子邮件程序会观察收到的邮件是否被标记为垃圾邮件。在邮件客户端中,点击“垃圾邮件”按钮报告某些Email为垃圾邮件,基于被标记为垃圾的邮件,程序便能更好地学习如何过滤垃圾邮件。在这个案例中,T表示标记邮件是否为垃圾邮件,而E则为观察标记邮件是否为垃圾邮件的过程,P就是指区分垃圾邮件成功的正确率。
换句话说,为什么我们可以根据蜻蜓低飞断定一会要下雨呢?为什么可以通过水果表皮的颜色、形状等判断其成熟度呢?那是因为我们已经积累了很多经验,而通过对经验的利用,就能对新情况做出有效的决策。而机器学习,就是将这样的一个学习、预判的工作交给了计算机,让其去研究各种“学习算法”。如果小Mi再这么解释也无法理解的话,那么小Mi只能说一句,小Mi做不到啊(表情包直接砸向你)!
2 监督学习与无监督学习
走走走,我们继续去吸取新知识的养分!
小Mi发现,原来各种不同类型的学习算法最主要的两类就是监督学习和无监督学习,这是最常用的,其他的还有一些强化学习啊、推荐系统啊等等之类的。既然监督学习和无监督学习是两座大山,那么何不努努力跨过去!
2.1 监督学习
还是老样子!小学时候老师就会教我们某个公式如何表示,它的原理是什么,以及在做题时可以怎么使用。那么什么是监督学习呢?根据小Mi的浅显理解,既然是监督学习,肯定有个什么标准或者什么条件“监督”着。对吧,字面上确实是这么个意思,然后小Mi又召唤了一下百度大哥,发现例子什么的真的是神助攻,让我理解起来一点都不费劲!
就拿国民话题房子来说。假设小Mi的手里有一栋房子需要售卖(让小Mi再幻想一会,哈哈哈),应该给它标上多少的价格比较合适呢?房子的面积是100平方米,价格是100万,120万还是140万呢?
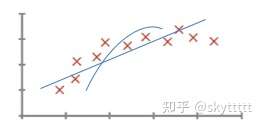
很显然,小Mi希望获得房价与面积之间的某种关系。那么小Mi便可以调查周边与之房型类似的一些房子,获得一组数据。通过这组数据,我们可以画出一条直线或者符合其价格规律的抛物线,从而便可以确定房屋售卖的价格。
这个就是一个监督学习算法的例子,监督学习就是指我们给算法一个数据集,其中包含了正确答案,也就是说我们给房价一个数据集,在这个数据集中的每个样本,我们都给出正确的价格,即这个房子实际卖价,算法的目的就是给出更多的正确答案。而这样的问题同时也被称为回归问题,因为预测的结果是一个连续的数值输出,也就是说例子中的价格是连续的。
举一反三,既然预测的输出可以是连续的,那么也可以是离散的啦~小Mi就了解到,针对这类情形,就摇身一变变成了分类问题,预测小Y(嘻嘻,希望小Y不要介意)今天上班是否迟到,那么无非就是两个结果,一个是迟到,一个是没有迟到。当然了,在迟到这个问题上还可以继续分类,一个是迟到半小时以内,还有一个是迟到半个小时以上。因此这样的学习任务就是分类问题啦,是不是很好理解!
2.2 无监督学习
上述在关于监督学习的学习中,小Mi认为监督学习中是清楚地告知了什么是“正确答案”,这个也就是“监督”的意义,而在无监督学习中,就没有所谓的条件或标准啦,那么这样一来数据集便会有所不同,都具有相同的标签或者都没有标签,换句话说无监督学习就是让计算机自己学习(不得不夸一下计算机真是一个勤奋聪明的好孩子!)。
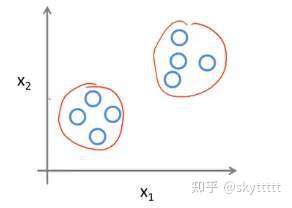
假设给你一个数据集,不知道拿它来做什么,也不知道每个数据点究竟是什么,只是被告知这里有个数据集,你能在其中找到某种结构吗?反正对于小Mi这种普通人类来说,真的无从下手。但是计算机不一样呀!计算机对于给定的数据集,通过无监督学习算法判定上图中的数据集包含两个不同的簇(如上图),可以把它分成两个不同的簇,这就是聚类算法。
再来举个例子!比如百度(嘻嘻,又提到了百度大哥)搜索机器学习,会弹出各种不同的与之相关的URL链接,百度所做的就是每天去网络上收集相关的各种信息,然后将他们组合在一起,变成一个个的专题系列。
当然啦,聚类算法只是无监督学习中的一种,监督学习也不仅仅只是举两个例子那么简单,如果你还想继续跟着小Mi一起机器学习的话,坐等小Mi继续更新吧~
PS:最后最后要尤其!特别!十分!感谢的吴恩达老师,小Mi的这个机器学习系列后续都会跟着吴恩达老师的视频一个个学习的,真的不得不说,大佬就是大佬,复杂的理论都能找到简单的实例来以便我们的理解,膜拜!
本文转载自:https://bbs.huaweicloud.com/forum/forum.php?mod=viewthread&tid=128661

 浙公网安备 33010602011771号
浙公网安备 33010602011771号