python爬取学习通视频
前言
emmm,因为针对学习通我没有找到下载视频的地方,然后我就想着自己通过python的requests爬取下来。为什么想爬呢,因为有些课程我是认真看看的(之前时间太紧,没时间看。)
分析部分+实现部分
课程页面
url: http://i.mooc.chaoxing.com/space/index?t=1662988349781
t:为时间戳(不重要,可以去掉)
首先咱需要获取courseid和classid(分析得知),一开始我想的是直接请求课程页面的url,但是吧,response为如下内容
response = requests.get('http://i.mooc.chaoxing.com/space/index?t=1662988349781')
没错,也就是登录页面。那么我们就要用到session,并且先登录,再去请求该地址。
好的,那也就是,要搞到登录的url
获取登录url
通过输入错误密码,获取登录url,我们会在xhr里面看到的一个“fanyalogin”,然后里面的参数正常带着我们的手机号和密码,但是会发现密码是经过加密的了。(图片违规,那就由各位自个去看了)
或者--->这里
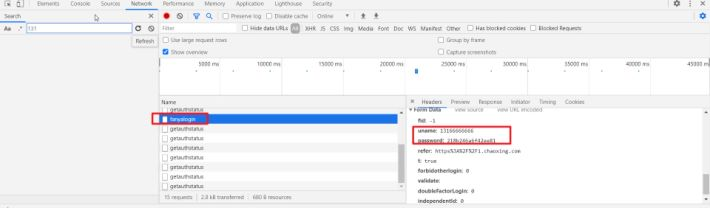
莫得慌,咱在这个地方搜索 “password”,然后会发现四个红框的,都是不想要的数据(有兴趣的可以看看),也就那个login.js的才是咱想要的
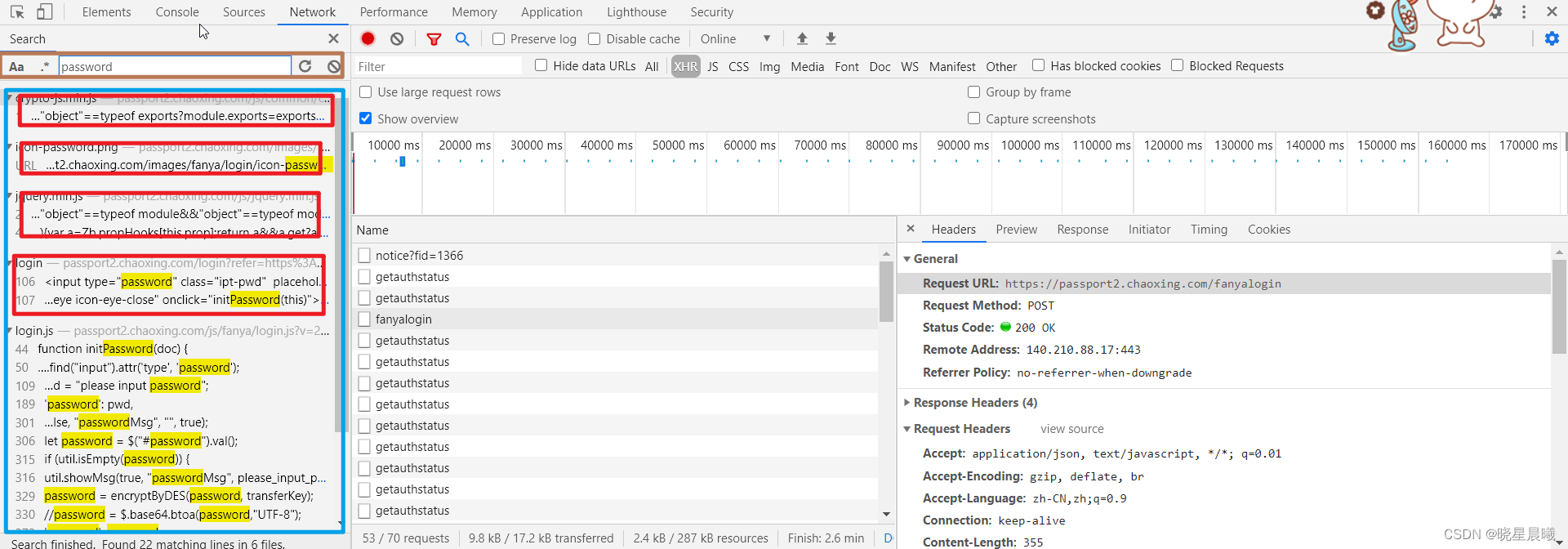
随便点一行,然后点击response,随便在一个地方右键,点击"open in Sources panel"
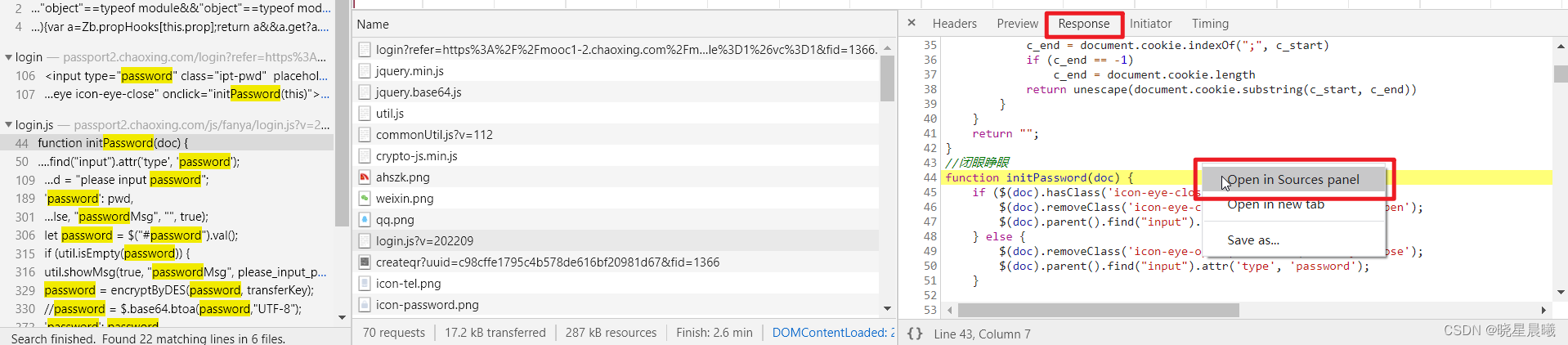
然后进入了如下界面,然后在里面再搜索"password"(ctrl+f即可打开搜索框),会发现如下东东,没错上面的红框就是加密方式,发现是DES加密,那咱们验证一下,所以百度一下DES在线加密,随便点一个界面进去
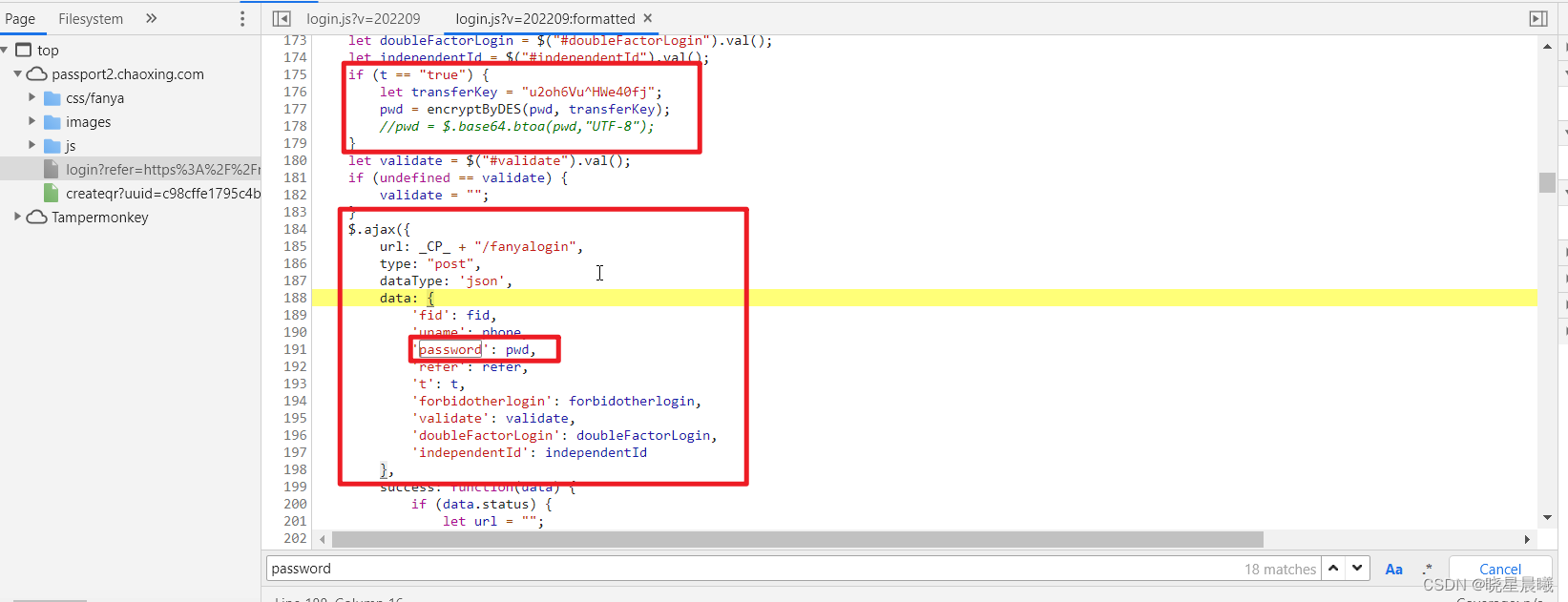
阿嘞,可见,password的结果和请求参数的不同。没事,莫得慌,咱搜下"encryptByDES"
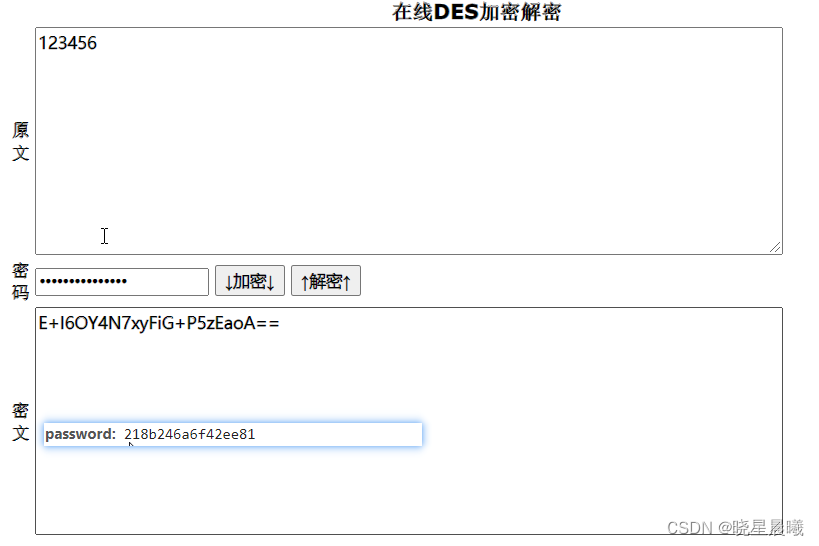
搜索后发现,它的解密方式如下,也就是先对key进行utf8加密,然后采用AES加密
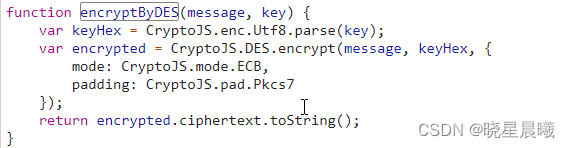
因为我在网上没找到相关的在线加密,那么我就直接consloe操作一下。因为是其自带的,所以是正确的。OK,找到加密方式,那么用自己密码转一下(这边就不演示了)
2023.11.2注:现在学习通的加密方式改成AES了。你们可以按之前的方式查找便知。其实也可以不用如下图。
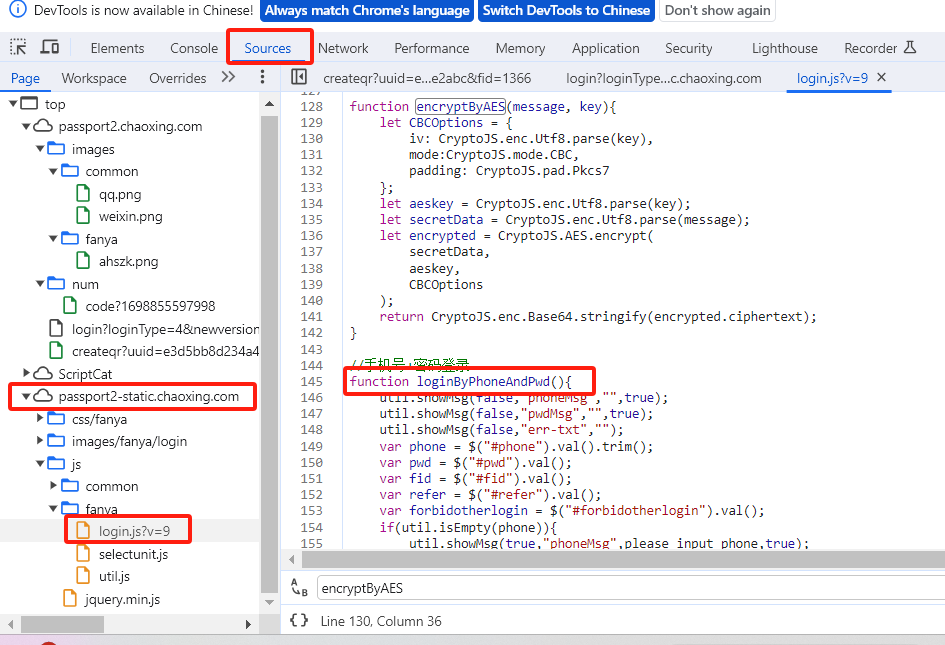

登录url的data。没错就只有这四个参数(省略验证过程)

登录请求代码(post请求)

import requests
session = requests.Session()
response1 = session.post("http://passport2.chaoxing.com/fanyalogin", data=data1)
response1.encoding = response1.apparent_encoding
print(response1.text)
发送登录请求,后控制台输出这个,则证明登录成功了,然后在session的状态下,再次尝试发送前面的课程url请求

如图,成功获取到了。那么开始获取courseId
获取courseId和classid
依然是检查面板,随便选中一个课程,根据css_selector语法,发现"courseItem curFile"的结果符合(我这边,总共九个课程)。
为啥需要courseId和classId,从那个href便可以知道。注意href上的cpi,它是固定的,但不可缺少。
可见,courseId和classId的值在input的value那。而课程名,相信各位能找到。
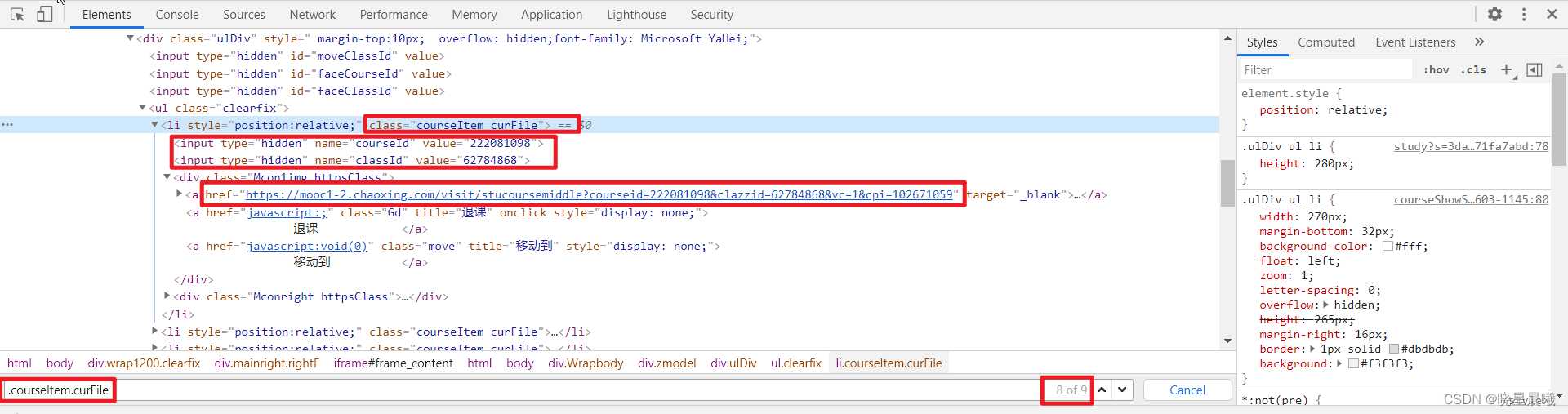
python代码如下:
import parsel
response2 = session.get('http://i.mooc.chaoxing.com/space/index')
selector = parsel.Selector(response2.text)
lis = selector.css('.courseItem.curFile')
for li in lis:
courseId = li.xpath('input[@name="courseId"]/@value').get()
classId = li.xpath('input[@name="classId"]/@value').get()
courseName = li.css('.courseName::text').get()
print(courseId, classId, courseName)
运行后,发现没有输出

然后通过查看源码,发现其在iframe里,然后发现其那里有个url,通过访问,发现就是课程列表页面
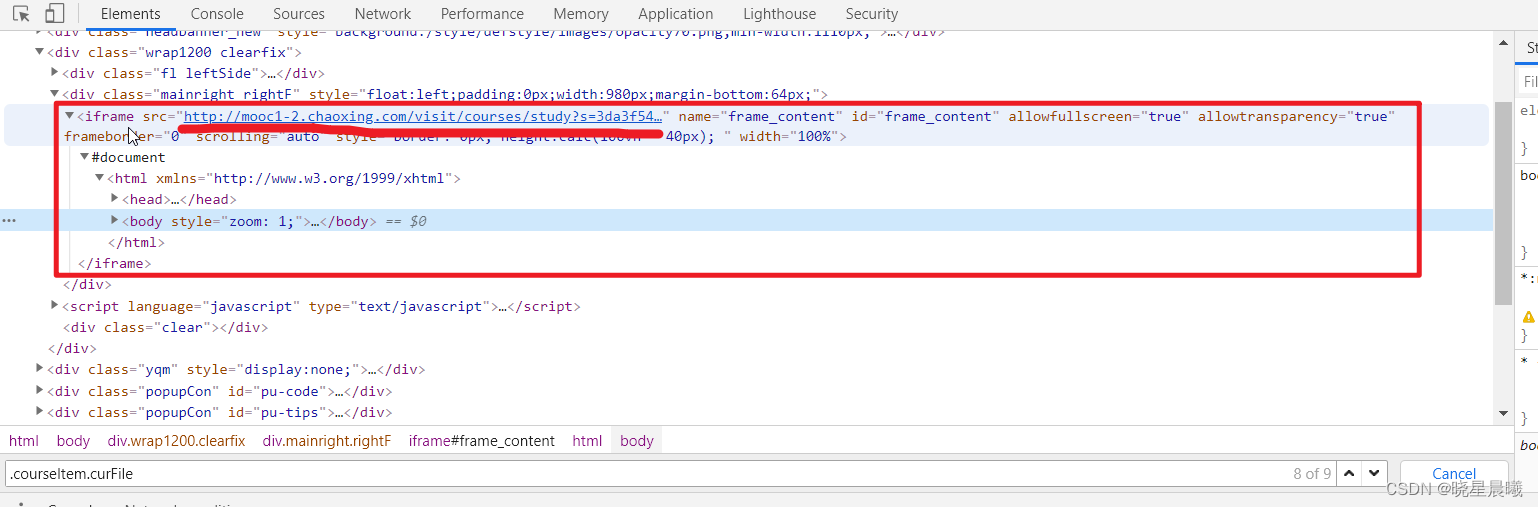
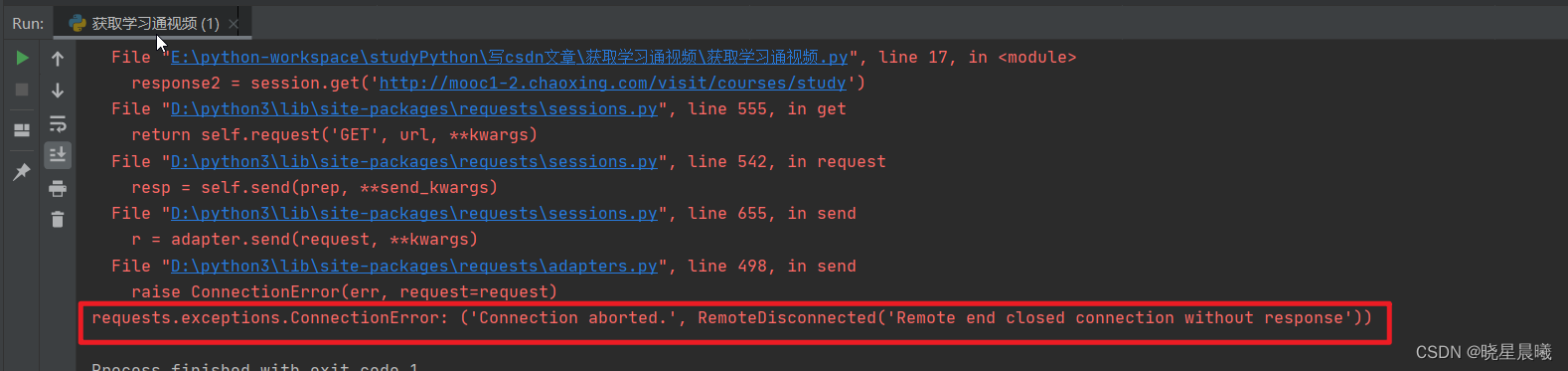
OK,咱们把上面代码的url换成该页面的,运行输出如下。咦,居然报错了。好,咱们来分析一下。
咱们浏览器直接上访问是可以的。那么这是为啥呢。细心的同志会发现,我的requests里面没得headers,好的,那么咱加上headers试试
代码如下:
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36'
}
response2 = session.get('http://mooc1-2.chaoxing.com/visit/courses/study', headers=headers)
selector = parsel.Selector(response2.text)
lis = selector.css('.courseItem.curFile')
for li in lis:
courseId = li.xpath('./input[@name="courseId"]/@value').get()
classId = li.xpath('./input[@name="classId"]/@value').get()
courseName = li.css('.courseName::text').get()
print(courseId, classId, courseName)
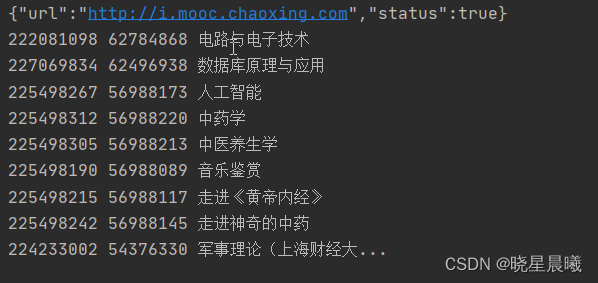
运行结果:
可见,成功输出
OK,现在有了courseId和classId,那么就是获取chapterId了
获取chapterId
通过上面,咱们知道,进入章节页面的地址是:
https://mooc1-2.chaoxing.com/visit/stucoursemiddle?courseid=225498215&clazzid=56988117&vc=1&cpi=102671059
通过浏览器访问发现url上多了个enc,但是其实不要紧
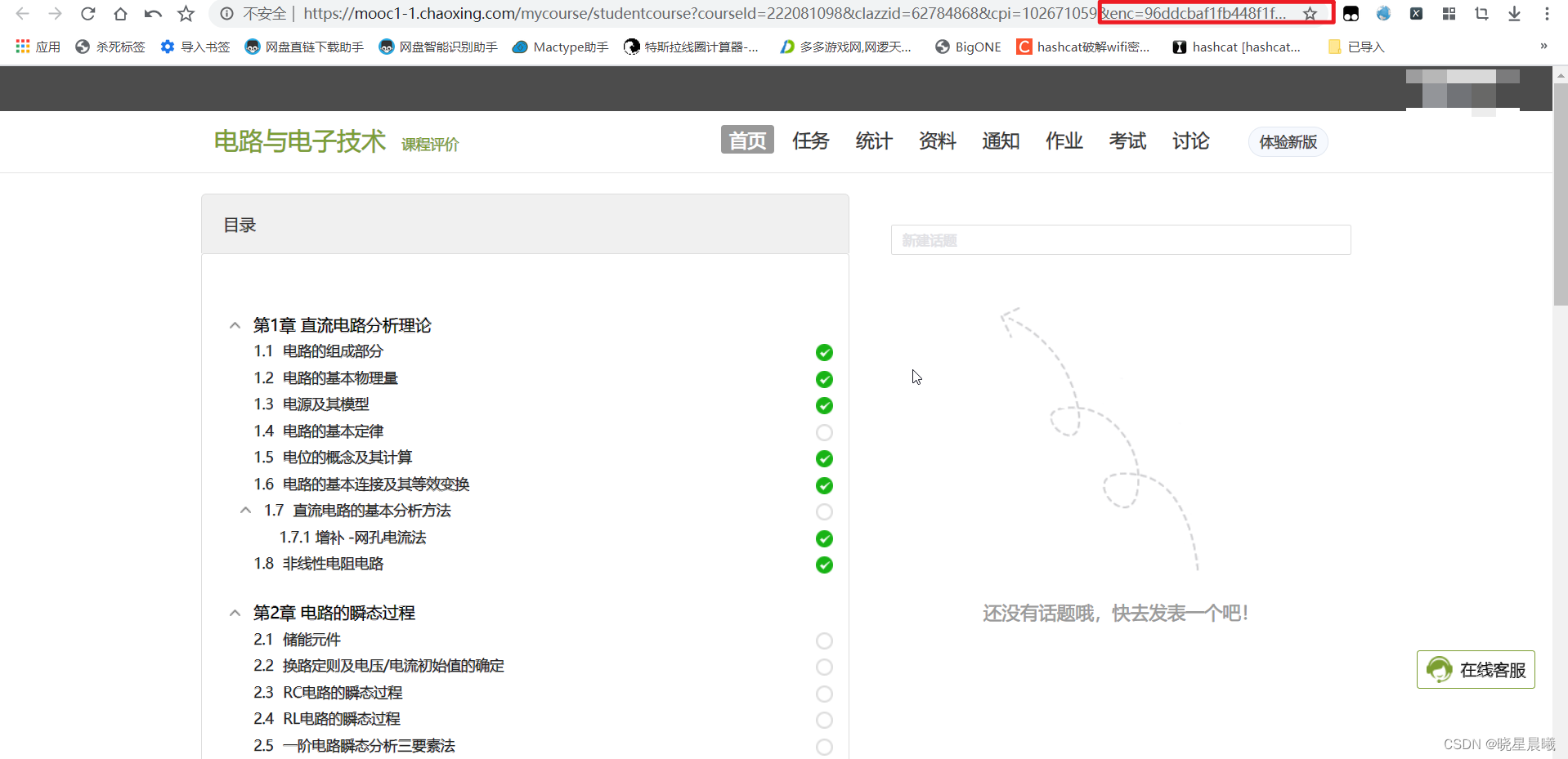
通过分析network可见,有个
"stucoursemiddle?courseid=225498215&clazzid=56988117&vc=1&cpi=102671059"
虽然它的response是无法加载该数据,但其实就是个幌子(因为之前想着获取enc,但是发现没必要,有兴趣的,可以去研究一下)。
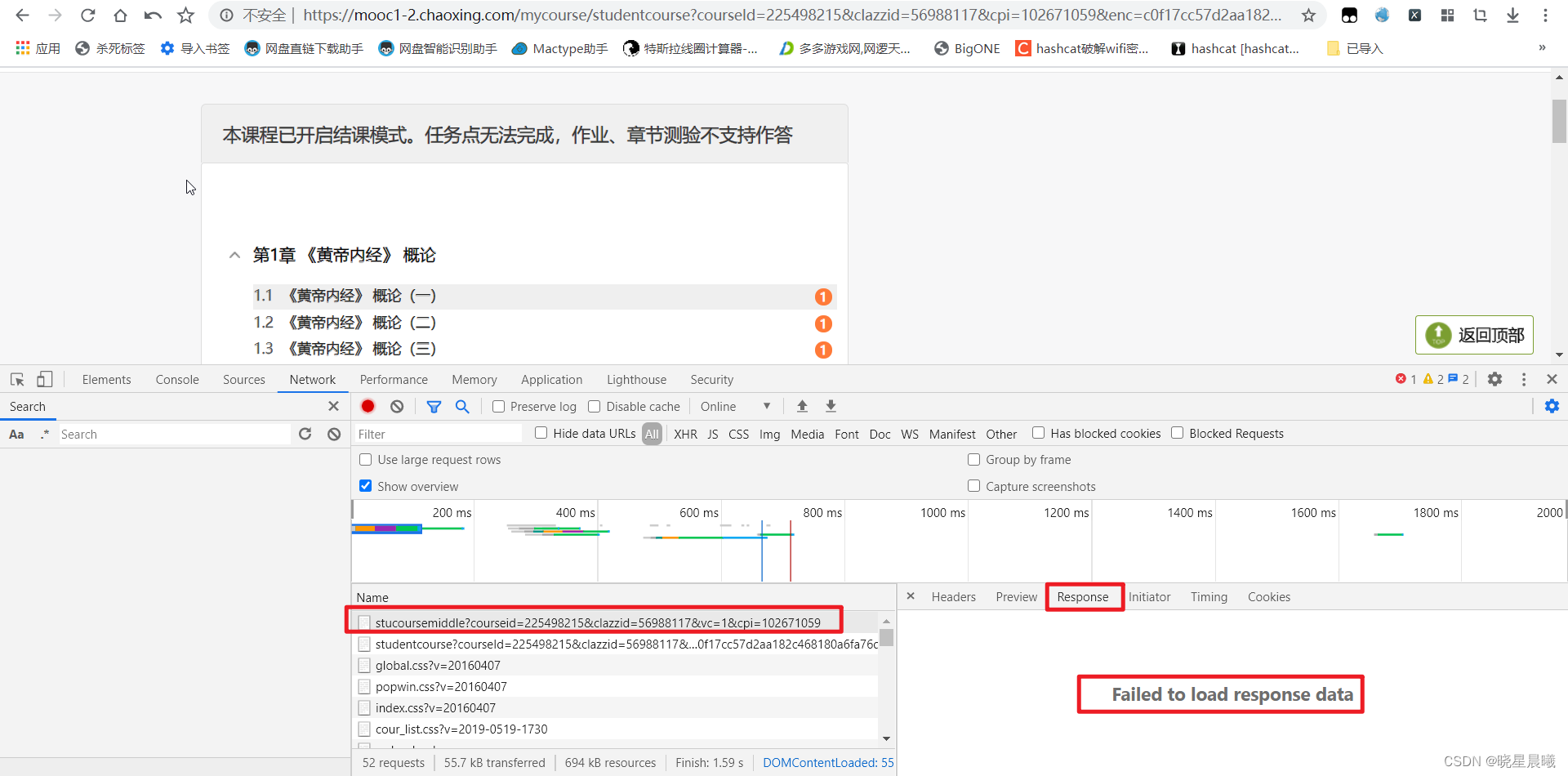
为何这么说呢,咱用requests后输出源码进行相关章节搜索会发现其存在。既然存在那么就可以selector
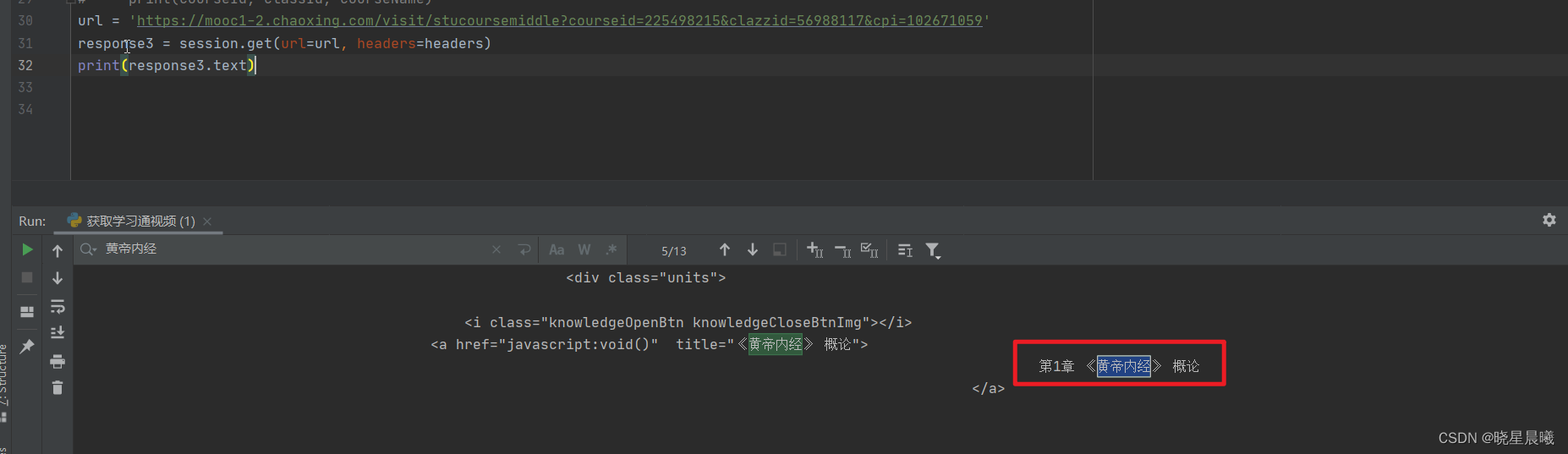
OK,获取chapterId。通过分析源码可见,chapterId在class为"clearfix"的h3中的a标签的href中,且数量满足(可以数数看看,或者直接看最后一个匹配项)。
进入看视频的则通过下面的href
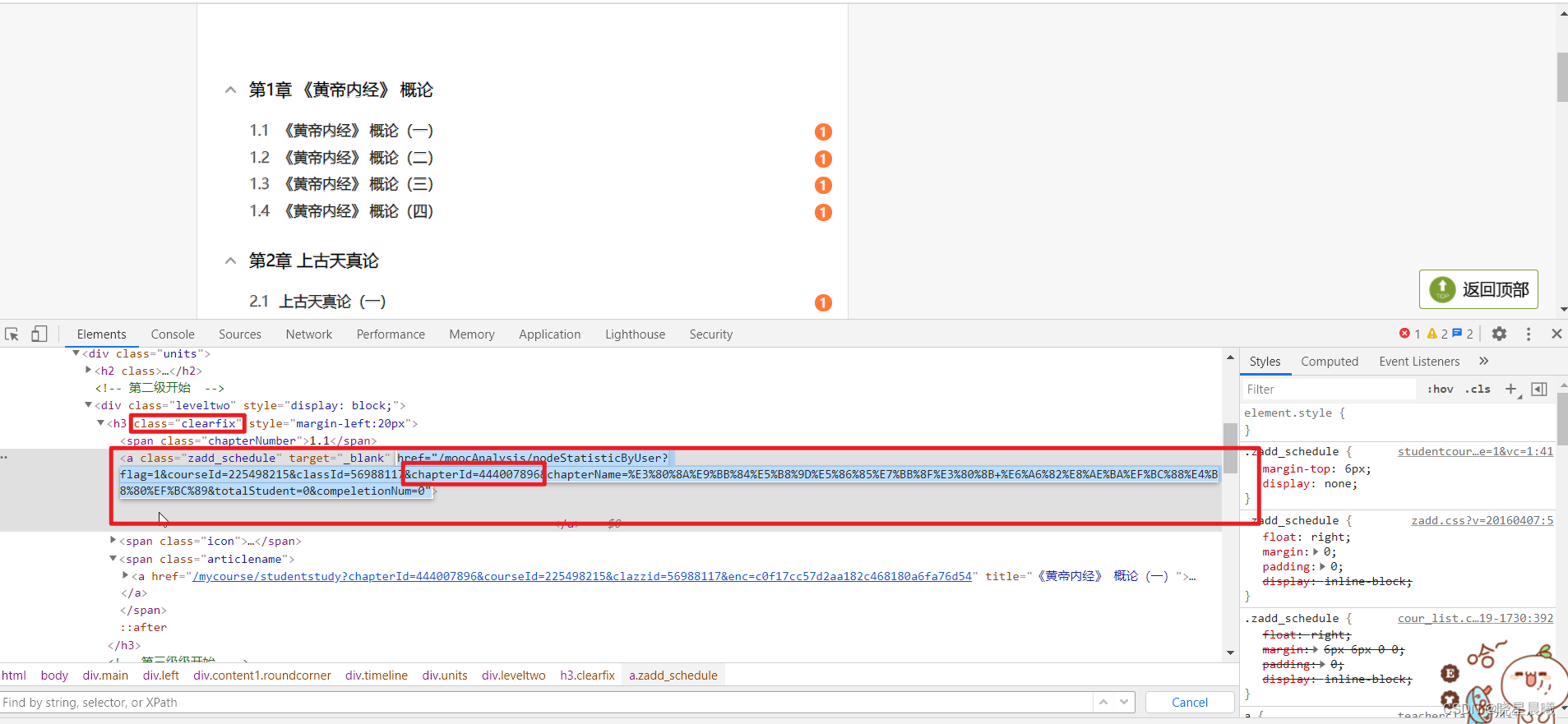
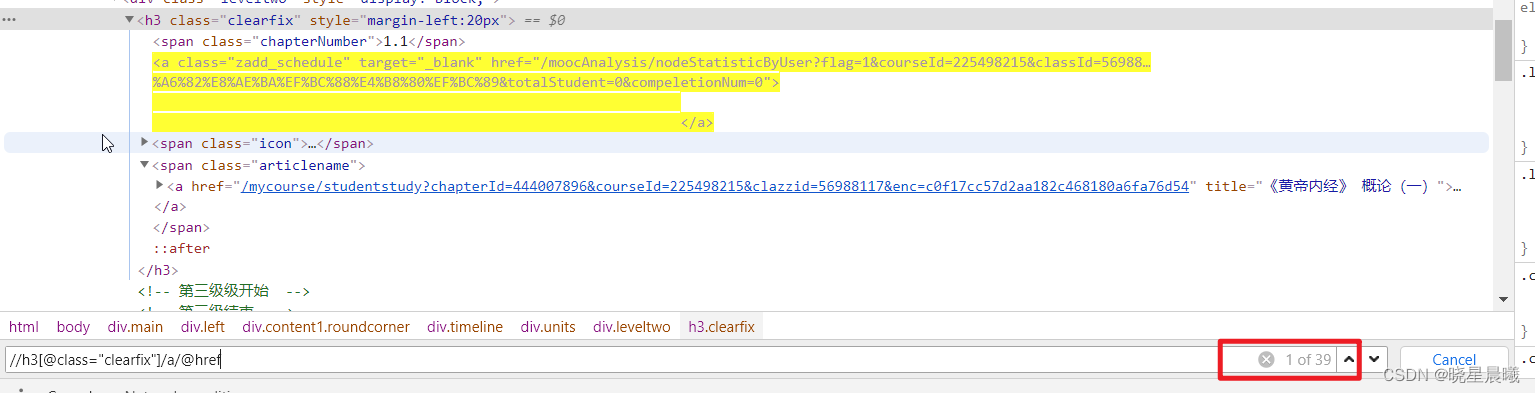
OK,python代码如下:
url = 'https://mooc1-2.chaoxing.com/visit/stucoursemiddle?courseid=225498215&clazzid=56988117&cpi=102671059'
response3 = session.get(url=url, headers=headers)
selector = parsel.Selector(response3.text)
h3s = selector.css('.clearfix .articlename a::attr(href)')
for h3 in h3s:
chapterId = re.findall('chapterId=(.*?)&', h3.get(), re.S)[0]
print(chapterId)
输出如下:
可见,成功获取

通过分析,可见该href为进入章详情页面的url
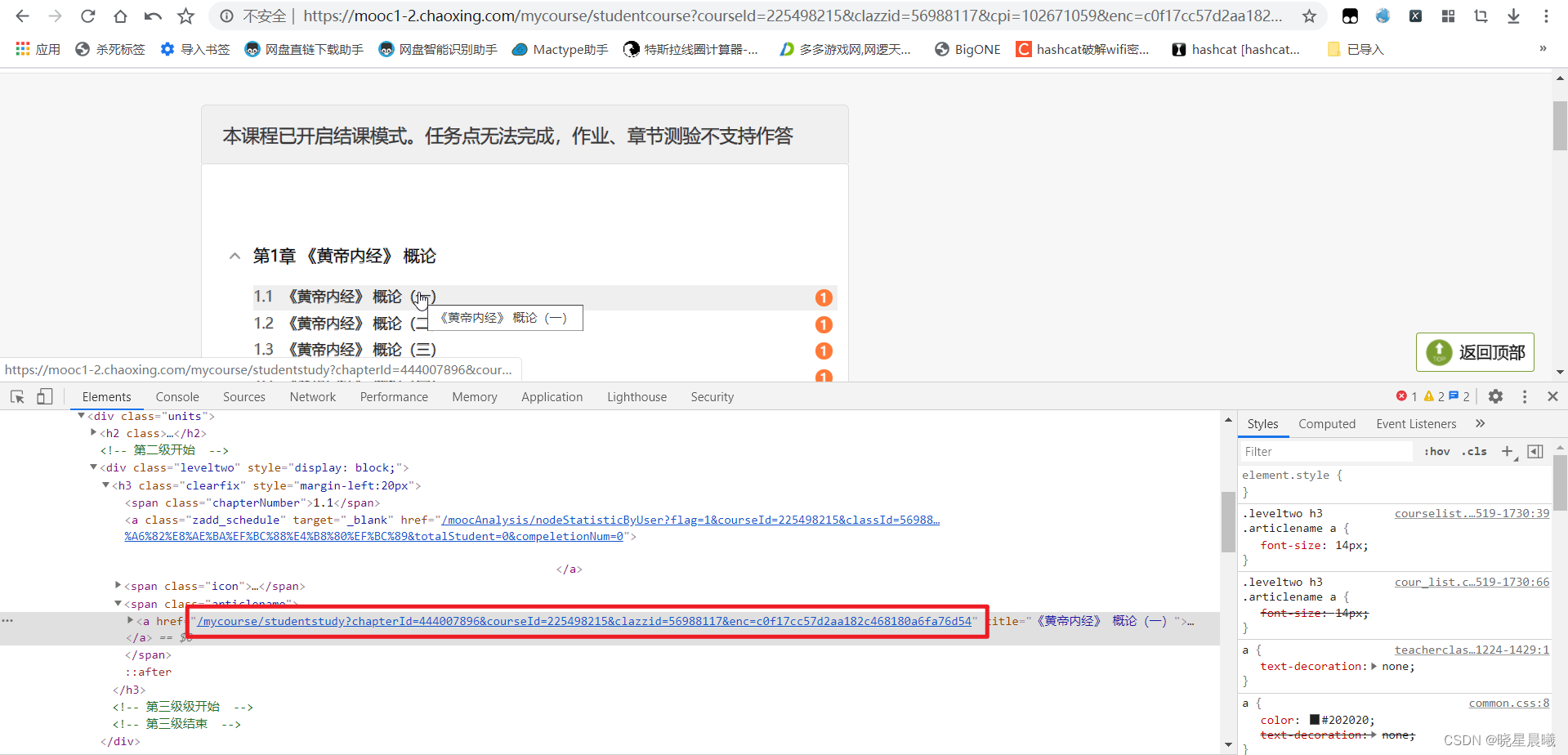
OK,咱访问它
https://mooc1-2.chaoxing.com/mycourse/studentstudy?chapterId=444007896&courseId=225498215&clazzid=56988117&enc=c0f17cc57d2aa182c468180a6fa76d54
然后点击视频(有的第一个就是视频),然后在xhr里面会有个
540698c953703d8b3b55fbf0?k=1366&flag=normal&_dc=1663079564885
点击,看Preview,发现http的值是视频。不要以为结束了。
那咱就是要想办法获得"540698c953703d8b3b55fbf0"
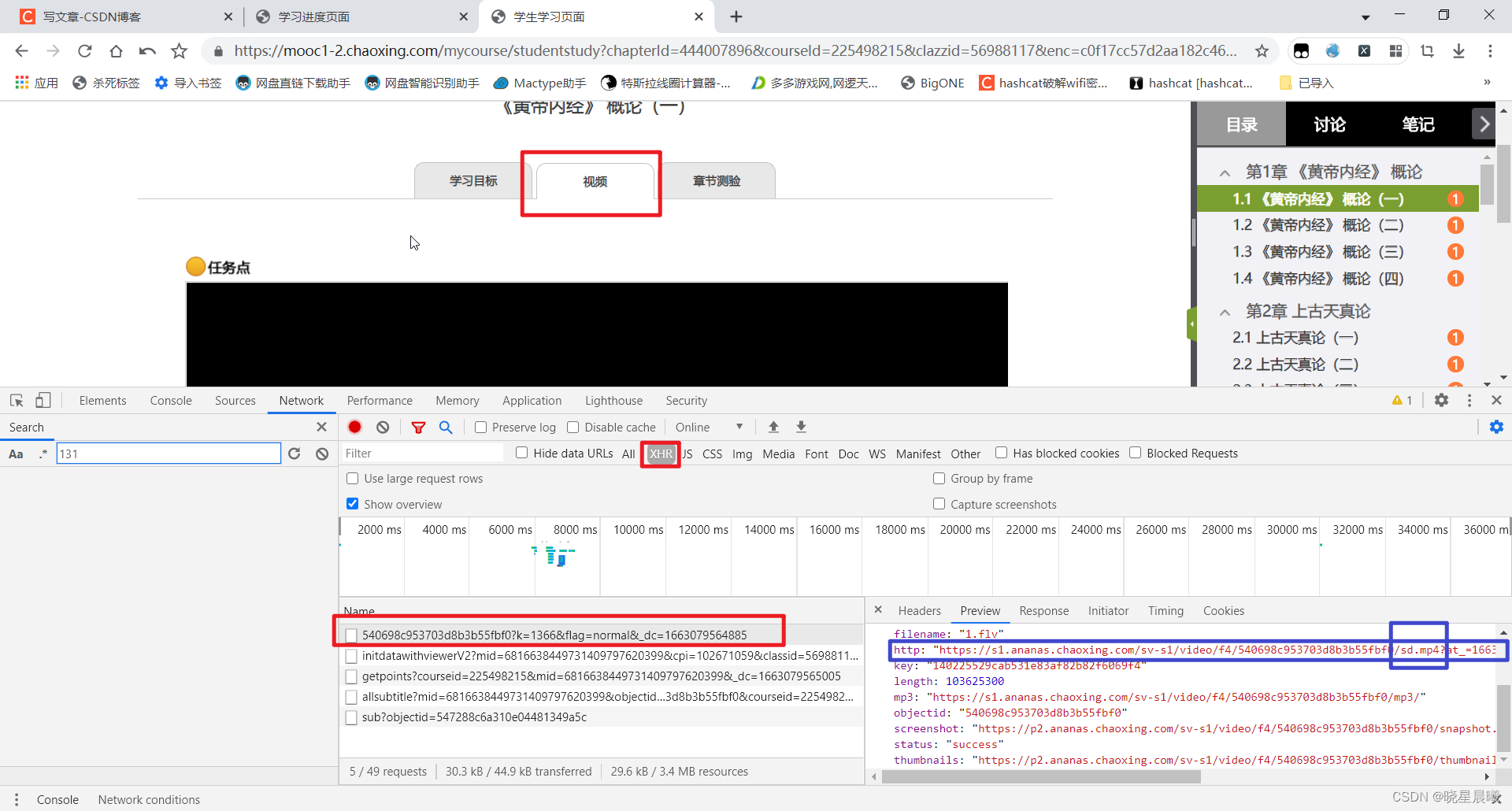
OK,还是搜索一下,通过分析发现,这个cards里面的response里有个"objectId"便就是。
没错,这就是咱需要的objectId(课件也会具有这个)
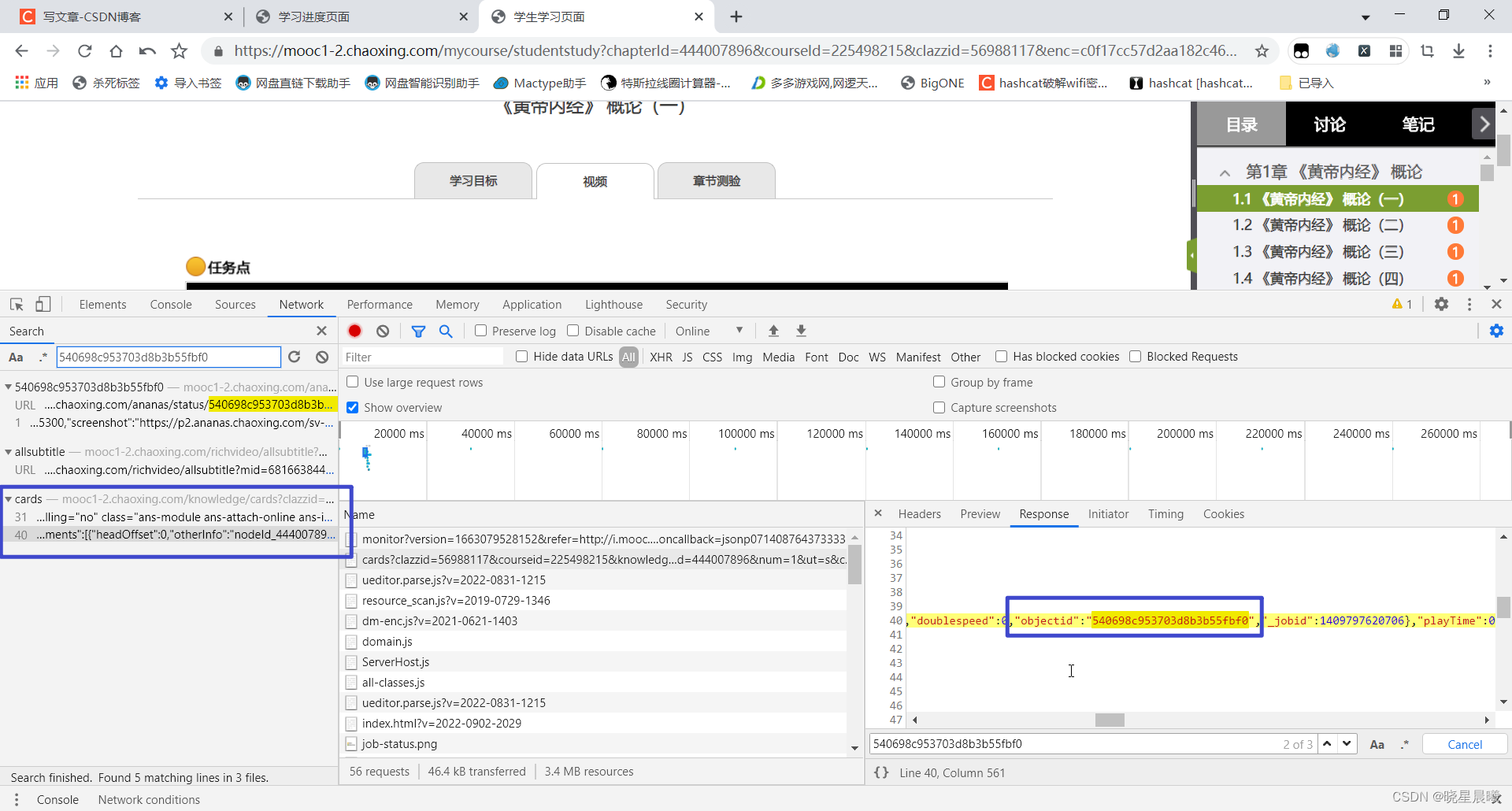
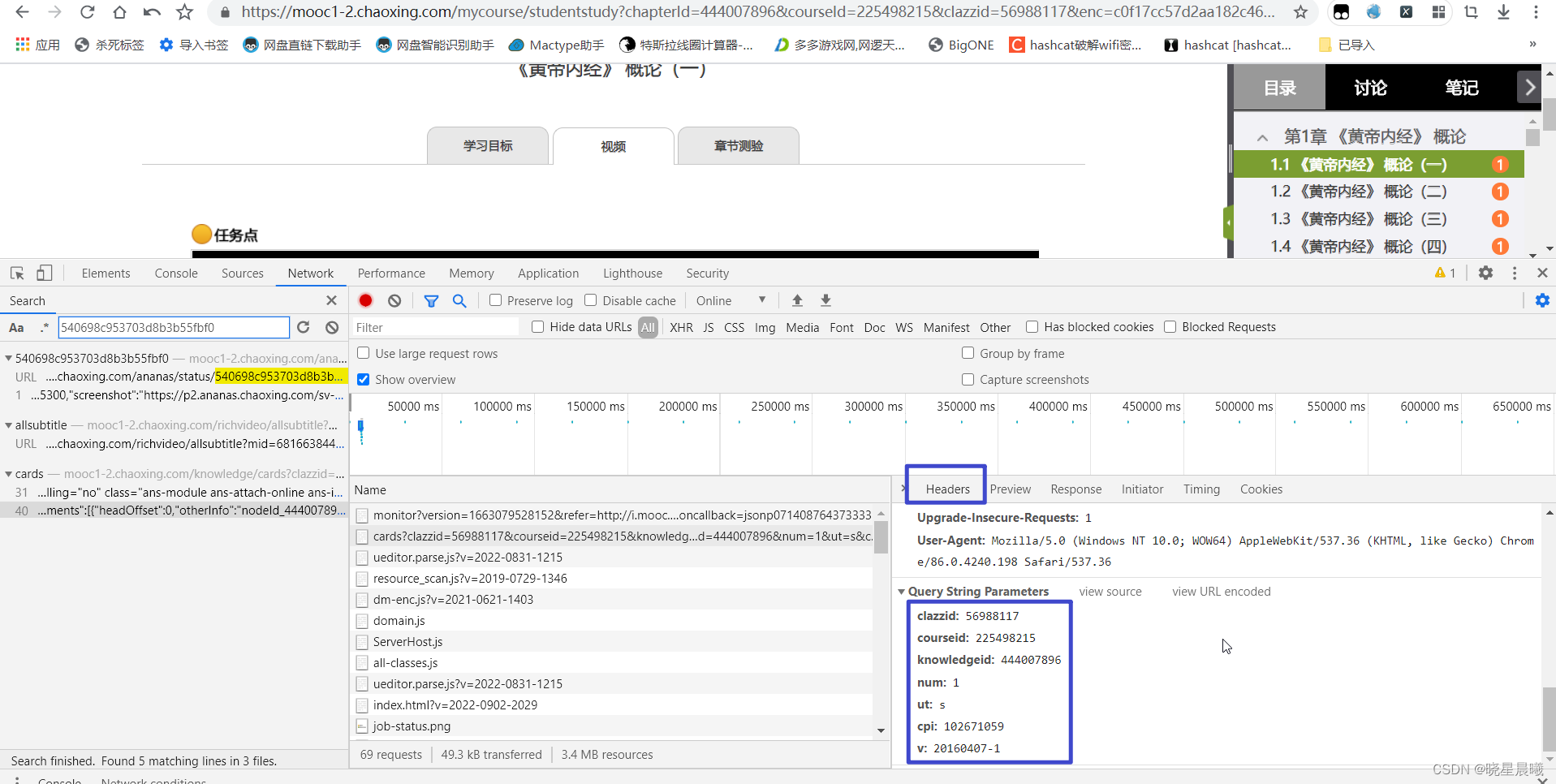
通过查看header,会发现不需要enc,对吧,也就是有classid,courseid,knowledgeid,cpi。
而knowledgeid是什么呢?经过对比页面url可以发现,knowledgeid就是chapterId。OK,四则皆有,便可拿取objectId了
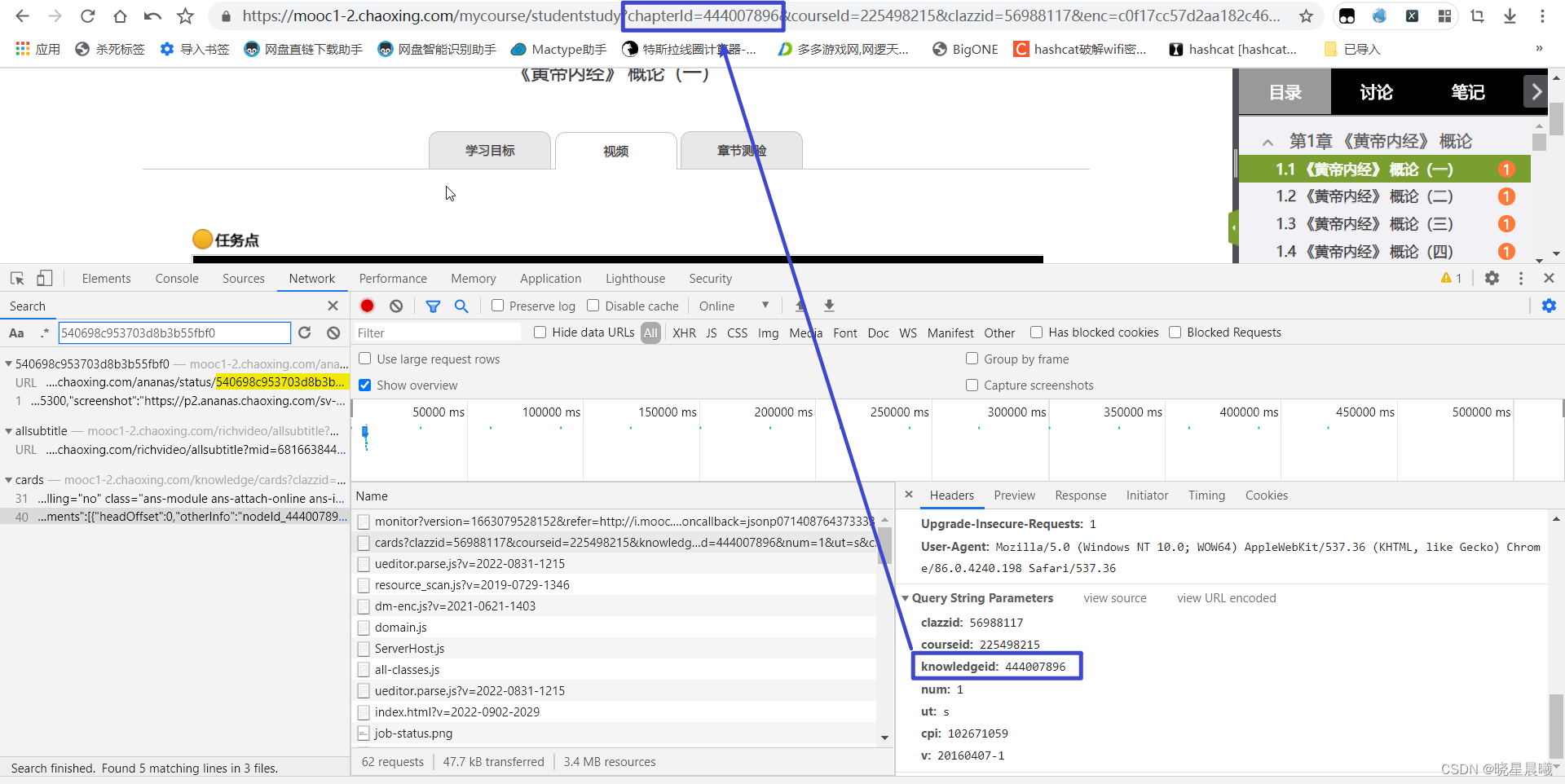
OK,python代码如下:
params3 = {
'courseid': '225498215',
'clazzid': '56988117',
'cpi': '102671059',
}
url = 'https://mooc1-2.chaoxing.com/visit/stucoursemiddle'
response3 = session.get(url=url, headers=headers, params=params3)
selector = parsel.Selector(response3.text)
h3s = selector.css('.clearfix a::attr(href)')
chapterIds = []
for h3 in h3s:
chapterId = re.findall('chapterId=(.*?)&', h3.get(), re.S)[0]
chapterIds.append(chapterId)
for chapterId in chapterIds:
url4 = 'https://mooc1-2.chaoxing.com/knowledge/cards'
params3['knowledgeid'] = chapterId
response4 = session.get(url=url4, headers=headers, params=params3)
objectId = re.findall('"objectid":"(.*?)",', response4.text, re.S)
print(objectId)
运行后,报错了,其实跟一个字段有关就是num,这边要为1,因为第一个。各位可以研究一下。
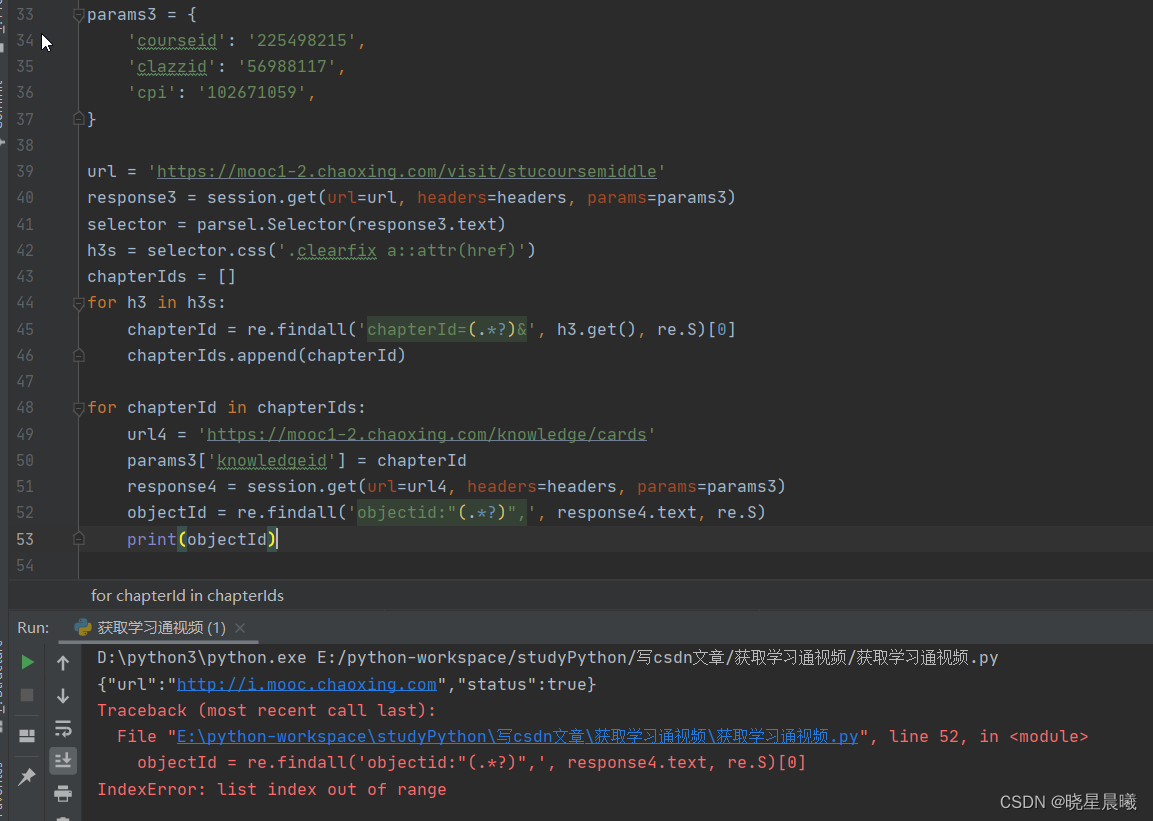
再次获取,结果出现了这个,针对这个,其实可以再进行一次登录。因为进行验证,反倒有些时候无法解决问题,亲测~
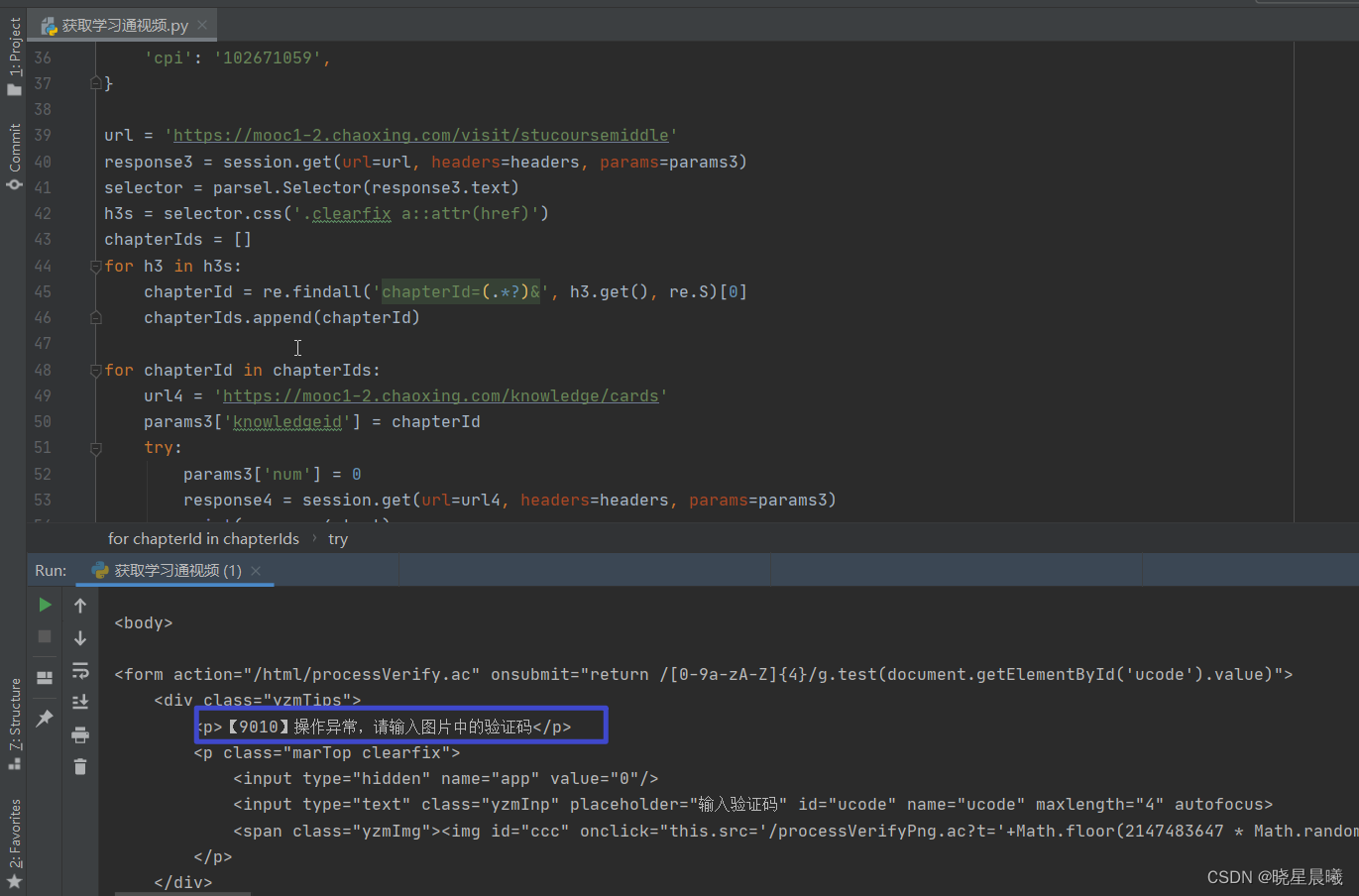
所以这边登录,写成一个方法,建议其他请求也如此,方便重新请求

OK,更改及加上判断后,python代码如下:
为了写文章,所以代码很粗糙,可以改进的,就是写成方法
params3 = {
'courseid': '225498215',
'clazzid': '56988117',
'cpi': '102671059',
}
url = 'https://mooc1-2.chaoxing.com/visit/stucoursemiddle'
response3 = session.get(url=url, headers=headers, params=params3)
selector = parsel.Selector(response3.text)
h3s = selector.css('.clearfix .articlename a::attr(href)')
chapterIds = []
for h3 in h3s:
chapterId = re.findall('chapterId=(.*?)&', h3.get(), re.S)[0]
chapterIds.append(chapterId)
for chapterId in chapterIds:
url4 = 'https://mooc1-2.chaoxing.com/knowledge/cards'
params3['knowledgeid'] = chapterId
params3['num'] = 0
response4 = session.get(url=url4, headers=headers, params=params3)
objectId = re.findall('"objectid":"(.*?)",', response4.text, re.S)
if response4.url.find('Verify') != -1:
session = login()
response5 = session.get(url=url4, headers=headers, params=params3)
objectId = re.findall('"objectid":"(.*?)",', response5.text, re.S)
if objectId is None:
params3['num'] = 1
response5 = session.get(url=url4, headers=headers, params=params3)
objectId = re.findall('"objectid":"(.*?)",', response5.text, re.S)
print(objectId)
elif len(objectId) == 0:
params3['num'] = 1
response5 = session.get(url=url4, headers=headers, params=params3)
objectId = re.findall('"objectid":"(.*?)",', response5.text, re.S)
print(objectId)
else:
print(objectId)
运行结果如图,为啥最后两个是空的呢?因为这二者都无视频。
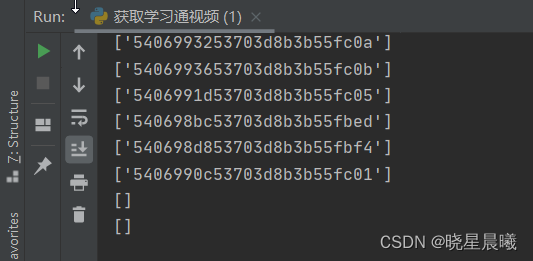
OK,咱既然获取到了objectId,也知道了其的作用,那么开始获取具有视频的json数据吧。
也就是这个请求地址
https://mooc1-2.chaoxing.com/ananas/status/(这里为objectId)?k=1366&flag=normal&_dc=1663085022768
获取视频url
OK,咱发送上面的url,运行结果如下:
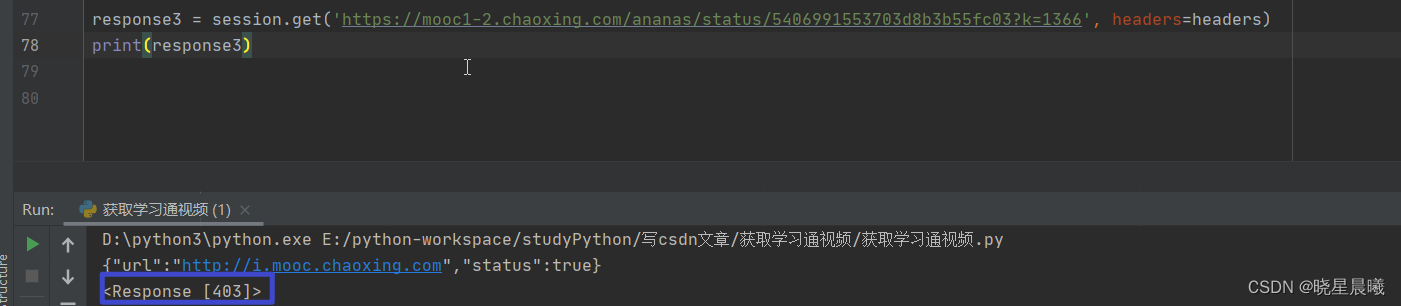
好家伙,报403,这是为啥呢?初步判断是因为headers,因为之前也遇到类似情况嘛。
headers 加个referer
{
'referer': 'https://www.baidu.com',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36'
}
然后再次发送请求,成功获取

http是SD的清晰度,httphd是HD的清晰度。
这边以http为例,得到如下url
https://s1.ananas.chaoxing.com/video/45/5406991553703d8b3b55fc03/sd.mp4?at_=1663089014072&ak_=1ede9d47bbf858bcb851148111eb35f7&ad_=e1b8a6bfa81e0a8dd2c827fbf23e26cc
进行请求,输出如下:
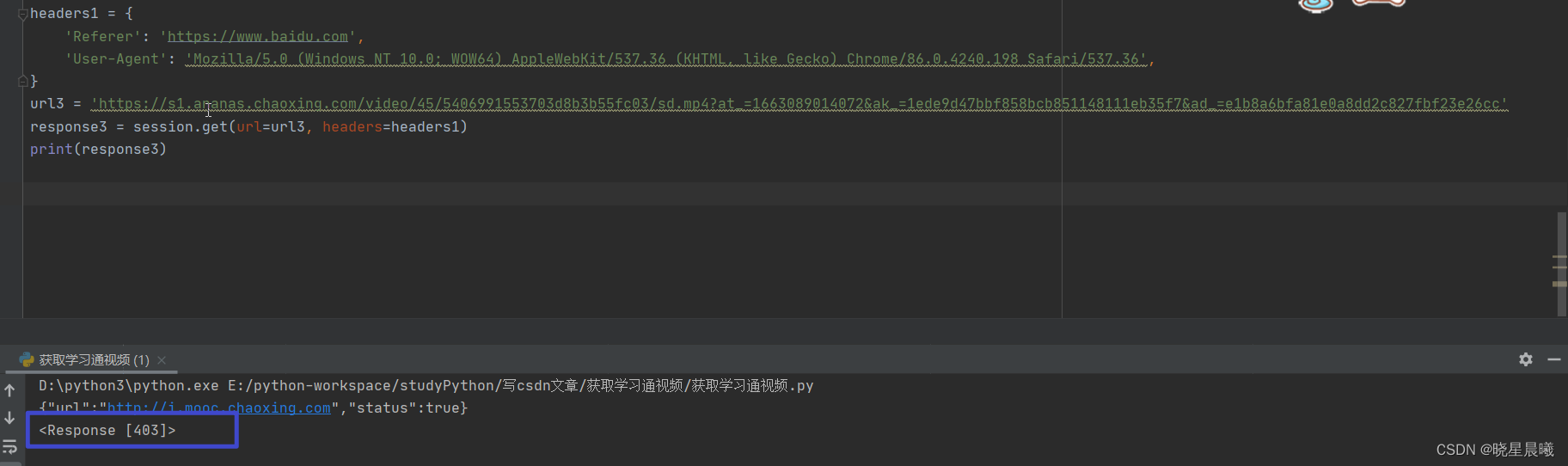
阿嘞,403,但是把这个地址,用迅雷下载,发现可以下载。也就是说明,哪里有问题了。
经过研究,把referer改动一下(改成学习通自个的)就请求成功了,也就说明,咱可以保存视频了
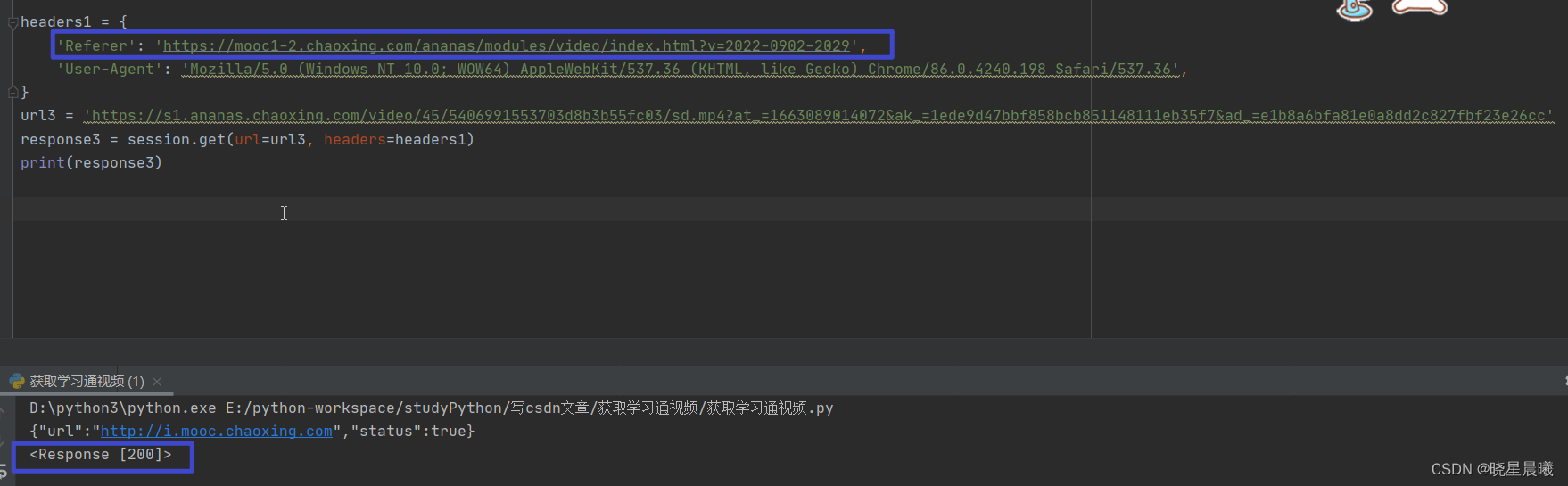
emmmm,保存视频,无非就是with open。这边就不演示了。
OK,差不多就是这样。如何一条龙服务,就交给各位看官自己操作了喽。
最后,感谢您的阅读我的文章,感恩!如有什么不足或问题,请评论或私信告知!谢谢了喽~

 浙公网安备 33010602011771号
浙公网安备 33010602011771号