
解读:Hadoop Archive
hdfs并不擅长存储小文件,因为每个文件最少一个block,每个block的元数据都会在NameNode中占用150byte内存。如果存储大量的小文件,它们会吃掉NameNode节点的大量内存。MR案例:小文件处理方案
Hadoop Archive或者HAR,是一个高效地将小文件放入HDFS块中的文件存档工具。它能将多个小文件打包成一个HAR文件,这样在减少NameNode内存使用的同时,仍然允许对小文件进行透明的访问,比如作为MapReduce的输入。
使用方法:
1). 归档前的目录结构
[root@ncst mapreduce]# hadoop fs -lsr /test/in drwxr-xr-x - root supergroup 0 2015-08-26 02:35 /test/in/har drwxr-xr-x - root supergroup 0 2015-08-22 12:02 /test/in/mapjoin -rw-r--r-- 1 root supergroup 39 2015-08-22 12:02 /test/in/mapjoin/address.txt -rw-r--r-- 1 root supergroup 129 2015-08-22 12:02 /test/in/mapjoin/company.txt drwxr-xr-x - root supergroup 0 2015-08-25 22:27 /test/in/small -rw-r--r-- 1 root supergroup 1 2015-08-25 22:17 /test/in/small/small.1 -rw-r--r-- 1 root supergroup 1 2015-08-25 22:17 /test/in/small/small.2 -rw-r--r-- 1 root supergroup 1 2015-08-25 22:17 /test/in/small/small.3 -rw-r--r-- 1 root supergroup 3 2015-08-25 22:27 /test/in/small/small_data
2). 归档命令
可以通过参数 -D har.block.size 指定HAR的大小
shell> hadoop archive -archiveName NAME -p <parent path> <src>* <dest>
/* 归档命令
* -archiveName 0825.har : 指定归档后的文件名
* -p /test/in/ : 被归档文件所在的父目录
* small mapjoin : 要被归档的目录,一至多个(small和mapjoin)
* /test/in/har : 生成的归档文件存储目录
*/
hadoop archive -archiveName 0825.har -p /test/in/ small mapjoin /test/in/har
3). 归档后的目录结构
[root@ncst ~]# hadoop fs -lsr /test/in drwxr-xr-x - root supergroup 0 2015-08-26 02:56 /test/in/har drwxr-xr-x - root supergroup 0 2015-08-26 02:56 /test/in/har/0825.har -rw-r--r-- 1 root supergroup 0 2015-08-26 02:56 /test/in/har/0825.har/_SUCCESS -rw-r--r-- 5 root supergroup 665 2015-08-26 02:56 /test/in/har/0825.har/_index -rw-r--r-- 5 root supergroup 23 2015-08-26 02:56 /test/in/har/0825.har/_masterindex -rw-r--r-- 1 root supergroup 174 2015-08-26 02:56 /test/in/har/0825.har/part-0 drwxr-xr-x - root supergroup 0 2015-08-22 12:02 /test/in/mapjoin -rw-r--r-- 1 root supergroup 39 2015-08-22 12:02 /test/in/mapjoin/address.txt -rw-r--r-- 1 root supergroup 129 2015-08-22 12:02 /test/in/mapjoin/company.txt drwxr-xr-x - root supergroup 0 2015-08-25 22:27 /test/in/small -rw-r--r-- 1 root supergroup 1 2015-08-25 22:17 /test/in/small/small.1 -rw-r--r-- 1 root supergroup 1 2015-08-25 22:17 /test/in/small/small.2 -rw-r--r-- 1 root supergroup 1 2015-08-25 22:17 /test/in/small/small.3 -rw-r--r-- 1 root supergroup 3 2015-08-25 22:27 /test/in/small/small_data
4). 查看结果文件【part-0】内容
[root@ncst ~]# hadoop fs -cat /test/in/har/0825.har/part-0 1231231 Beijing 2 Guangzhou 3 Shenzhen 4 XianBeijing Red Star 1 Shenzhen Thunder 3 Guangzhou Honda 2 Beijing Rising 1 Guangzhou Development Bank 2 Tencent 3
5). 使用har uri去访问原始数据
HAR是HDFS之上的一个文件系统,因此所有 fs shell 命令对HAR文件均可用,只不过文件路径格式不一样
[root@ncst ~]# hadoop fs -lsr har:///test/in/har/0825.har drwxr-xr-x - root supergroup 0 2015-08-22 12:02 har:///test/in/har/0825.har/mapjoin -rw-r--r-- 1 root supergroup 39 2015-08-22 12:02 har:///test/in/har/0825.har/mapjoin/address.txt -rw-r--r-- 1 root supergroup 129 2015-08-22 12:02 har:///test/in/har/0825.har/mapjoin/company.txt drwxr-xr-x - root supergroup 0 2015-08-25 22:27 har:///test/in/har/0825.har/small -rw-r--r-- 1 root supergroup 1 2015-08-25 22:17 har:///test/in/har/0825.har/small/small.1 -rw-r--r-- 1 root supergroup 1 2015-08-25 22:17 har:///test/in/har/0825.har/small/small.2 -rw-r--r-- 1 root supergroup 1 2015-08-25 22:17 har:///test/in/har/0825.har/small/small.3 -rw-r--r-- 1 root supergroup 3 2015-08-25 22:27 har:///test/in/har/0825.har/small/small_data
6). 用har uri访问下一级目录
[root@ncst ~]# hdfs dfs -lsr har:///test/in/har/0825.har/small -rw-r--r-- 1 root supergroup 1 2015-08-25 22:17 har:///test/in/har/0825.har/small/small.1 -rw-r--r-- 1 root supergroup 1 2015-08-25 22:17 har:///test/in/har/0825.har/small/small.2 -rw-r--r-- 1 root supergroup 1 2015-08-25 22:17 har:///test/in/har/0825.har/small/small.3 -rw-r--r-- 1 root supergroup 3 2015-08-25 22:27 har:///test/in/har/0825.har/small/small_data
7). 远程访问,可以使用以下命令
//hdfs-ncst:9000 其中,ncst是NameNode所在节点的HostName [root@ncst ~]# hadoop fs -lsr har://hdfs-ncst:9000/test/in/har/small.har lsr: DEPRECATED: Please use 'ls -R' instead. drwxr-xr-x - root supergroup 0 2015-08-25 22:27 har://hdfs-ncst:9000/test/in/har/small.har/small -rw-r--r-- 1 root supergroup 1 2015-08-25 22:17 har://hdfs-ncst:9000/test/in/har/small.har/small/small.1 -rw-r--r-- 1 root supergroup 1 2015-08-25 22:17 har://hdfs-ncst:9000/test/in/har/small.har/small/small.2 -rw-r--r-- 1 root supergroup 1 2015-08-25 22:17 har://hdfs-ncst:9000/test/in/har/small.har/small/small.3 -rw-r--r-- 1 root supergroup 3 2015-08-25 22:27 har://hdfs-ncst:9000/test/in/har/small.har/small/small_data
8)删除har文件必须使用rmr命令,rm是不行的
[root@ncst ~]# hadoop fs -rmr /test/in/har/0825.har
9). 使用HAR作为MapReduce的输入
[root@ncst ~]# hadoop jar /***/hadoop-mapreduce-examples-2.2.0.jar wordcount \
> har:///test/in/har/0825.har/mapjoin //输入路径
> /test/out/0825/05 //输出路径
存在的问题:
- 存档文件的源文件及目录都不会自动删除,需要手动删除
- 存档过程实际是一个MapReduce过程,所以需要hadoop的MapReduce支持
- 存档文件本身不支持压缩
- 存档文件一旦创建便不可修改,要想从中删除或增加文件,必须重新建立存档文件
- 创建存档文件会创建原始文件的副本,所以至少需要有与存档文件容量相同的磁盘空间
- 使用 HAR 作为MR的输入,MR可以访问其中所有的文件。但是由于InputFormat不会意识到这是个归档文件,也就不会有意识的将多个文件划分到单独的Input-Split中,所以依然是按照多个小文件来进行处理,效率依然不高
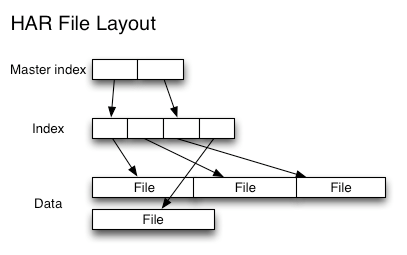
- HAR结构:二级索引

 浙公网安备 33010602011771号
浙公网安备 33010602011771号