
MR案例:倒排索引
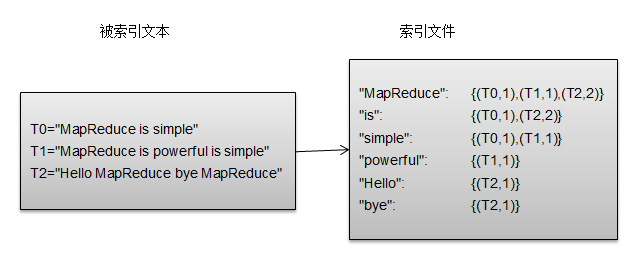
1.map阶段:将单词和URI组成Key值(如“MapReduce :1.txt”),将词频作为value。
利用MR框架自带的Map端排序,将同一文档的相同单词的词频组成列表,传递给Combine过程,实现类似于WordCount的功能。
Class Map<Longwritable, Text, Text, Longwritable>{
method map(){
//获取输入分片对应的文件名
String fileName=((FileSplit)context.getInputSplit()).getPath().getName();
for(String word : value.split()){
//输出:<key,value>---<"MapReduce:1.txt",1>
context.write(new Text(word+":"+fileName), new Longwritable(1))
}
}
}
2.Combiner阶段:将key值相同的value值累加,得到一个单词在文档中的词频。
如果直接将Map的输出作为Reduce的输入,当前key值(由单词、URI组成)无法保证相同的word会分发到同一个Reduce处理,所以必须修改key值和value值。将单词作为key值,URI和词频作为value值,可以利用MR框架默认的HashPartitioner类完成分区过程,将相同单词的所有记录发送给同一个Reducer处理。
Class Combine<Text, Longwritable, Text, Text>{
method reduce(){
for(Long long : v2s){
//词频求和
sum += Long.parseLong(long.toString());
}
//输出:<key,value>----<"Mapreduce","0.txt:2">
context.write(new Text(word), new Text(fileName+":"+sum));
}
}
3.reduce阶段:将相同key值的value值组合成倒排索引文件所需的格式即可。
Class Reduce<Text, Longwritable, Text, Text>{
method reduce(){
String valueList = new String();
//输入:<"MapReduce",list("0.txt:1","1.txt:1","2.txt:1")>
for(Text text : v2s){
valueList += text.toString()+";";
}
//输出:<"MapReduce","0.txt:1,1.txt:1,2.txt:1">
context.write(key, new Text(valueList));
}
}
注意事项:本实例设计的倒排索引在文件数目上没有限制,但是单词文件不宜过大,要保证每个文件对应一个 split。否则,由于 Reduce 过程没有进一步统计词频,最终结果可能会出现词频未统计完全的单词。详见MR案例:倒排索引 && MultipleInputs
解决方案:
- 覆写 InputFormat 类将每个输入文件分为一个 split,避免上述情况。
- 执行两次 MR 任务,第一次 MR 用于统计词频,第二次 MR 用于生成倒排索引。
- 可以利用复合键值对等实现包含更多信息的倒排索引。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号