
Keras学习
1. 回归


import numpy as np from keras.models import Sequential from keras.layers import Dense import matplotlib.pyplot as plt np.random.seed(2018) #构造数据 X=np.linspace(-1,1,200) np.random.shuffle(X) Y=0.5*X+2+np.random.normal(0,0.05,X.shape) N=160 X_train,Y_train=X[:N],Y[:N] X_test,Y_test=X[N:],Y[N:] #构建模型 model=Sequential() model.add(Dense(output_dim=1,input_dim=1)) #损失函数和优化器选择 model.compile(loss='mse',optimizer='sgd') for i in range(301): cost=model.train_on_batch(X_train,Y_train) if i%100==0: print("Train cost:",cost) cost=model.evaluate(X_test,Y_test) print("Test cost:",cost) w,b=model.layers[0].get_weights() print("Weights:",w,"Bias:",b) Y_pred=model.predict(X_test) plt.scatter(X_test,Y_test) plt.plot(X_test,Y_pred,color='r') plt.show()

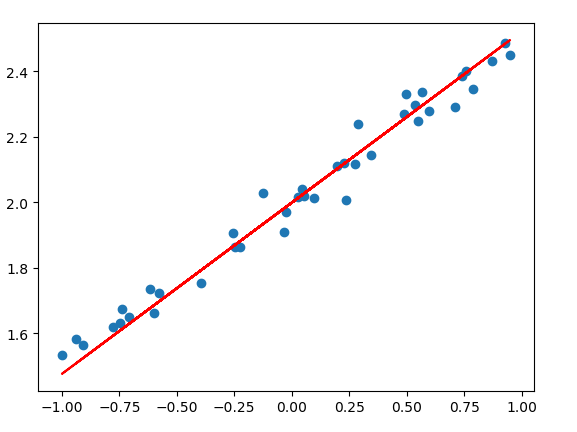
2. 分类
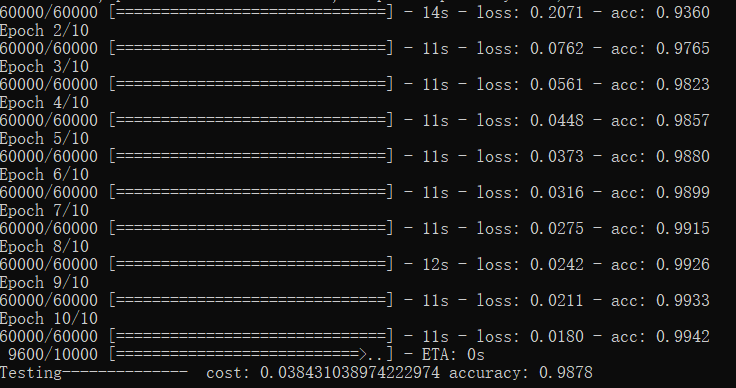
from keras.datasets import mnist from keras.utils import np_utils from keras.models import Sequential from keras.layers import Dense,Activation (X_train,Y_train),(X_test,Y_test)=mnist.load_data() print("(X_train,Y_train),(X_test,Y_test):", X_train.shape,Y_train.shape,X_test.shape,Y_test.shape) X_train,X_test=X_train.reshape(X_train.shape[0],-1)/255,X_test.reshape(X_test.shape[0],-1)/255 #一定要归一化,不然最后很可能不收敛! Y_train,Y_test=np_utils.to_categorical(Y_train,nb_classes=10),np_utils.to_categorical(Y_test,nb_classes=10) print("(X_train,Y_train),(X_test,Y_test):", X_train.shape,Y_train.shape,X_test.shape,Y_test.shape) model=Sequential() model.add(Dense(output_dim=32,input_dim=X_train.shape[1])) model.add(Activation('relu')) model.add(Dense(10)) model.add(Activation('softmax')) model.compile(#optimizer=Adade, optimizer='adadelta', loss='categorical_crossentropy', metrics=['accuracy']) ################################Training..............############################################ epoch=10 batchsize=32 N_train=X_train.shape[0] N_test=X_test.shape[0] def get_batch(j,batchsize,N,X,Y): start_index,end_index=j*batchsize,j*batchsize+batchsize if end_index>N: end_index=N return X[start_index:end_index,:],Y[start_index:end_index,:] for i in range(epoch): for j in range(N_train//batchsize): X_batch,Y_batch=get_batch(j,batchsize,N_train,X_train,Y_train) # print('X_batch,Y_batch:',X_batch.shape,Y_batch.shape) cost,accuracy= model.train_on_batch(X_batch,Y_batch) if j%100==0: print('Trainging-------epoch:',i,' batch:', j, 'loss:',cost,' accuracy:',accuracy) # print('Trainging-------epoch:', i, ' loss:', cost) loss, accuracy =model.evaluate(X_test,Y_test) print('Testing------- loss:',loss,' accuracy:',accuracy) #################################################################################################### #或者直接用下面的keras的训练模型 # model.fit(X_train,Y_train) # loss, accuracy =model.evaluate(X_test,Y_test) # print('Testing------- loss:',loss,' accuracy:',accuracy)
Testing------- loss: 0.1500041989080608 accuracy: 0.9558
3.CNN分类
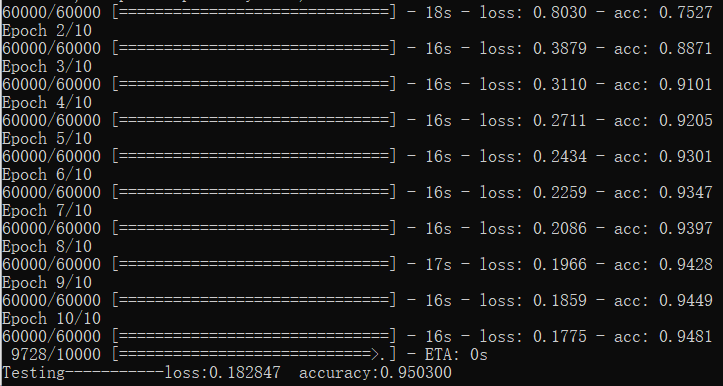
from keras.datasets import mnist from keras.models import Sequential from keras.utils import np_utils from keras.layers import Dense,Activation,Convolution2D,MaxPooling2D,Flatten (X_train,Y_train),(X_test,Y_test)=mnist.load_data() X_train,X_test=X_train.reshape(-1,1,28,28)/255,X_test.reshape(-1,1,28,28)/255 Y_train,Y_test=np_utils.to_categorical(Y_train,nb_classes=10),np_utils.to_categorical(Y_test,nb_classes=10) model=Sequential() model.add(Convolution2D(nb_filter=32,nb_row=5,nb_col=5,border_mode='same',input_shape=X_train.shape[1:])) model.add(Activation('relu')) model.add(MaxPooling2D(pool_size=(2,2),strides=(2,2),border_mode='same')) model.add(Convolution2D(64,5,5,border_mode='same')) model.add(Activation('relu')) model.add(MaxPooling2D((2,2),(2,2),'same')) model.add(Flatten()) model.add(Dense(1024)) model.add(Activation('relu')) model.add(Dense(10)) model.add(Activation('softmax')) model.compile(optimizer='adadelta', loss='categorical_crossentropy', metrics=['accuracy']) ################################Training..............############################################ def get_batch(j,batchsize,N,X,Y): start_index,end_index=j*batchsize,j*batchsize+batchsize if end_index>N: end_index=N return X[start_index:end_index,:],Y[start_index:end_index,:] def my_model_fit(X_train,Y_train,epoch=10,batchsize=32): N_train = X_train.shape[0] for i in range(epoch): for j in range(N_train//batchsize): X_batch,Y_batch=get_batch(j,batchsize,N_train,X_train,Y_train) # print('X_batch,Y_batch:',X_batch.shape,Y_batch.shape) cost,accuracy= model.train_on_batch(X_batch,Y_batch) if j%100==0: print('Training-------epoch:',i,' batch:', j, 'loss:',cost,' accuracy:',accuracy) # print('Trainging-------epoch:', i, ' loss:', cost) #################################################################################################### # my_model_fit(X_train,Y_train) model.fit(X_train,Y_train) cost,accuracy=model.evaluate(X_test,Y_test) print('\nTesting-------------- cost:',cost,'accuracy:',accuracy)
4.RNN和LSTM分类
from keras.models import Sequential from keras.datasets import mnist from keras.utils import np_utils from keras.layers import Activation,SimpleRNN,Dense (X_train,Y_train),(X_test,Y_test)=mnist.load_data() print('(X_train,Y_train),(X_test,Y_test)',X_train.shape,Y_train.shape,X_test.shape,Y_test.shape) X_train,X_test=X_train.reshape(-1,28,28)/255,X_test.reshape(-1,28,28)/255 print('(X_train,Y_train),(X_test,Y_test)',X_train.shape,Y_train.shape,X_test.shape,Y_test.shape) Y_train,Y_test=np_utils.to_categorical(Y_train,nb_classes=10),np_utils.to_categorical(Y_test,nb_classes=10) N_hidden=50 N_out=50 bathsize=32 N_time=28 N_data_dimension=28 model=Sequential() model.add(SimpleRNN(output_dim=50, input_shape=(N_time,N_data_dimension))) model.add(Dense(10)) model.add(Activation('softmax')) model.compile(optimizer='adadelta', loss='categorical_crossentropy', metrics=['accuracy']) model.fit(X_train,Y_train) loss,accuracy=model.evaluate(X_test,Y_test) print("\nTesting-----------loss:%f accuracy:%f"%(loss,accuracy))
RNN结果: LSTM结果:

5. Autoencoder自编码
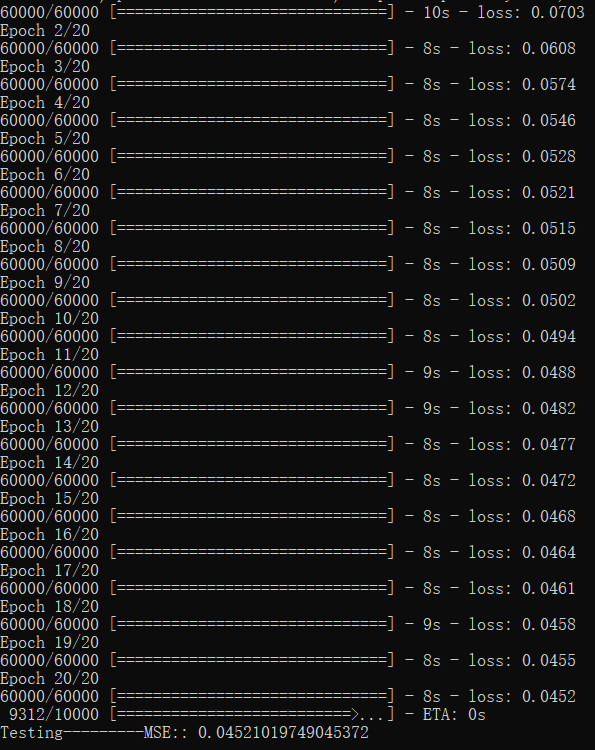
from keras.models import Model from keras.datasets import mnist from keras.utils import np_utils from keras.layers import Input,Activation,Dense import matplotlib.pyplot as plt import numpy as np np.random.seed(2018) (X_train,_),(X_test,Y_test)=mnist.load_data() X_train,X_test=X_train.reshape(-1,784)/255-0.5,X_test.reshape(-1,784)/255-0.5 N_1,N_2,N_3=128,64,4 inputs=Input(shape=(784,)) encoder=Dense(N_1,activation='relu')(inputs) encoder=Dense(N_2,activation='relu')(encoder) encoder=Dense(N_3,activation='relu')(encoder) encoder=Dense(2,activation='relu')(encoder) decoder=Dense(N_3,activation='relu')(encoder) decoder=Dense(N_2,activation='relu')(decoder) decoder=Dense(N_1,activation='relu')(decoder) decoder=Dense(784,activation='tanh')(decoder) Autoencoder=Model(input=inputs,output=decoder) Encoder=Model(input=inputs,output=encoder) Autoencoder.compile(optimizer='adadelta',loss='mse') Autoencoder.fit(X_train,X_train,nb_epoch=20) img_reduced=Encoder.predict(X_test) mse=Autoencoder.evaluate(X_test,X_test) print("\nTesting---------MSE::",mse) plt.scatter(img_reduced[:,0],img_reduced[:,1],c=Y_test) plt.show()

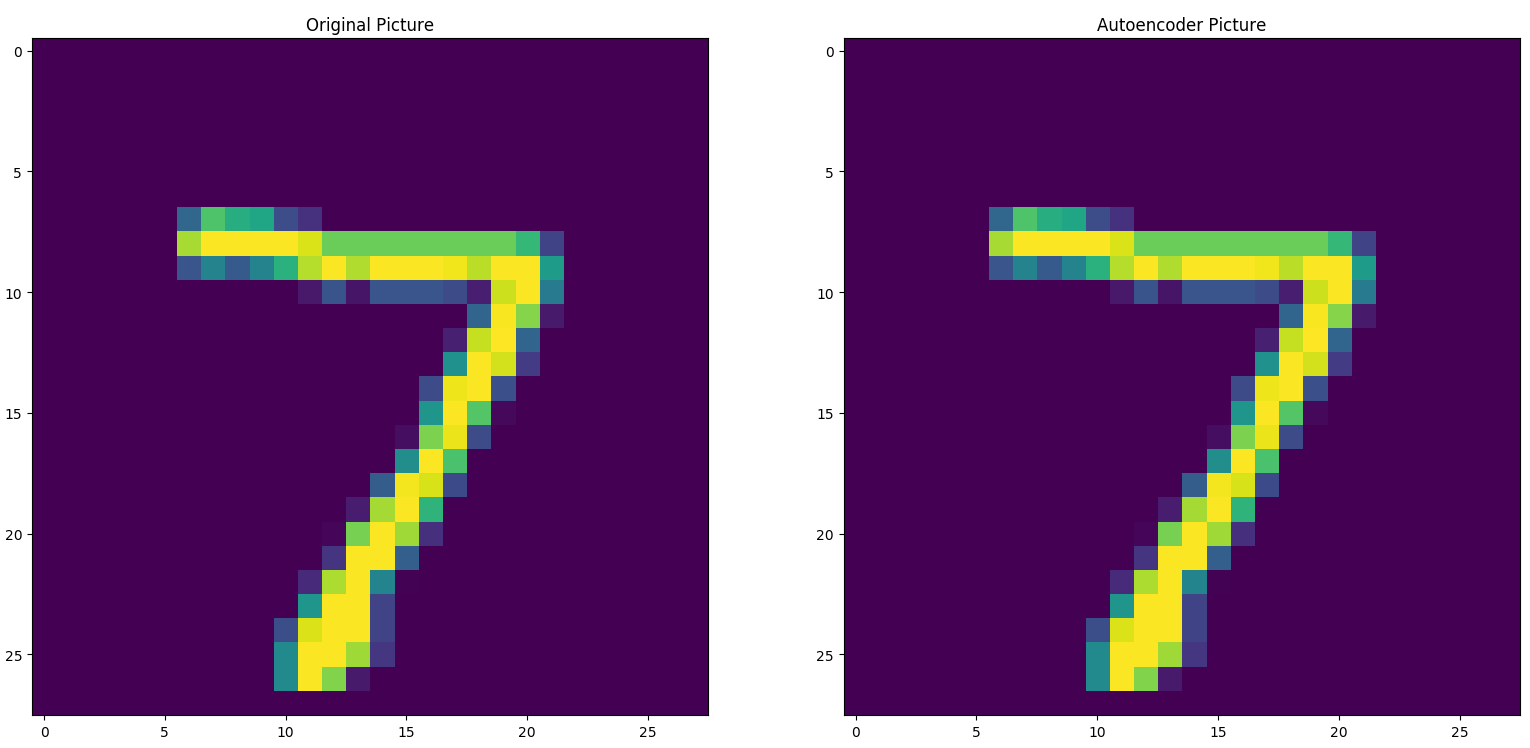
6. 模型存储
import numpy as np from keras.models import Sequential,load_model from keras.layers import Dense np.random.seed(2018) #构造数据 X=np.linspace(-1,1,200) np.random.shuffle(X) Y=0.5*X+2+np.random.normal(0,0.05,X.shape) N=160 X_train,Y_train=X[:N],Y[:N] X_test,Y_test=X[N:],Y[N:] #构建模型 model=Sequential() model.add(Dense(output_dim=1,input_dim=1)) #损失函数和优化器选择 model.compile(loss='mse',optimizer='sgd') for i in range(301): cost=model.train_on_batch(X_train,Y_train) if i%100==0: print("Train cost:",cost) cost=model.evaluate(X_test,Y_test,batch_size=40) print("Test cost:",cost) w,b=model.layers[0].get_weights() print("Weights:",w,"Bias:",b) Y_pred=model.predict(X_test[0:4]) print('Y_pred:',Y_pred) model.save('my_model.h5') del model model=load_model('my_model.h5') Y_pred=model.predict(X_test[0:4]) print('Y_pred:',Y_pred)
Key: from keras.models import load_model 和 h5数据格式

 浙公网安备 33010602011771号
浙公网安备 33010602011771号