
TinyBERT简单note
TinyBERT:
提出了一种基于Transformer架构的蒸馏方法(Transformer distillation)
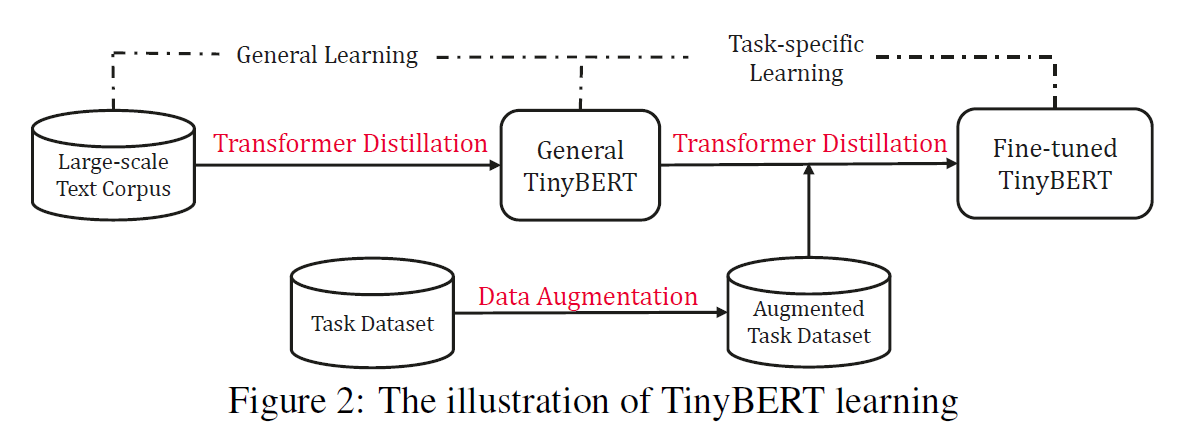
两阶段的框架,
a.预训练阶段 ( generaldistillation)
b.fine-tuning阶段 (task-specific distillation)
对Embedding,Attention,Prediction都做了知识蒸馏,主要对KQV的矩阵进行降维

知识蒸馏(KD)
目标是设计behavior函数f和loss函数L,从而让student网络尽可能好的能够学习到teacher网络的知识

Transformer distillation:
从图中我们可以看到M<N,所以我们希望student的层能够对应上teacher的抹一层,即找一个映射n=g(m). TinyBERT中同时考虑了Embedding和prediction这两层的压缩,即0 = g(0), N+1 = g(M+1). 形式上,我们需要最小化下面的目标函数
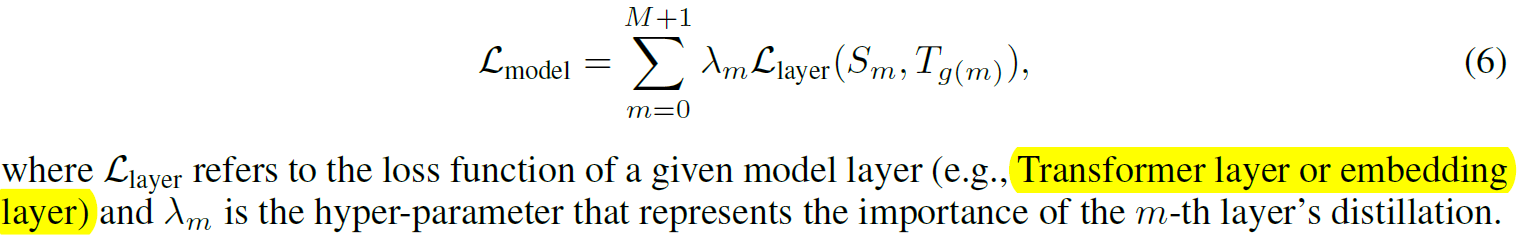
Attention loss
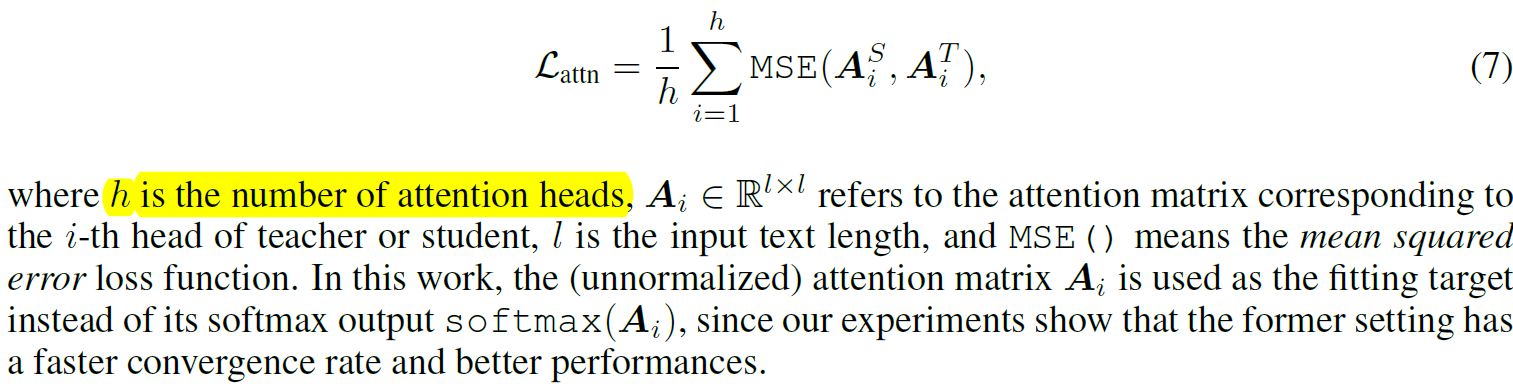
Hidden state loss

Embedding loss
Prediction loss

综上,我们可以得到以下loss
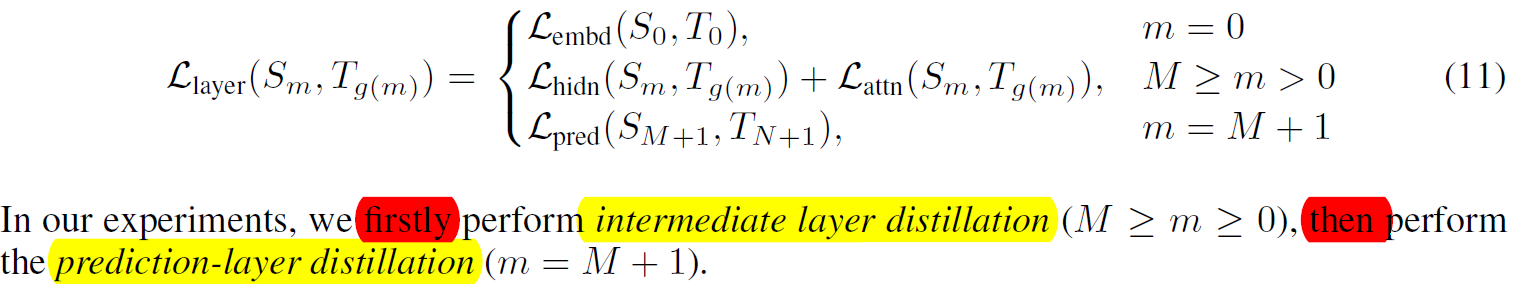
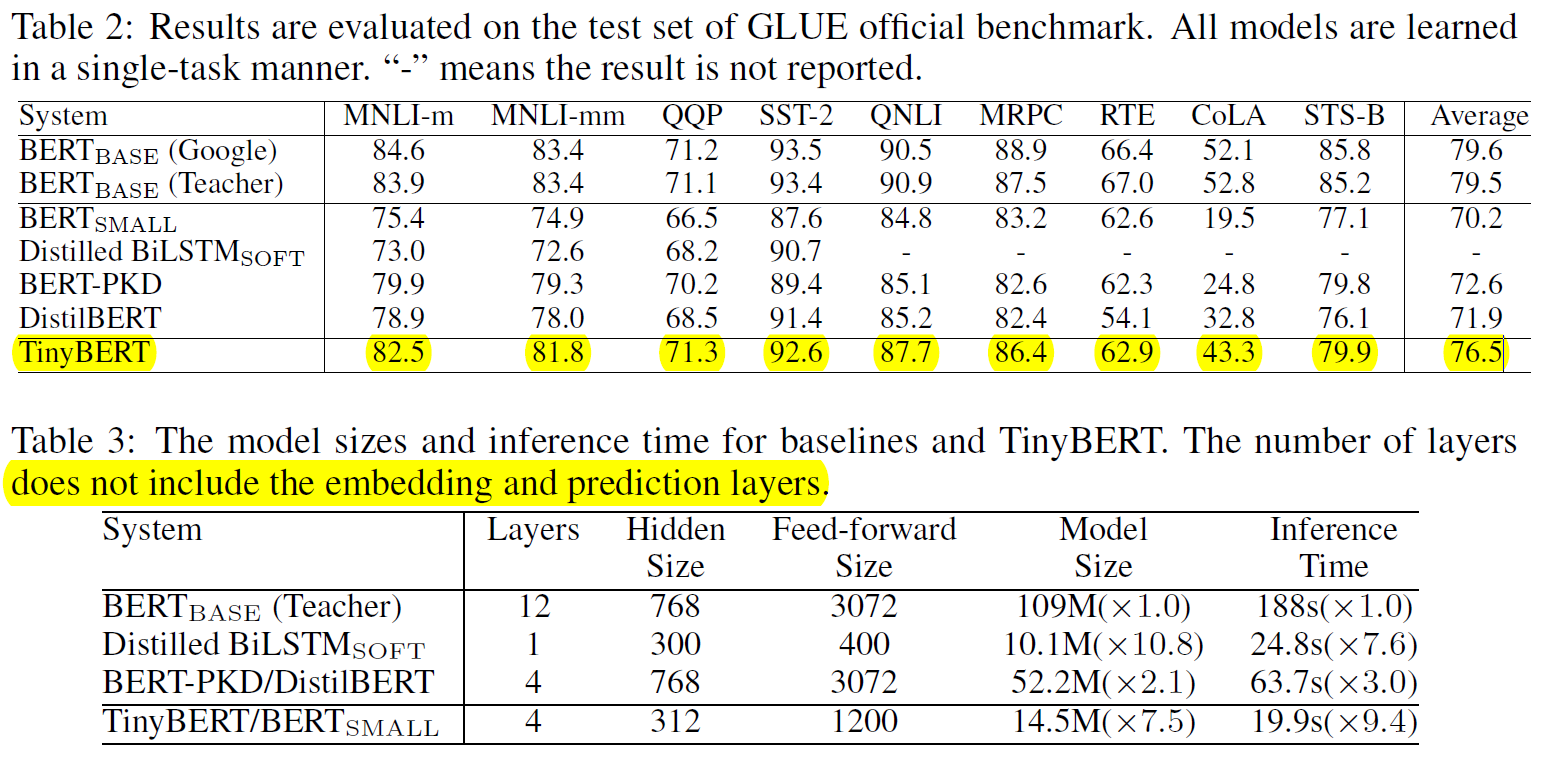
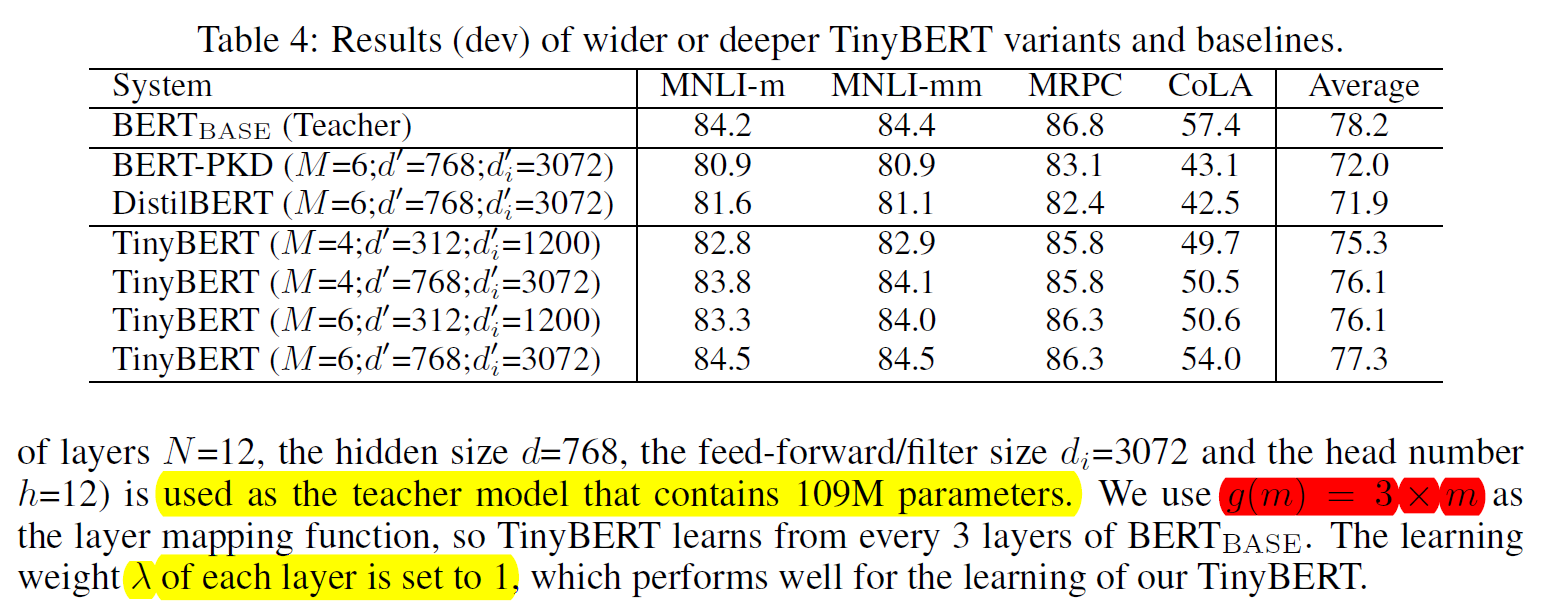
最后作者打榜的结果


 浙公网安备 33010602011771号
浙公网安备 33010602011771号