
ALBERT简单note
首先看下BERT和ALBERT模型的一些版本配置

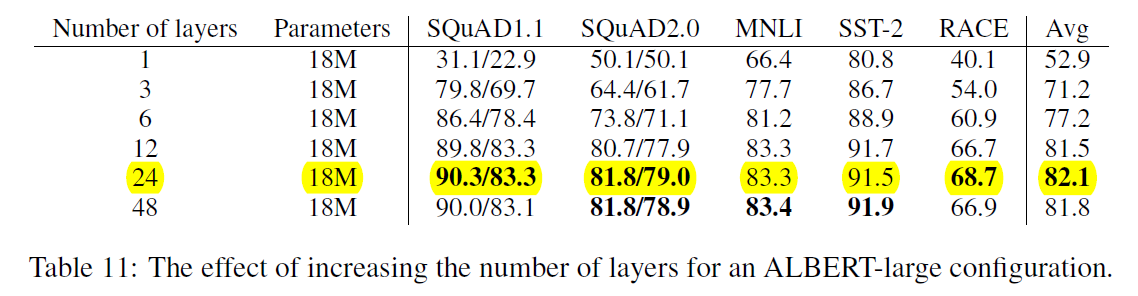
1. Layer个数和performance的关系:24层是个临界点,大于24后效果有下降趋势
2. 隐藏层节点数目和performance的关系:4096个是个临界点,大于4096后效果有下降趋势

3. 宽的ALBERT需要深的架构吗?作者的答案是:NO (但我觉得未必,只是Table里4096还不够宽,如果是1w甚至10w级别的,我想会需要深的)
ALBERT-large (H=1024) -- ALBERT-xxlarge (H=4096)

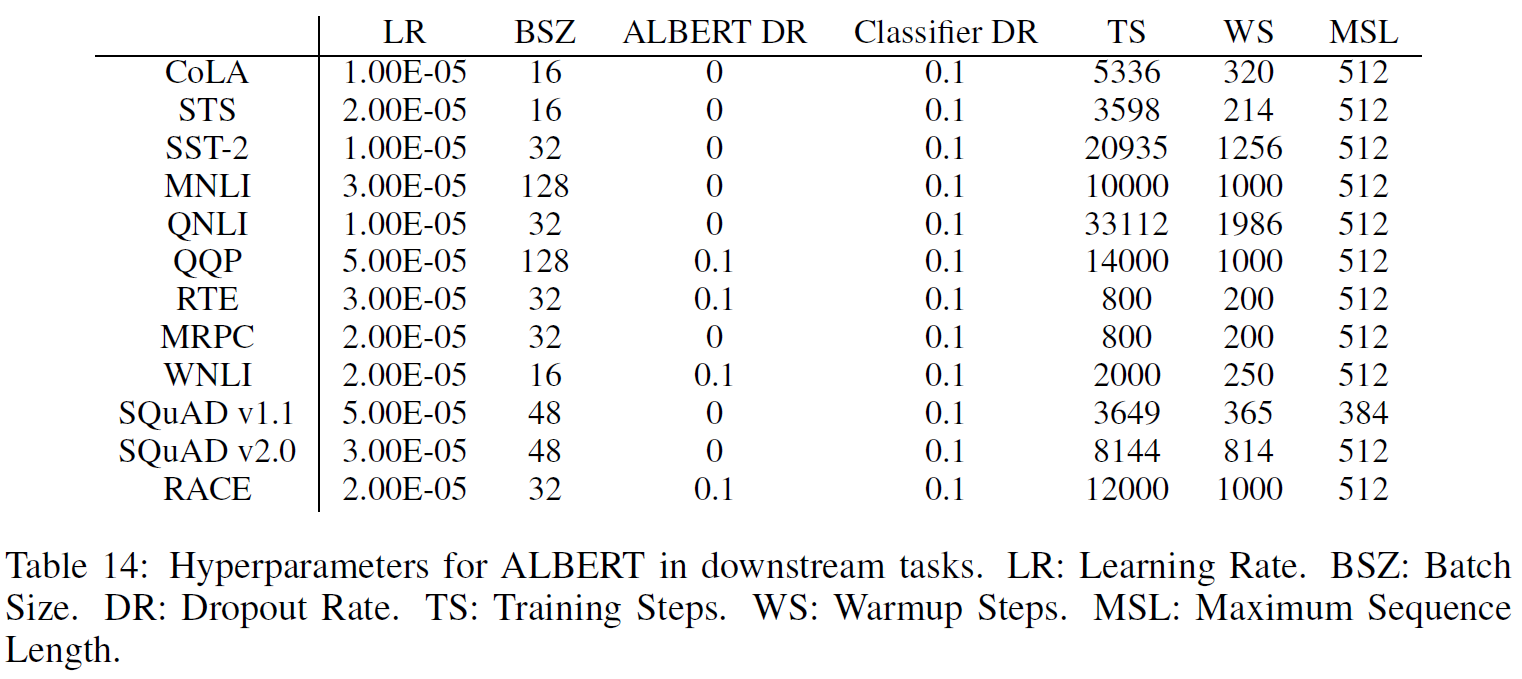
4.下游任务超参设置
Further 比较
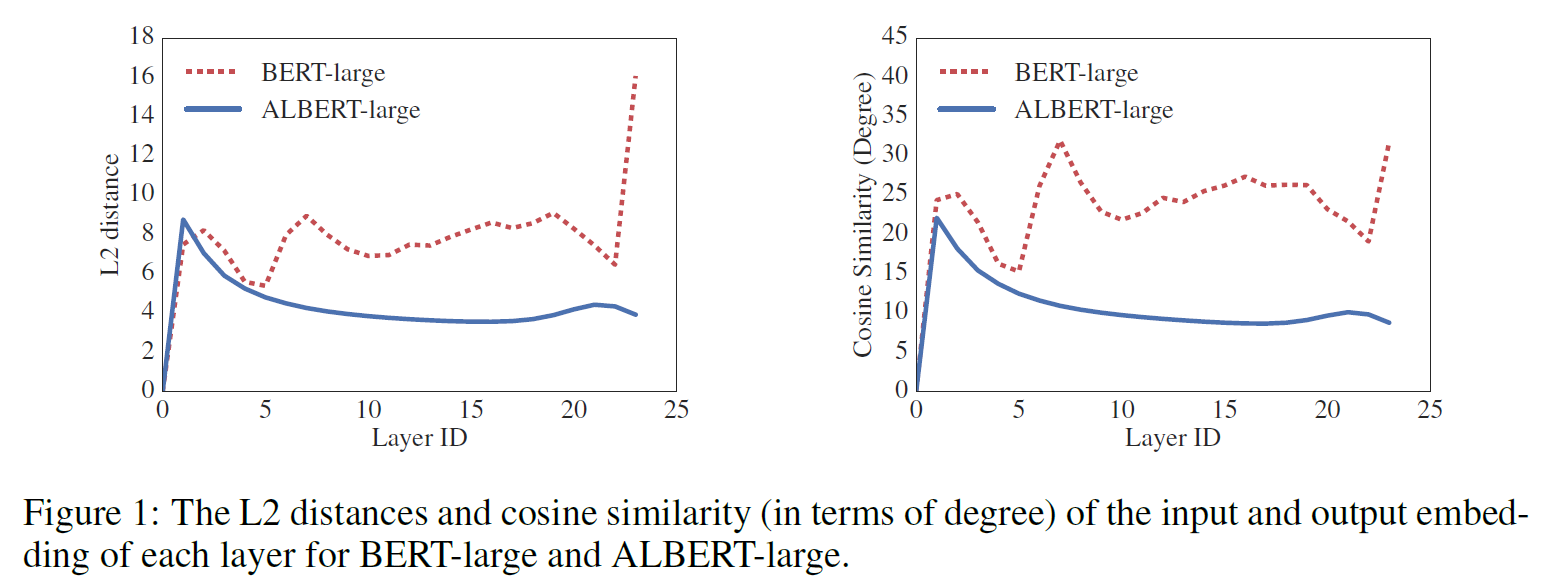
1. 可以看到Figure 1.中,每一层的输入和输出的相似度度量的变换是比较平滑的(蓝色),但是并没有趋于0,与Deep Equilibrium Model(DQE)有很大不同

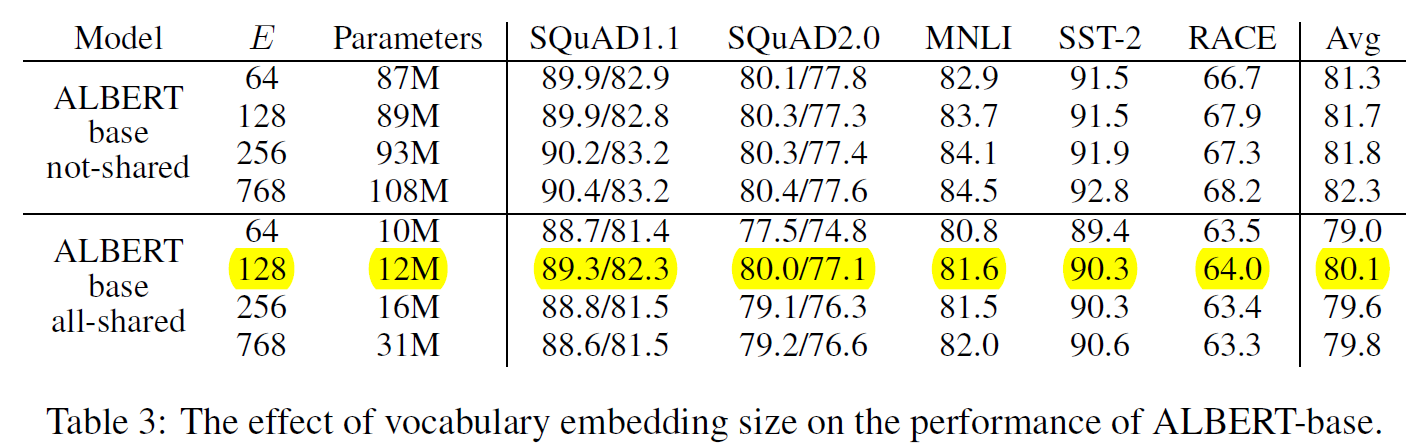
2. 词嵌入维度的影响:对于not-shared类型,随着E增加,效果提升,但作者认为效果提升不大。对于all-shared类型,E=128似乎是最好的。
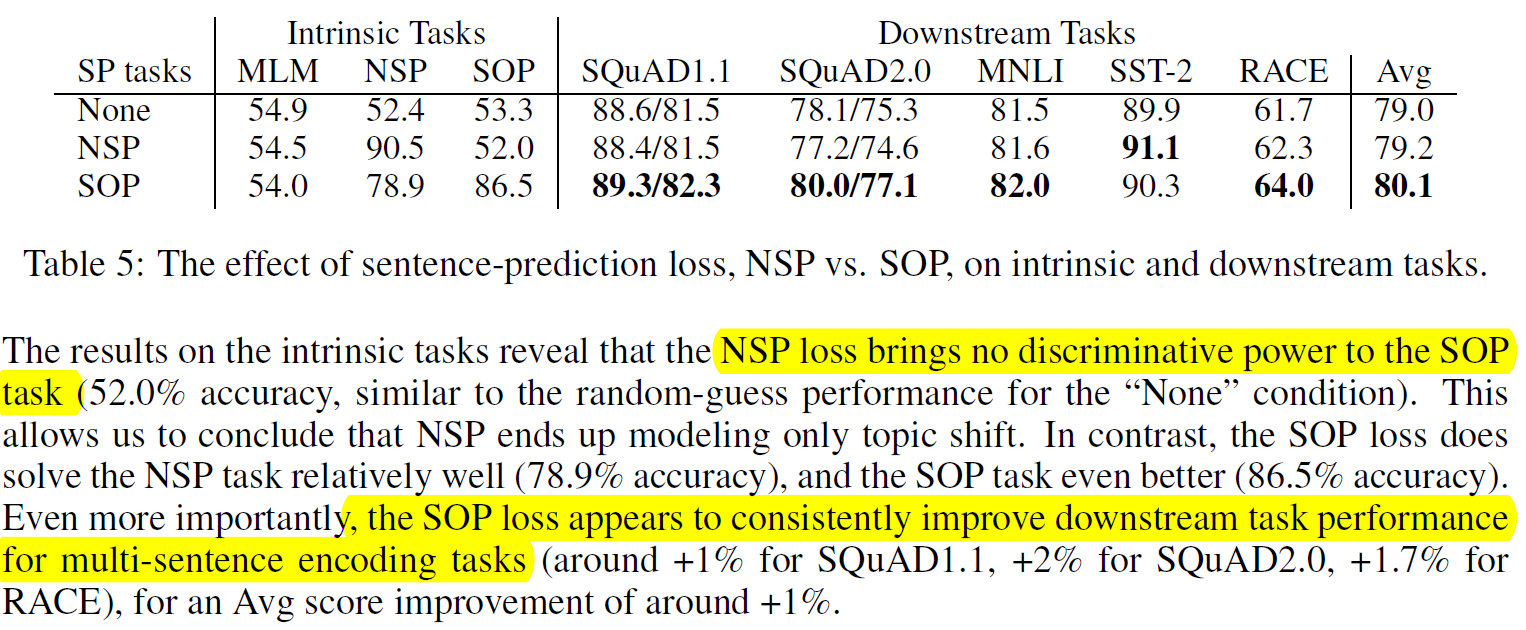
3. 不要用NSP了,还是用SOP吧

 浙公网安备 33010602011771号
浙公网安备 33010602011771号